share



新動画生成モデル「Gemini Omni」とは?料金や使い方、Veoとの違いを徹底解説!

2026年5月20日(日本時間)、Google I/O 2026で、新たな動画生成モデル「Gemini Omni」が発表されました。
Gemini Omniは、テキスト・画像・音声・動画を自由に組み合わせて入力できるマルチモーダルAIです。会話形式で指示を出すだけで、高品質な動画生成や編集を行えます。
とはいえ、「Gemini Omniで何ができるの?」「Veoとの違いがわからない」と感じている方も多いのではないでしょうか。
本記事では、Gemini Omniの特徴やできること、使い方、Veoとの違いをわかりやすく解説します。さらに、筆者が実際に試した生成事例も紹介しています。
Gemini Omniを活用して、これまで難しかった動画制作や映像編集を試してみてください。

監修者
SHIFT AI代表 木内翔大
SHIFT AIでは、生成AIやAIエージェントを日々の業務に活かしたい方に向けて、実務ですぐに使える資料を無料でプレゼントしています。どなたでも受け取れます。
たとえば『Claude Codeで始める業務自動化の教科書』『Claude Code コマンド大全』『AIエージェント用語集』など、明日からの業務にそのまま役立つ資料をご用意しています。
「AIエージェントを使って業務を効率化したい」「まず何から始めればいいか知りたい」という方は、ぜひ以下のボタンから受け取ってください。
Gemini Omniとは?Googleが発表した最新AI動画モデル
Gemini Omniとは、テキスト・画像・音声・動画を組み合わせて、高品質な動画を生成・編集できるGoogleの最新AIモデルです。
GoogleはGemini Omniを「世界モデル(World Model)」として位置づけています。物理法則や世界知識を理解したうえで、自然な映像を生成できる点が特徴です。
以下のように動画を生成できます。
Gemini OmniはGeminiアプリやYouTubeなど使い慣れたGoogleサービスからそのまま利用できるため、新しいツールを覚えるコストなく動画制作を始められます。
現時点では動画出力に対応しており、今後は画像・テキスト出力にも対応予定です。
Geminiの使い方がわからない方は以下の記事で使い方や活用事例を紹介しています。合わせてご覧ください。

Gemini Omniの特徴
Gemini Omniには、従来の動画生成AIにはない6つの特徴があります。
- 会話形式で直感的に動画を生成・編集できる
- テキスト・画像・音声・動画を自由に組み合わせて入力できる
- 物理法則と世界知識でリアルな映像を生成できる
- 複数回の編集でもキャラクターとシーンの一貫性が崩れない
- 動画内のテキストを正確に描画できる
- 自分の顔・声を使ったデジタルアバター動画を作成できる
とくに複数の入力情報を組み合わせながら自然な動画を生成できる点は、従来モデルとの大きな違いです。それぞれ詳しく見ていきましょう。
会話形式で直感的に動画を生成・編集できる
Gemini Omniは自然言語を理解できるため、難しい操作を覚えなくても、チャット感覚で動画を生成できます。
実際に「夕焼けの海辺を歩く女性」「近未来都市を飛ぶドローン映像」のように入力するだけで、内容に沿った動画を生成できます。
さらに、生成後に「雨を追加して」「夜の雰囲気に変更して」のように会話形式で追加指示を出せる点も特徴です。
以下のように、シンプルな文章だけで動画を生成できます。
専門的な編集スキルや複雑なソフト操作が不要なため、アイデアをすぐ映像化しやすく、動画制作にかかる時間を大幅に短縮できます。
テキスト・画像・音声・動画を自由に組み合わせて入力できる
Gemini Omniは、テキスト・画像・音声・動画をまとめて入力し、1つの動画として生成できます。
従来の動画生成AIは、テキストのみ、または画像のみを入力として扱うケースが中心でした。
一方でGemini Omniは、複数の情報を同時に理解し、統合したうえで動画を生成できる「真のマルチモーダル設計」を採用しています。
実際に「参考動画+画像+テキスト指示」を同時に入力し、それぞれの要素を反映した動画を生成できます。
既存の動画・画像・音声素材をそのまま活用できるため、ゼロから作り直す必要がありません。
SNS動画制作や広告制作、コンテンツ発信まで、動画制作の効率を大幅に高められます。
物理法則と世界知識でリアルな映像を生成できる
Gemini Omniは、重力・慣性・速度変化といった物理法則を理解しながら、リアリティの高い映像を生成できます。
