share



プロンプトエンジニアリングとファインチューニングの違いと活用法を徹底解説!

ChatGPTなどの生成AIを触ってみたものの、「プロンプトエンジニアリング」「ファインチューニング」といったの専門用語が多く戸惑っていませんか。
プロンプトエンジニアリングとファインチューニングは、目的やコスト、求める正確性による使い分けができると効果的です。
一方で、違いを知らずにいると、AI活用が中途半端なまま進み、業務効率化の機会を逃したり競合に後れを取ったりするリスクがあります。さらに、せっかくの投資が無駄になってしまうかもしれません。
本記事では、プロンプトエンジニアリングとファインチューニングのメリット・デメリットをわかりやすく比較しました。
また、RAG(Retrieval Augmented Generation)を用いて最新情報を取り込む方法も解説しています。
この記事を読むことで、プロンプトエンジニアリングとファインチューニングの違いを明確に理解できます。
違いの理解は、業務に合ったAI活用法の選択や、上司や同僚からの評価アップにもつながるでしょう。ぜひ最後まで読み進めて、最適な形で導入できるようになってください。

監修者
SHIFT AI代表 木内翔大
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
プロンプトエンジニアリングとファインチューニングの違い
プロンプトエンジニアリングは、既存のAIモデルに対して「指示文(プロンプト)」を最適化する方法です。
一方、ファインチューニングは、モデル自体を再学習し、専門知識や独自の文体を内部に追加するアプローチになります。
この違いを理解することで、AI導入の方針を明確にできるのがポイントです。どちらを優先すべきかは、予算や目的、求める正確性によって異なります。
たとえば、日常文書や汎用的な業務ならプロンプトエンジニアリングで十分ですが、専門領域や高い正確性が求められる場面ではファインチューニングが有効です。
また、段階的に導入していけば、失敗リスクを下げながら効果を検証できます。
たとえば、営業メールや社内連絡であれば「既存モデルへの指示最適化(プロンプトエンジニアリング)」だけでも成果を得られます。
しかし、医療や法律のように高度な専門知識が必要な領域では、モデル自体に再学習を施す(ファインチューニング)ことで、より正確な回答を得られます。
プロジェクトの規模や専門度を考慮し、「すぐに小さく始めるべきか」「じっくり再学習すべきか」を適切に選べるようになります。
プロンプトエンジニアリングとは何か
プロンプトエンジニアリングとは、既存モデルを再学習せず、指示文(プロンプト)を工夫することでAIの性能を引き出す方法です。
ここでは、以下の内容について説明します。
- プロンプトエンジニアリングのメリット
- プロンプトエンジニアリングのデメリット
- プロンプトエンジニアリングの活用例
プロンプトエンジニアリングは低コストかつ短期間で導入しやすく、失敗のリスクを最小限にできます。
さらに詳しくプロンプトエンジニアリングを学びたい場合は以下の記事もおすすめです。

それでは「メリット・デメリット・活用例」を順番に見ていきましょう。
プロンプトエンジニアリングのメリット
プロンプトエンジニアリングの最大の魅力は、手軽で低コスト、そして再学習が不要なため、すぐに効果を試せる点です。
単に指示の書き方を変えるだけなので、特別なデータ収集や高度な学習環境を用意する必要がなく、小規模なプロジェクトやAI導入の初期段階にとくに向いています。
たとえば、社内で営業メールやクレーム対応の文面をAIに生成させる場合、「相手の立場を考慮し、丁寧な敬語で3パターン作成して」と具体的に指定するだけで、作業時間を大幅に削減できます。このとき、特別な追加コストはほとんどかかりません。
このように、プロンプトエンジニアリングは、すぐに始められて失敗リスクが低いため、AIの試験運用や小規模プロジェクトに最適な手法です。
プロンプトエンジニアリングのデメリット
一方で、もともとAIモデルにない専門知識を与えることはできないため、高い正確性が求められる現場では限界があります。
プロンプトエンジニアリングでは、あくまでも指示の最適化だけを行っているのであって、AIモデルに新しい知識を学ばせているわけではないからです。