さらに、歴史・科学・文化的な知識も踏まえて映像を構築できるため、単なるCGのような動きではなく、現実に近い自然なシーンを表現しやすい点が特徴です。
実際に公式デモでは、ビー玉がレール上を高速で転がりながら複雑なコースを進み、周囲のギミックと連動する映像が公開されました。
動きに合わせて効果音も自然に同期しており、「believable physics(説得力のある物理表現)」として注目を集めています。
従来の動画生成AIと比べても、物体の動きや空間の一貫性を維持しながら映像を生成しやすく、より自然な映像表現に近づいています。
複数回の編集でもキャラクターとシーンの一貫性が崩れない
Gemini Omniは、複数回編集を重ねても、人物の特徴やシーンの一貫性を維持したまま動画を生成できます。
一般的な動画生成AIでは、編集を繰り返すことで顔や服装が変化したり、シーンの雰囲気が崩れたりするケースがあります。
一方でGemini Omniは、キャラクター・背景・動作の関係性を維持しながら編集を反映できる点が特徴です。
実際に同じバイオリニストに対して、背景や環境を変更する編集を行っても、人物の顔立ちや服装、演奏している動きの一貫性を保ったままシーンが変化しています。
一度作成したキャラクターや世界観を維持したまま動画を展開できるため、シリーズ動画・広告・SNS運用・ブランド発信まで効率的に行えます。
動画内のテキストを正確に描画できる
Gemini Omniは、動画の中に文字・数式・説明テキストを自然かつ正確に表示できます。
動画生成AIでは、文字が崩れたり意味不明な表記になったりするケースが長年の課題でした。
一方でGemini Omniは、Geminiの高い言語理解力を活かすことで、動画内でも読みやすいテキストを生成しやすくなっています。
実際に公式デモでは、アルファベットごとに異なるアイテムを紹介する動画が公開されました。
画面左下には対応する文字が表示されており、動画全体を通してテキストの一貫性も維持されています。
動画内へ直接テキストを自然に組み込めるため、テロップ編集や字幕追加の作業負担を減らせます。
自分の顔・声を使ったデジタルアバター動画を作成できる
Gemini Omniでは、自分の顔や声を学習させた「デジタルアバター」を使った動画生成に対応しています。
アバターを作成すると、本人に似た見た目や声を反映した動画を生成できるようになります。撮影を行わなくても、自分自身が話しているような映像を作成できる点が特徴です。
アバター作成時には、初回セットアップとして顔と声の登録が必要です。
Geminiアプリの案内に従い、指定された数字や文章を読み上げることで、音声データと本人確認情報が登録されます。
現在この機能は段階的に提供されています。
Googleは公式に、初期段階では「自分の声を参照するボイスリファレンス機能」から対応を開始し、その他の音声入力機能については順次拡張予定であると発表しています。
アバター機能が全面提供されると、撮影なしで自分の顔・声を使ったパーソナライズされた動画を生成できます。
Gemini Omniでできること
Gemini Omniは、動画生成だけでなく編集や音声生成まで幅広く対応しているAIモデルです。
テキスト・画像・音声・動画を組み合わせて扱えるため、1つのツール内でさまざまな動画制作を進められます。
Gemini Omniで利用できる主な機能は以下の通りです。
| 機能 | 概要 |
|---|---|
| テキストから動画生成 | テキストプロンプトから動画を生成 |
| 写真から動画変換 | 最大5枚の写真を組み合わせて動画に変換 |
| マルチターン動画編集 | 会話を重ねながら前の編集状態を引き継いで編集 |
| ネイティブ音声生成 | 環境音・BGMを含む音声付き動画を生成 |
| デジタルアバター生成 | 自分の顔・声を学習させたアバターで動画を作成(音声変換などの一部機能は順次提供予定) |
| YouTubeへの共有 | 生成した動画をYouTubeに共有できる |
複数の動画制作機能をまとめて活用できるため、SNS運用やコンテンツ制作を効率良く進められます。
SHIFT AIでは、生成AIやAIエージェントを日々の業務に活かしたい方に向けて、実務ですぐに使える資料を無料でプレゼントしています。どなたでも受け取れます。
たとえば『Claude Codeで始める業務自動化の教科書』『Claude Code コマンド大全』『AIエージェント用語集』など、明日からの業務にそのまま役立つ資料をご用意しています。
「AIエージェントを使って業務を効率化したい」「まず何から始めればいいか知りたい」という方は、ぜひ以下のボタンから受け取ってください。
30秒で簡単受取!