元のモデルが持っていない知識は、どんなに指示を工夫しても引き出せません。
たとえば、医療や法律分野で細かい専門知識を必要とする質問をした場合、既存のAIモデルでは誤った回答や曖昧な回答が出力されやすいです。
こうしたデメリットを理解しておくことで、専門性が必要な場面ではファインチューニングへと切り替えるなど、AIに対する誤った期待値設定を避けられます。
プロンプトエンジニアリングの活用例
プロンプトエンジニアリングは、一般的なメール文の生成やブログ記事執筆のサポートなどの比較的専門度が低いタスクにとくに効果を発揮します。
提示する条件を細かく指定することで、文章作成の時間を大幅に短縮でき、すぐに業務に応用しやすいからです。
たとえば、「社内向けのスケジュール連絡を箇条書きで5点程度にまとめて」といった指示を出すことで、短時間に大量の文面を効率よく生成できます。
ここで、具体的な指示を出すことの重要性について説明します。

上記の図は、曖昧な指示と具体的な指示での回答を比較しています。
「これを要約して」というだけの曖昧な指示では、AIの出力が文体や文字数などバラバラになってしまいます。
「200文字以内で・敬語で・箇条書き2点」などと具体的に指定すると、条件通りの整った回答が得られます。
このように、わずかな指示の工夫で回答の質が大きく変わります。
プロンプトの書き方を工夫するだけで、さまざまな業務効率化が実現できます。具体的な利用シーンがイメージしやすいため、現場での即戦力としてすぐに導入できる点が大きな利点です。
プロンプト設計のフローは以下の流れで進めます。
- まずタスク目標を明確に決める(メール作成や要約など)
- 文字数や文体など具体的な指示を加える
- 出力結果を確認し、必要に応じて修正・再指示する
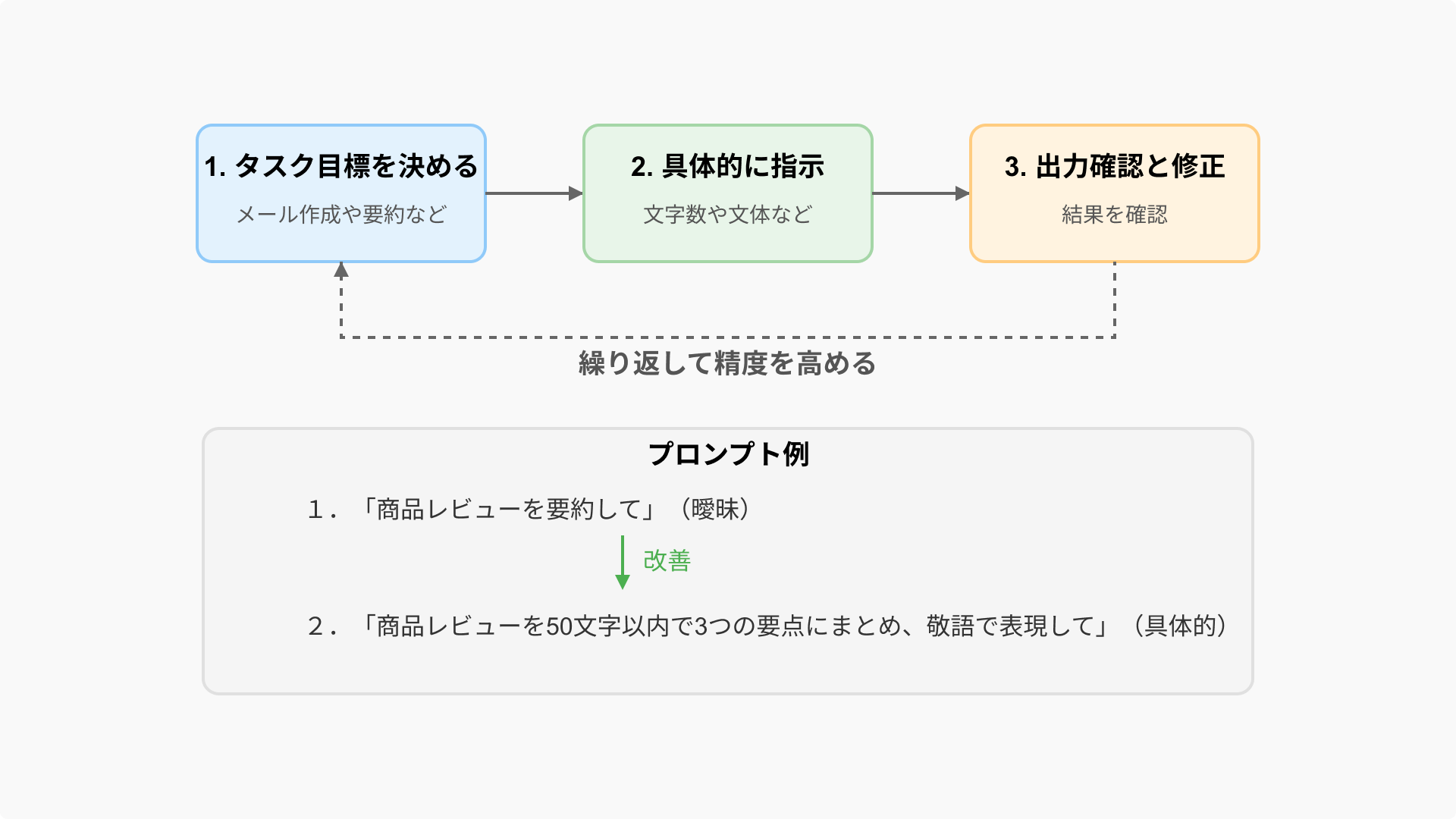
このサイクルを繰り返すことで、徐々に精度を高められます。
ファインチューニングとは何か
ファインチューニングとは、既存のベースモデルに対して追加データを学習させることで、専門的な知識や独自の文体をモデル内部に取り込む手法です。
とくに医療や法律など、高度な正確性が求められる専門領域で大きな効果を発揮します。