無料で今すぐもらうGemini Omniの料金プランは3種類
Gemini Omniは無料プランでは利用できません。Google AI Plus・Pro・Ultraの3種類の有料プランが利用対象です。
Gemini Omniを利用できる主な料金プランは以下の通りです。
| プラン | 月額(目安・税込) | 動画生成の回数制限 |
|---|---|---|
| Google AI Plus | 約1,200円 | 2本/日 |
| Google AI Pro | 約2,900円 | 3本/日 |
| Google AI Ultra | 約14,500円〜 | 5本/日 |
また、Gemini OmniのAPIは、今後Gemini APIやAgent Platform API経由での提供も予定されています。
個人的に動画生成や編集を試したい場合は、Google AI Plusでも十分活用できます。利用回数や高度な機能が必要になった場合は、Pro・Ultraプランも検討してみてください。
Geminiの各プランの詳細な料金や選び方については、以下の記事で詳しく解説しています。合わせてご覧ください。
Gemini OmniとVeoの違いを比較
Gemini OmniとVeoは「どちらもGoogleの動画AI」と混同されがちですが、設計の思想から大きく異なります。
Veoは主にテキスト・画像から動画を生成するモデルです。
一方、Gemini Omniはテキスト・画像・音声・動画をあらゆる組み合わせで入力として受け取れるマルチモーダル設計です。
同じプロンプトで両モデルを実行した結果を比較してみました。
以下はGemini Omniで生成した動画です。
以下はVeo3.1で生成した動画です。
Googleは「Gemini OmniはVeoの後継ではなく、Geminiに動画生成・編集能力を統合した別物」と位置づけています。機能の主な違いは以下のとおりです。
| 項目 | Gemini Omni Flash | Veo 3.1 |
|---|---|---|
| 入力形式 | テキスト・画像・音声・動画 | テキスト・画像(限定的) |
| 編集方式 | 会話(自然言語)による編集 | テキストプロンプト+UI操作 |
| マルチターン編集 | あり | なし |
| 動画の最大長 | 10秒 | 8秒(Scene Extension機能で延長可能) |
| デジタルアバター | あり | なし |
| 対応プラットフォーム | ・Geminiアプリ ・Google Flow ・YouTubeショート | ・Geminiアプリ ・Google Flow |
| 利用条件 | 有料プラン(18歳以上) | 有料プラン(Google Flow経由は一部無料) |
品質重視の単発生成にはVeo 3.1が向いており、会話形式の反復編集やマルチモーダル入力を活かした制作にはGemini Omni Flashが向いています。
以下の記事ではVeo3.1の使い方や実際に生成した動画を紹介しています。Veo3.1に興味のある方は是非参考にしてみてください。
Gemini Omniの使い方(Geminiアプリ)
Geminiアプリで動画を生成・編集するまでの手順を3ステップで解説します。
- ステップ1:Geminiの公式サイトにアクセスする
- ステップ2:Gemini Omniに切り替える
- ステップ3:プロンプトを入力して動画を生成する
各ステップに画像付きで解説します。手順通りに進めれば、初めてでも迷わず動画を生成できます。
ステップ1:Geminiの公式サイトにアクセスする
まずは、Gemini公式サイトにアクセスします。
Googleアカウントを持っていれば、すぐに利用を開始できます。
ただし、Gemini Omniを利用するには有料プランへの加入が必要です。画面右上の「アップグレード」から、Google AI ProまたはUltraへ加入してください。
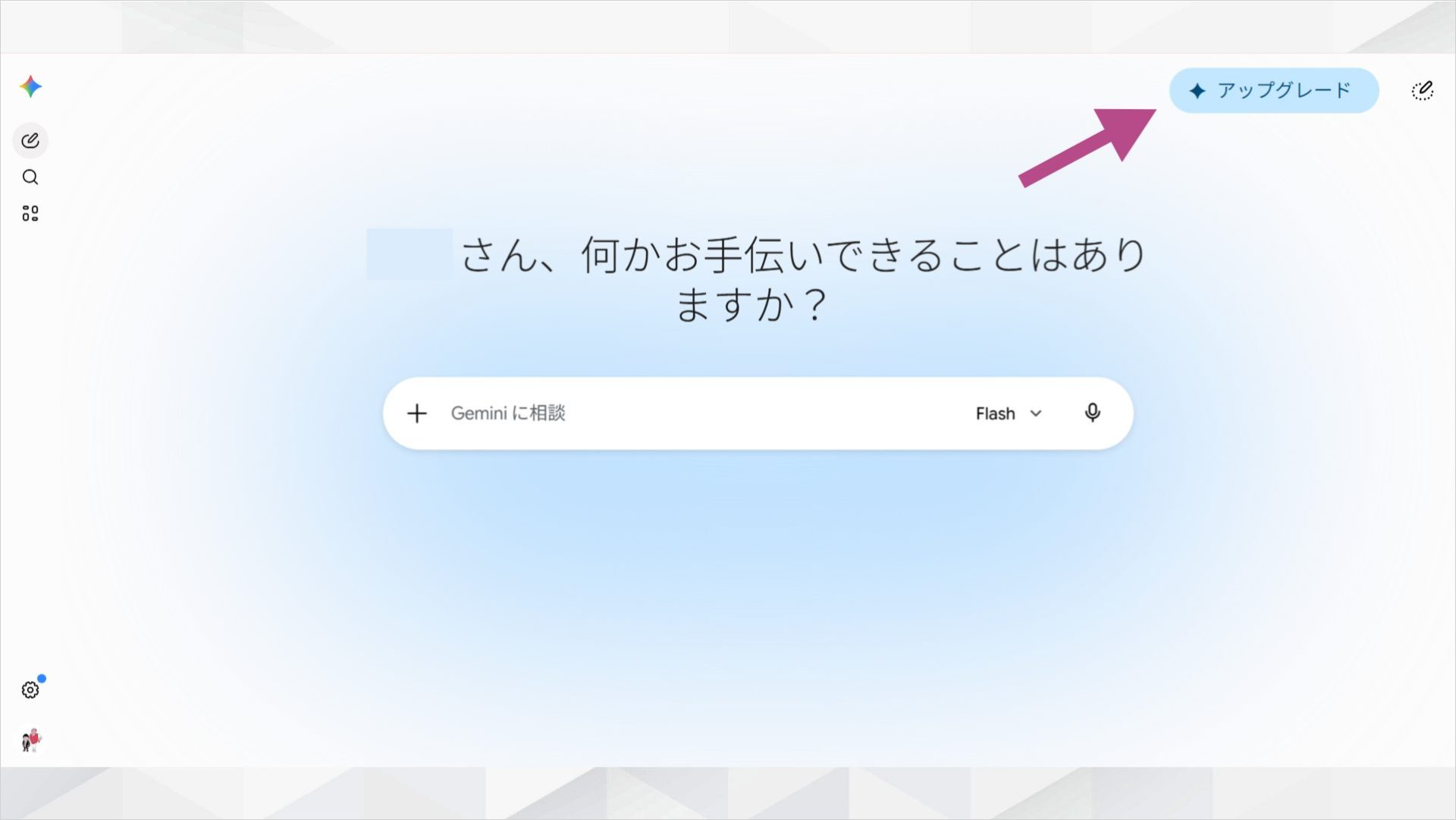
ステップ2:Gemini Omniに切り替える
ログイン後、ホーム画面のチャット入力欄にある「+」ボタンから「動画を作成」を選択します。
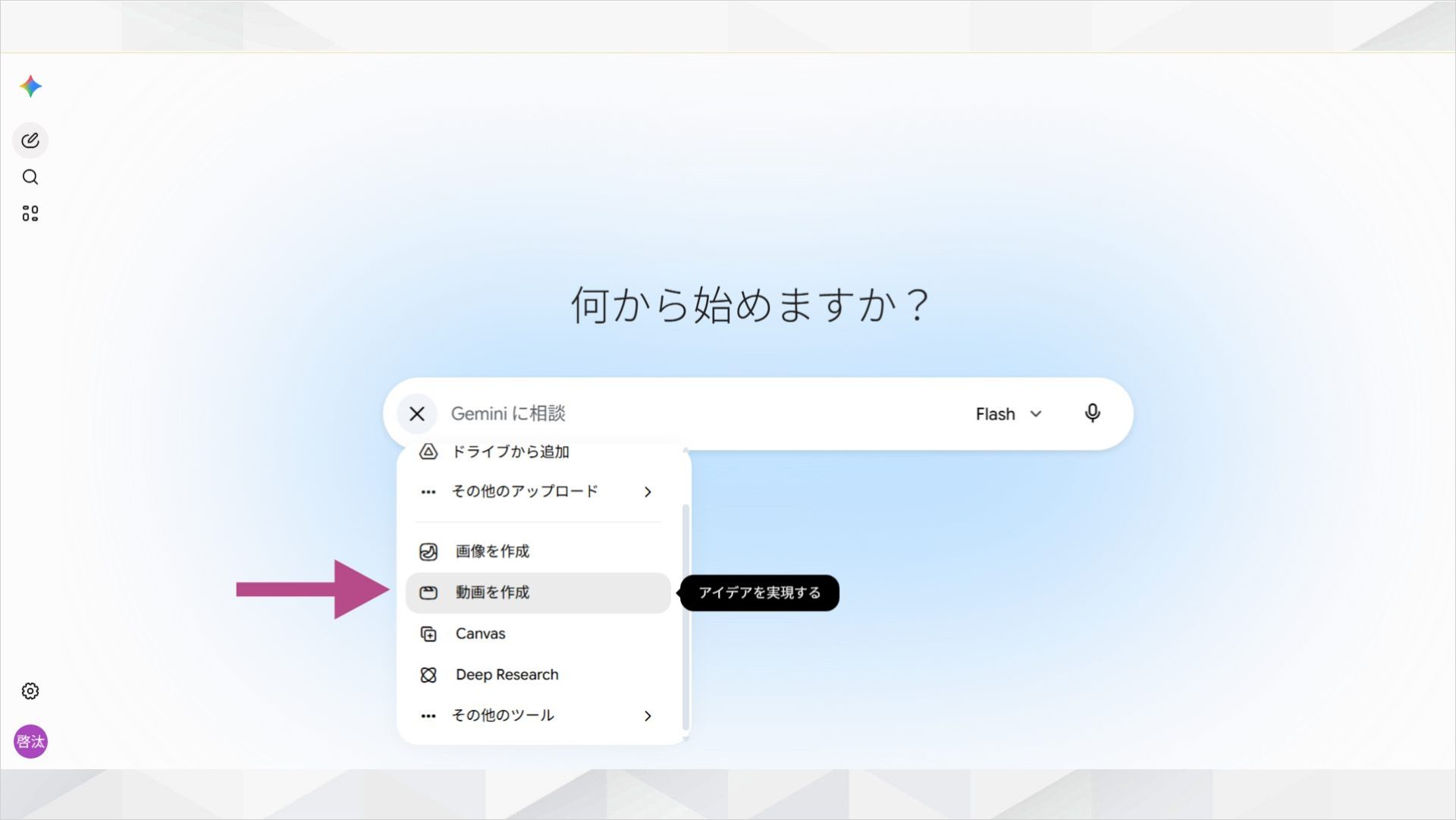