ここでは、以下の内容を説明します。
- ファインチューニングのメリット
- ファインチューニングのデメリット
- ファインチューニングの活用例
ファインチューニングを行うことで、モデルが自社独自の知識を身につけるため、競合他社との差別化や高付加価値のサービス提供が可能になります。
ただし、十分なリターンを見込めないのに多額の費用や時間をかけてしまうのは避けたいところです。
それでは、ファインチューニングのメリット、デメリット、具体的な活用例を詳しく見ていきましょう。
ファインチューニングのメリット
ファインチューニングの最大のメリットは、独自データや専門用語をモデル内部に組み込めるため、正確で一貫性のある回答を期待できる点です。
既存モデルの基礎的な言語理解能力を活かしつつ、追加の学習データによって特定分野の知識を深く学ばせられるからです。汎用モデルに「専門教育」を施すようなイメージです。
たとえば、医療系のカルテ情報や企業独自の製品マニュアルをファインチューニングで学習させれば、曖昧な質問に対しても正確な返答を引き出せるようになります。
「この症状は何の疾患の可能性がありますか?」といった質問でも、学習したデータに基づいた信頼性の高い回答を得られるのです。
自社や特定分野にぴったり合ったAIを構築できるため、他社との差別化や高付加価値サービスの提供が容易になり、ビジネス上の競争優位を確立しやすくなります。
ファインチューニングのデメリット
一方で、データ収集やGPU環境の構築などに多大なコストがかかり、学習プロセスも複雑で時間を要するというデメリットがあります。
再学習を行うためには大量の文書を収集・整形し、モデルのパラメータを更新し、何度もテストを繰り返しながら運用へと進める必要があるからです。専門知識を持つエンジニアの確保も課題になります。
たとえば、法務関連の文書や多言語データを扱う場合、数万件のファイルを整理し、学習環境の構築だけでも数十万〜数百万円のコストが発生する事例も珍しくありません。
こうしたデメリットをあらかじめ理解し、投入する労力に見合うリターンを見込めるかどうかを冷静に判断することで、無駄な出費や組織の混乱を防げます。
ファインチューニングの活用例