「動画を作成」を選ぶと、Gemini Omniの動画生成画面へ切り替わります。
Gemini Omniでは、Google公式のテンプレートも利用できます。テンプレートを使えば、プロンプトに慣れていない方でも簡単に動画生成を始められます。
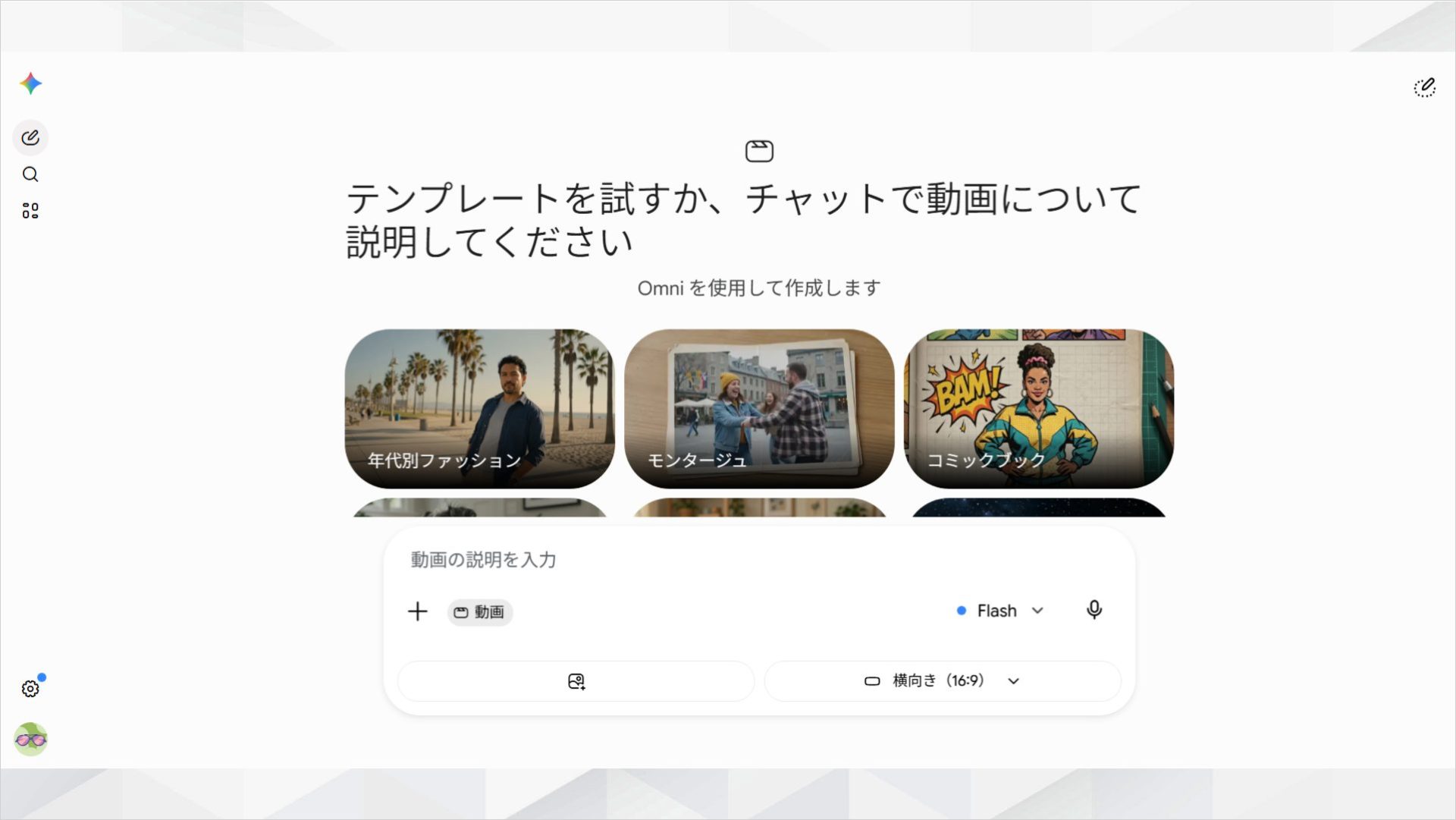
また、入力欄右側のモデル選択メニューから「Gemini Omni Flash」を選択してください。
Gemini Omni Flashは、高速な動画生成や編集に対応したモデルです。まずはFlashモデルから試すと、短時間で生成結果を確認できます。
ステップ3:プロンプトを入力して動画を生成する
Gemini Omniへの切り替えが完了したら、チャット欄に動画の内容を入力して送信します。日本語でも指示でき、専門的なプロンプト知識は不要です。
また、テキストだけでなく、参考画像・音声・動画ファイルをアップロードして生成内容に反映できます。
動画生成には数十秒〜数分かかります。完了後はダウンロードや共有が可能です。
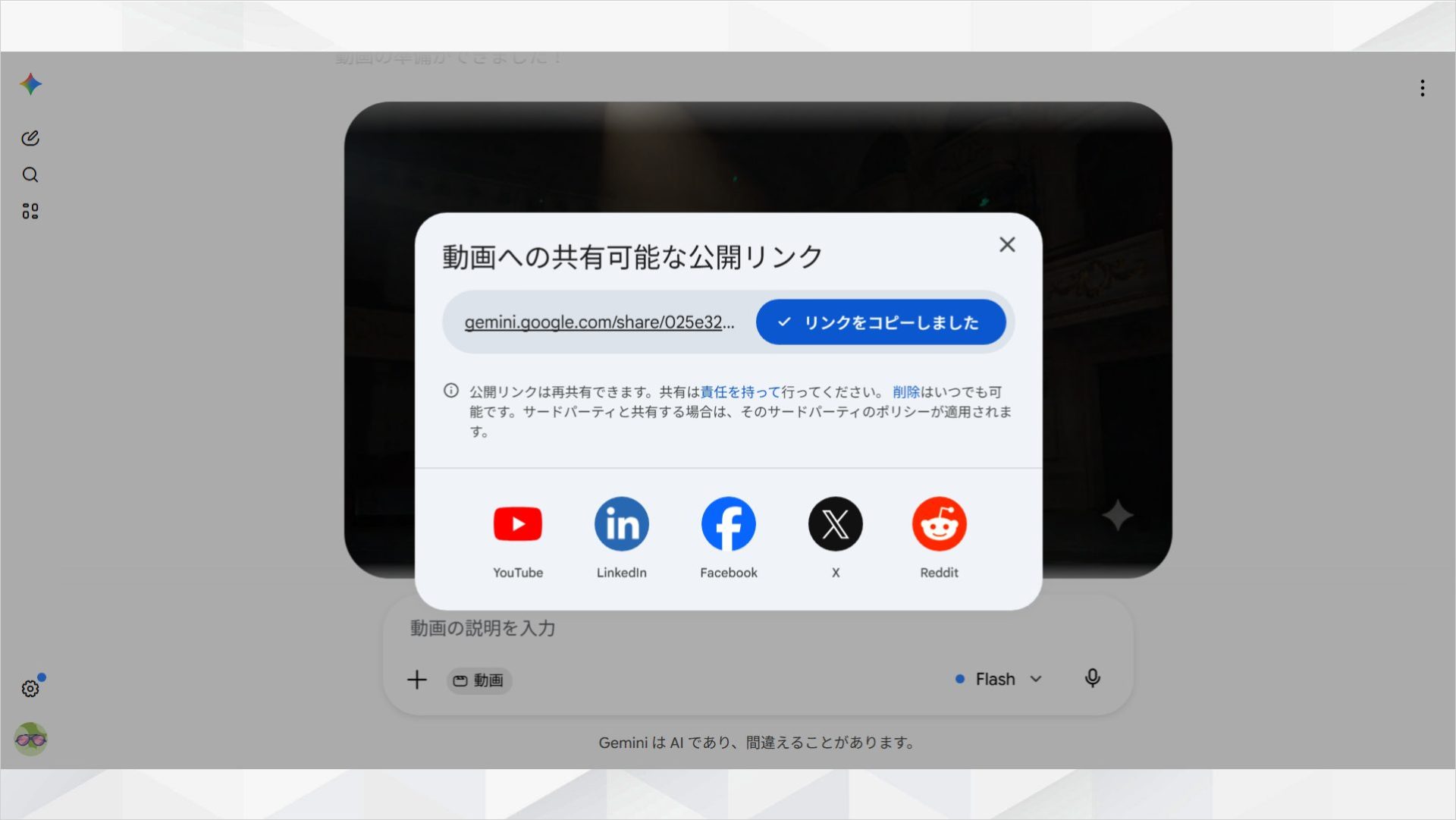
さらに、生成後もチャット欄から追加指示を送るだけで編集できます。
「夕方の雰囲気に変更」「字幕を追加」「カメラワークをゆっくりにする」など、会話形式で調整できる点がGemini Omniの特徴です。
Gemini Omniを実際に使ってみた!
Gemini Omniを実際に操作して確認した4つの結果を紹介します。
| テーマ | 内容 |
|---|---|
| テキスト→動画生成 | 夕暮れの渋谷交差点シーンを10秒動画にしてみた |
| マルチモーダル入力 | 旅行写真3枚から自然な動画を生成してみた |
| マルチターン編集 | 3回の会話でシーンを段階的に仕上げてみた |
| ネイティブ音声生成 | BGM+環境音入りのカフェシーンを一発で作ってみた |
生成クオリティや会話編集の精度など、使って初めてわかった点を中心に解説します。
【テキスト→動画生成】夕暮れの渋谷交差点シーンを10秒動画にしてみた
Gemini Omniの基本性能を確認するために、テキストだけを使った動画生成を試しました。
今回は、日本の街並みをどの程度自然に再現できるのかを検証するため、夕暮れの渋谷交差点をテーマにした動画を生成しています。
以下は実際に使用したプロンプトです。
夕暮れの渋谷交差点を人々が行き交うシーン実際に出力された映像では、人の流れや街のライティング、夕方特有の空気感まで自然に再現されており、テキストのみの入力でも高品質な動画が生成できています。
Gemini Omniでは「思いついた内容をそのまま日本語で入力するだけ」で自然な映像を生成できます。
【マルチモーダル入力】旅行写真3枚から自然な動画を生成してみた
Gemini Omniでは、複数枚の画像を入力として渡し、1本の動画へ自然につなげる「マルチモーダル入力」に対応しています。
今回は、旅行先で撮影した3枚の写真を使って、スライドショーではない動きのある映像を生成できるかを検証しました。
以下は実際に使用したプロンプトです。
自然な流れでつながる動画にして実際に生成された動画では、写真と写真の間が自然に補間されており、単純な切り替えではなく「映像としてつながっている」ような仕上がりになりました。
Gemini Omniは、画像・音声・動画をまとめて扱えるマルチモーダル設計になっているため、複数素材を組み合わせた場合でも一貫性の高い動画を生成できます。
【マルチターン編集】段階的に動画を生成してみた
Gemini Omniでは、会話を続けながら動画を段階的に編集できる「マルチターン編集」に対応しています。
今回は、生成済みの動画に対して2回連続で編集指示を行い、どの程度一貫性を維持できるのかを検証しました。
以下は実際に使用したプロンプトです。
【一回目】
主人公の服装を、元のキャラクターデザインやライティング、カメラ構図を維持したまま、清潔感のある白い衣装に変更してください。
【2回目】
主人公やカメラワークはそのまま維持しつつ、背景を木漏れ日が差し込むリアルな森の風景に変更してください。実際に生成された動画では、1回目で変更した白い衣装が維持されたまま、2回目の指示で背景のみが自然に変更されました。
Gemini OmniはGeminiのLLMベースで会話履歴を保持しながら編集を行うため、前回の変更内容を理解した状態で次の編集を重ねられます。
【ネイティブ音声生成】BGM+環境音入りのカフェシーンを一発で作ってみた
Gemini Omniでは、映像だけでなく環境音やBGMも含めた「ネイティブ音声生成」に対応しています。
今回は、カフェの空気感まで含めたシネマティック映像を生成し、映像と音声の自然な同期精度を検証しました。
以下は実際に使用したプロンプトです。
暖かみのあるカフェで、女性が読書しているシネマティックなシーンを生成してください。コーヒーカップの音、周囲の小さな会話音、落ち着いたBGMなどの自然な環境音も含めてください。自然なカメラワークとリアルな雰囲気を重視してください。実際に生成された動画では、コーヒーカップを置くタイミングと効果音が自然に一致しており、周囲のざわめきやBGMも映像の雰囲気に馴染んでいました。
Gemini Omniでは映像と音声を同時に生成できるため、プロンプト1本で完成度の高い動画を出力できます。
SHIFT AIでは、生成AIやAIエージェントを日々の業務に活かしたい方に向けて、実務ですぐに使える資料を無料でプレゼントしています。どなたでも受け取れます。
たとえば『Claude Codeで始める業務自動化の教科書』『Claude Code コマンド大全』『AIエージェント用語集』など、明日からの業務にそのまま役立つ資料をご用意しています。
「AIエージェントを使って業務を効率化したい」「まず何から始めればいいか知りたい」という方は、ぜひ以下のボタンから受け取ってください。
30秒で簡単受取!