ファインチューニングは、高い専門性や独特の文体が求められる現場でとくに効果を発揮し、業務効率の大幅な向上や市場での差別化につながります。
これは、モデルが内部に取り込んだ知識が増えることで、短いプロンプトや曖昧な質問でも高精度な回答を返せるためです。
具体的な例としては、次のようなケースが挙げられます。
- 医療アプリに臨床データを学習させ、患者の問診補助やリスク判定をサポートする
- 専門書や特許文献を学習させ、研究者向けの技術相談や新たな研究アイデアの提案に役立てる
ここで、専門性とコストについて解説します。
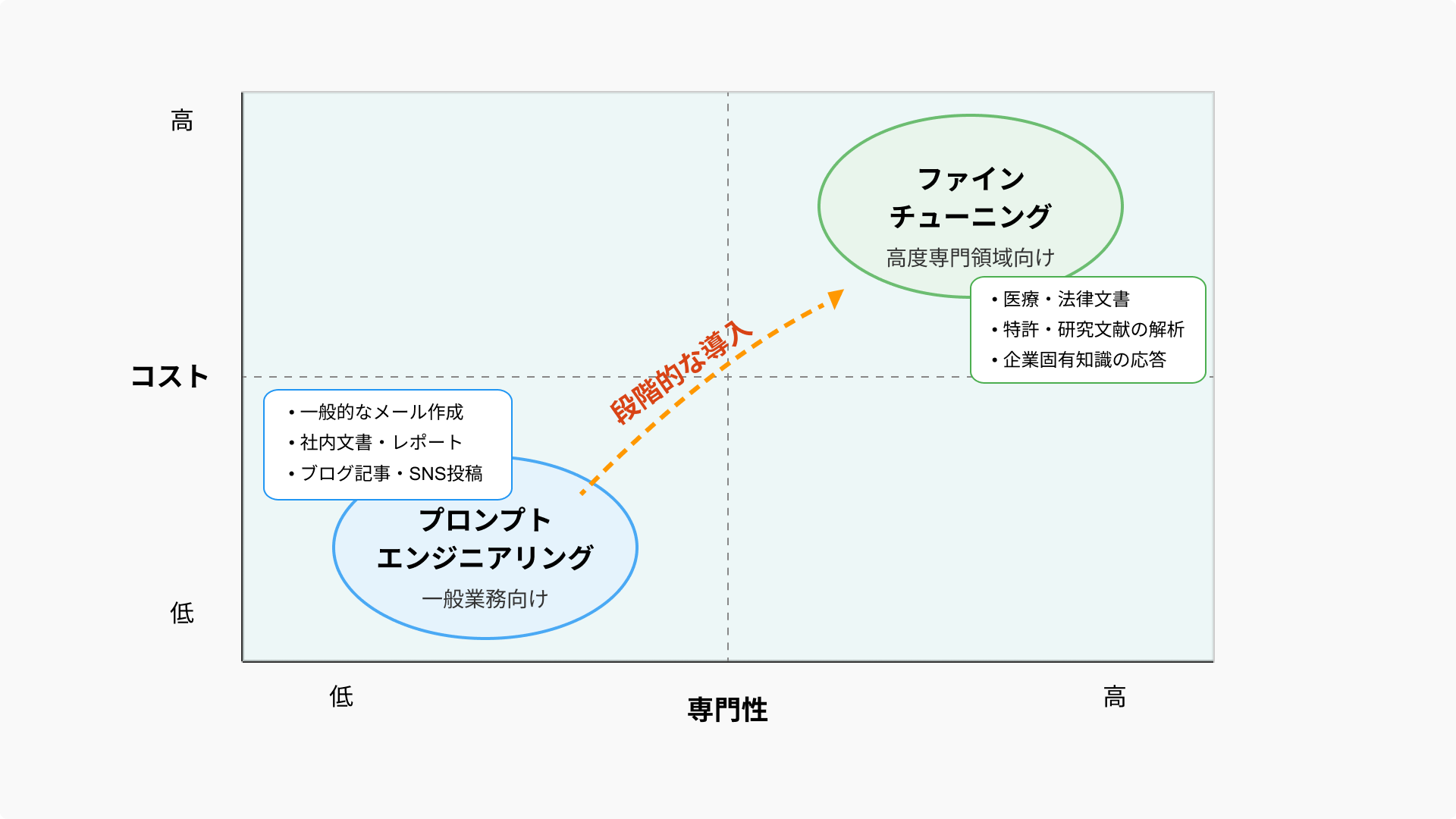
上図のマトリクスは、横軸に専門性、縦軸にコストを示しています。
一般的な業務ではプロンプトエンジニアリングのみで十分対応できることが多いですが、専門性が高まるにつれてファインチューニングの必要性も高まることがわかります。
このように、特定の専門分野で確かな成果を出し、AI導入の付加価値を高められることが、ファインチューニングの大きなメリットといえるでしょう。
【どちらを選ぶ?】プロンプトエンジニアリングとファインチューニングの使い分け
「まずはプロンプト最適化で成果を試し、どうしても専門性が必要な場合にのみファインチューニングへ進む」という段階的な導入フローをおすすめします。
以下の2つの観点から、それぞれの手法の使い分けを考えてみましょう。
- 基本的な導入ステップ
- 業務用途を基準に選ぶポイント
段階的に導入することの大きなメリットは、初期コストを抑えながら、着実にAI活用の範囲を拡大できる点にあります。
いきなり大規模な再学習プロジェクトに投資してしまい、費用対効果が見合わずプロジェクトが頓挫してしまう事態は避けたいものです。
それでは、まずは基本的な導入ステップから具体的に見ていきましょう。
基本的な導入ステップ
基本的な導入ステップとしては、まずプロンプト最適化を試し、対応できない専門性が必要な場合にのみ、ファインチューニングを検討するという流れが一般的です。
なぜなら、多くの業務においては指示の工夫だけで大幅に改善できるケースが多く、いきなり高コストの再学習に走るのはリスクが高いからです。
たとえば、日常的な営業メールの作成や社内連絡文書の生成は、プロンプトを工夫するだけでも十分満足できる成果が得られるでしょう。
一方、医療や法律などの専門分野で高い正確性が求められる場合は、再学習によってモデル内に専門知識を付与することで、より信頼性の高い結果を期待できます。
このアプローチを採用することで、無駄なコストをかけずに済み、必要に応じて段階的に導入効果を高められます。
業務用途を基準に選ぶポイント
メール作成や社内連絡といった低専門度の業務はプロンプトエンジニアリング、高度な知識が必要な分野だけファインチューニングを活用する方法がよく採用されています。
すべてを再学習しようとするとコストや期間が膨大になりがちなので、最小限で最大の効果を得るには用途ごとに分けて考えるのが効率的です。
以下に、プロンプトエンジニアリングとファインチューニングの比較結果を表にまとめました。
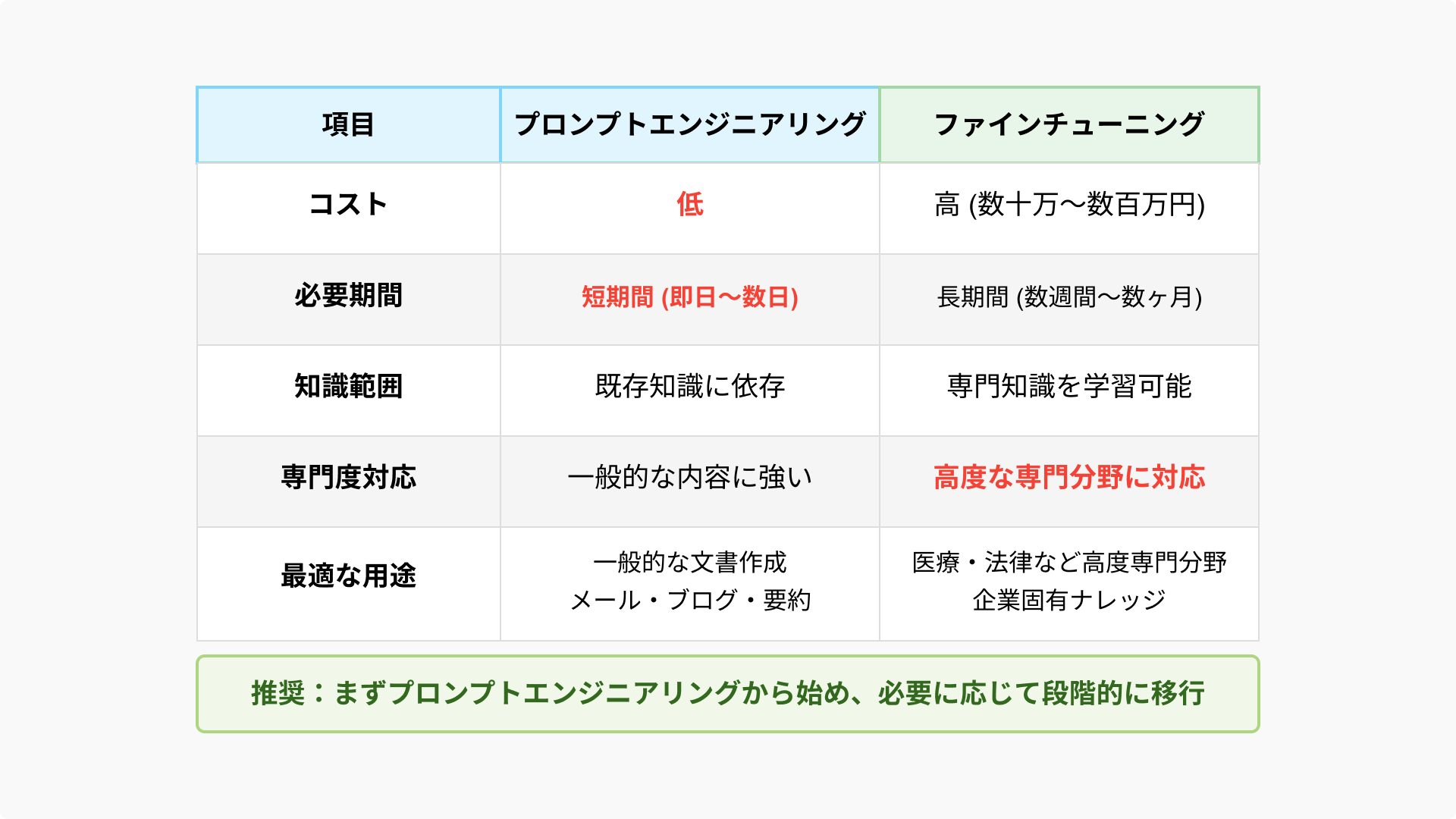
表にもあるように、まずは低リスクなプロンプトだけでメール・資料作成を効率化し、精度が問われる部分は後からファインチューニングする、といった使い分けがおすすめです。
小さな成功体験を得ながら、高度な領域へ拡張しやすいため、コストやリスクをうまくコントロールできます。
RAGを活用して外部データから最新情報を補う
RAG(Retrieval Augmented Generation)は、AIが回答を生成する際に外部データベースを参照しながら回答を作成し、最新情報をリアルタイムに反映できる革新的な仕組みです。
この手法の優れている点は、AIモデル自体を再学習させることなく、検索したデータをリアルタイムで要約・再構成できるため、日々変化する情報にも柔軟に対応できることにあります。
プロンプトエンジニアリングの手軽さと、ファインチューニングの専門性を組み合わせたような中間的手法ともいえるでしょう。
たとえば、頻繁に更新されるニュース情報や在庫データを扱うECサイトでは、ユーザーの質問に合わせて最新の在庫状況や価格情報をリアルタイムで回答できます。