無料で今すぐもらうGemini Omniで生成した動画の著作権と注意点
Gemini Omniで生成した動画を活用するうえで、商用利用・電子透かし(SynthID)・禁止コンテンツに関して3つの注意点があります。
| テーマ | 内容 |
|---|---|
| 商用利用 | 有料プランでも利用規約と著作権法の個別確認が必要 |
| 電子透かし | SynthIDが全動画に自動で入り、削除できない |
| 禁止コンテンツ | 実在人物・著作権素材の利用は規約違反になる |
3点それぞれを事前に把握しておくことで、トラブルなくGemini Omniを活用できます。
【商用利用】有料プランでも利用規約と著作権法の個別確認が必要
Gemini Omniで生成した動画は、Googleの利用規約および生成AIの禁止使用ポリシーの範囲内で商用利用できます。
ただし、AI生成コンテンツは法律や権利関係の扱いが複雑なため、利用前に確認が必要です。
とくに日本では、AI生成物の著作権保護に関する判断がケースごとに異なる場合があります。
Googleの利用規約には以下のように記載されています。
ユーザーのコンテンツはユーザーに帰属します。つまり、コンテンツに含まれるユーザーの知的所有権はすべてユーザーが保持します。
引用:Google 利用規約(Google)
商用コンテンツとして公開する際は、「AI生成コンテンツ」であると明示したうえで、Googleの最新利用規約やコンテンツポリシーを事前に確認するようにしましょう。
【電子透かし】SynthIDが全動画に自動で入り、削除できない
Gemini Omniで生成した動画には、Googleの電子透かし技術「SynthID」が自動で埋め込まれます。
なぜなら、AI生成コンテンツの普及によって、「人が作成したものなのか」「AIで生成されたものなのか」を判別する重要性が高まっているためです。
SynthIDは、動画内へ人には見えない識別情報を埋め込むことで、AI生成コンテンツであると確認しやすくしています。
実際にGemini Omniは、C2PA(Content Credentials)規格にも対応しています。
GeminiアプリやGoogle検索などを通して、コンテンツの真正性を検証できる仕組みが整備されています。
ただし、SynthIDによる透かしが埋め込まれている場合でも、動画を公開するときは「AI生成コンテンツ」であると明記するようにしましょう
【禁止コンテンツ】実在人物・著作権素材の利用は規約違反になる
実在人物や著作権素材を無断で利用した動画生成は、Googleの利用規約に違反する可能性があります。
Googleは生成AIの安全な普及を目的として、特定の個人・組織への被害や、社会的な誤情報の拡散につながるコンテンツ生成を禁止しています。
特に、以下のようなコンテンツはGoogleの「Gen AI Prohibited Use Policy」により制限されています。
- 実在人物を無断で使用したコンテンツ(ディープフェイク・なりすまし等)
- 虚偽情報や誤情報を拡散するコンテンツ
- 第三者の著作権・商標を侵害するコンテンツ
- 性的・暴力的・ハラスメントを目的としたコンテンツ
これらのルールに違反した場合、アカウント停止やコンテンツ削除、法的責任につながる可能性があります。
生成した動画をSNSやYouTubeなどで公開・活用するときは、事前にGoogleのポリシーを確認するようにしましょう。
Google I/O 2026で他に発表された内容
Gemini Omniが発表されたGoogle I/O 2026では、ほかにも多くのAI関連サービスが発表・アップデートされました。
| サービス名 | 概要 |
|---|---|
| Gemini 3.5 Flash | ほぼすべてのベンチマークで前世代を大幅に上回る、高速・高精度な新モデル。 |
| Gemini Spark | 24時間365日稼働するパーソナルAIエージェント。 複数ツールと連携し長時間タスクを自律処理。 |
| Google Pics | テキスト指示で画像の生成・編集ができるツール。 |
| Ask YouTube | 会話形式でYouTube動画を検索・要約できる機能。 |
| Docs Live | Google Docsに追加された音声指示でドキュメントをリアルタイム編集できる機能。 |
| Gemini for Science | 科学・研究分野に特化したAI活用基盤。 |
いずれもGeminiを中核としたGoogleのAI統合がさらに加速していることを示す発表内容でした。
今後のアップデートで連携が深まることで、Gemini Omniと組み合わせた活用の幅も広がっていきます。
以下の記事では、Gemini Omniと同時に発表されたGemini 3.5 Flashの特徴や使い方などを紹介しています。合わせてご覧ください。
Gemini Omniを使いこなして、動画制作を次のステージへ
Gemini Omniは、テキスト・画像・音声・動画をあらゆる組み合わせで入力でき、会話だけで動画を生成・編集できるGoogleの最新AIモデルです。
Google AI Plusプラン以上に加入していれば、今日からGeminiアプリで使いはじめられます。
ぜひ本記事を参考に、Gemini Omniで動画生成を試してみてください。
SHIFT AIでは、生成AIやAIエージェントを活用して業務を効率化したい方に向けて、実務ですぐに使える資料を無料でプレゼントしています。
受け取れる資料には、たとえば以下のようなものがあります。
- 『Claude Codeで始める業務自動化の教科書』:定型業務を自動化する実践パターン
- 『Claude Code コマンド大全』:現場でよく使うコマンドを場面別に解説
- 『AIエージェント用語集』:つまずきやすい重要用語をやさしく整理
- 『Claude Code インストール&環境構築ガイド』:ゼロから始める初期設定の手順
- 『AI社員の作り方(スキル集)』:AIに仕事を任せるためのスキルづくり
- 『Claude Code × Codex 使い分けガイド』:目的に合わせた賢い使い分け
いずれも、生成AI・AIエージェントをこれから業務に取り入れたい初心者〜中級者の方に向けた内容です。
「AIを使ってみたいけれど何から始めればいいか分からない」「独学で進めるのに限界を感じてきた」という方にとくにおすすめです。
すべて無料で受け取れますので、気になる資料があれば、ぜひ以下のボタンから受け取ってみてください。
30秒で簡単受取!
無料で今すぐもらう目次


執筆者

西啓汰
フリーランスのSEO/AIライターとして活動。
生成AIツールを実際に検証し、その知見をもとに実務で活用できる情報発信を行っている。
AI関連の最新動向や活用ノウハウを、初心者にもわかりやすく伝えるコンテンツ制作が強み。
趣味は野球観戦とラジオ聴取。










30秒で簡単受取!
無料で今すぐもらう