AIモデルを再学習させなくても、外部のデータベースを参照するだけで新しい知識を扱えます。
以下は、RAGの基本的な動作フローを示しています。
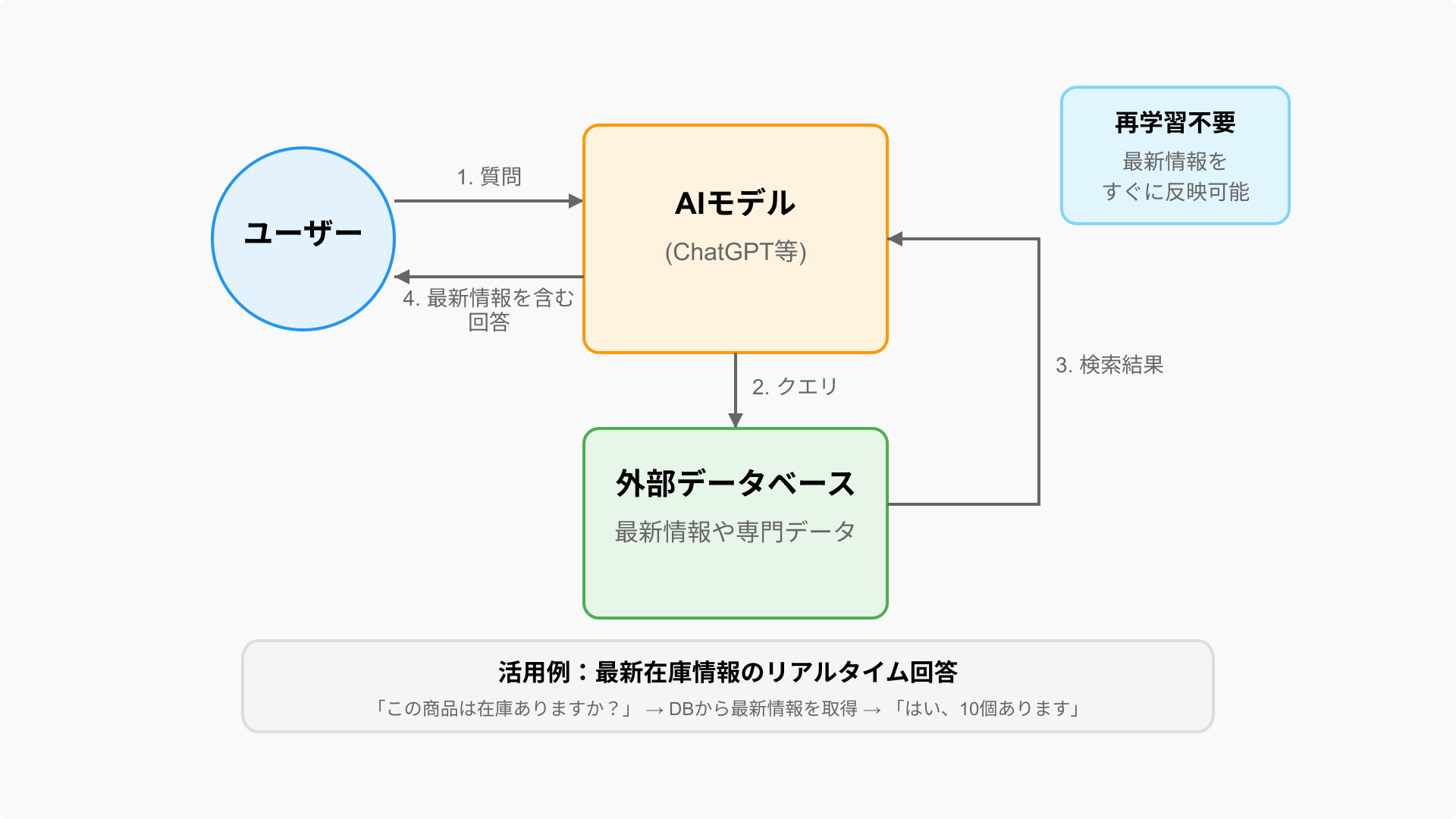
- ユーザーがAIに質問を投げかける
- AIが外部データベースに対してクエリを実行し、関連情報を検索
- 検索結果を要約・整理して回答に組み込む
- 最新情報を含む高品質な回答をユーザーに返す
AIの内部知識が古くなっていても、外部データベースを参照することで常に最新の情報を回答に取り込めます。不動産情報や製品カタログなど、常に新鮮なデータを扱う必要のあるビジネスにとくに適しています。
プロンプトエンジニアリングとファインチューニングの違いを踏まえてAI導入を成功させるには
ここまで、プロンプトエンジニアリング、ファインチューニング、そしてRAGの概要や違いについて詳しく解説してきました。
プロンプトエンジニアリングから始めて、専門性が必要な場合にファインチューニングを検討し、最新情報が重要ならRAGを活用するという段階的アプローチがおすすめです。
ぜひこれらの手法を実際に試して、業務効率やサービス品質の向上につなげてみてください。
AIを活用して副業で収益を得る方法に興味があるものの、具体的なステップがわからず困っていませんか。
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
30秒で簡単受取!
無料で今すぐもらう目次


執筆者

野口啓介
WEBライター、SNSマーケター、クリエイティブ
クリエイティブと業務効率化において様々なAIツールをフル活用し、成果を出している
- SHIFT AIではメディア記事執筆を担当
- Instagramを中心としたSNSマーケティング
- AIクリエイティブ – AIを駆使した映像制作
- ・Midjourney、Runway、Suno
- 業務効率化 – AIを活用したアプリ作成
- ・Dify、Cursor、replit、GPTs
- 実績・成果
- ・GPTsコンテンスト2位受賞
- ・AI活用で月間作業30時間短縮











30秒で簡単受取!
無料で今すぐもらう