share



【専門知識なし】ChatGPTとBigQueryを連携する方法を徹底解説!

データ分析の効率化は重要ですが、「SQLやBigQueryの知識がない」と不安に感じていませんか?
特に、Google BigQueryの強力なツールを活用したいと思いつつ、その敷居の高さに尻込みしている方も少なくないでしょう。
実は、ChatGPTを活用すれば、SQLの専門知識がなくてもBigQueryの機能を簡単に利用できます。
ChatGPTとBigQueryを連携すれば、複雑なデータ分析も短時間で実現し、業務効率が大幅に改善されます。
本記事では、BigQueryの準備から具体的な手順、さらに応用事例や注意点までを徹底解説します。
最後までお読みいただければ、初心者でも安心してChatGPTとBigQueryを使いこなせます。

監修者
SHIFT AI代表 木内翔大
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
目次
BigQueryを利用するために必要な準備
BigQueryを利用するためには、2つの初期準備が必要です。
- Google Cloudアカウントの登録
- BigQueryプロジェクトの設定
順番に進めることで、利用時のトラブルを未然に防ぎ、安定した環境でデータ分析を行えます。
それでは、以下で初期準備の具体的な手順について詳しく解説していきます。
ChatGPTのコード生成能力を活用する方法について知りたい方は以下の記事もあわせてお読みください。

Google Cloudアカウントの登録
BigQueryを利用するには、Google Cloudアカウントの登録が必須です。
Google Cloudアカウントを作成することで、BigQueryをはじめとするGoogle Cloud Platformのサービスを利用できます。
新規登録者には無料クレジット(90日間300ドル相当)が付与され、初期費用を気にせずにサービスを試せます。
具体的なGoogle Cloudアカウントの登録手順は以下の通りです。3つのステップを完了することで、Google Cloudアカウントが作成でき、BigQueryを利用できます。
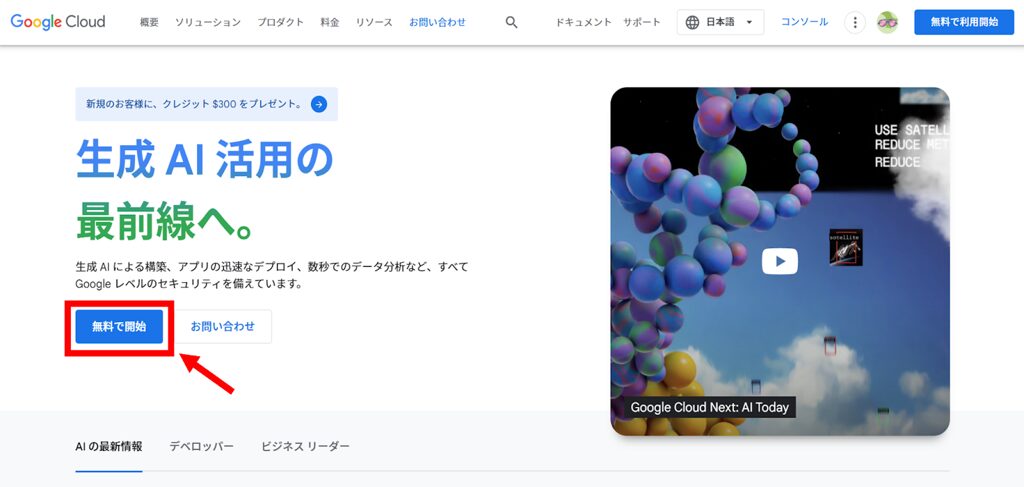
- 「無料で開始」を選択
- 個人情報の入力
- 支払い情報の入力
個人情報の入力
次に、Googleアカウント情報の入力を行います。
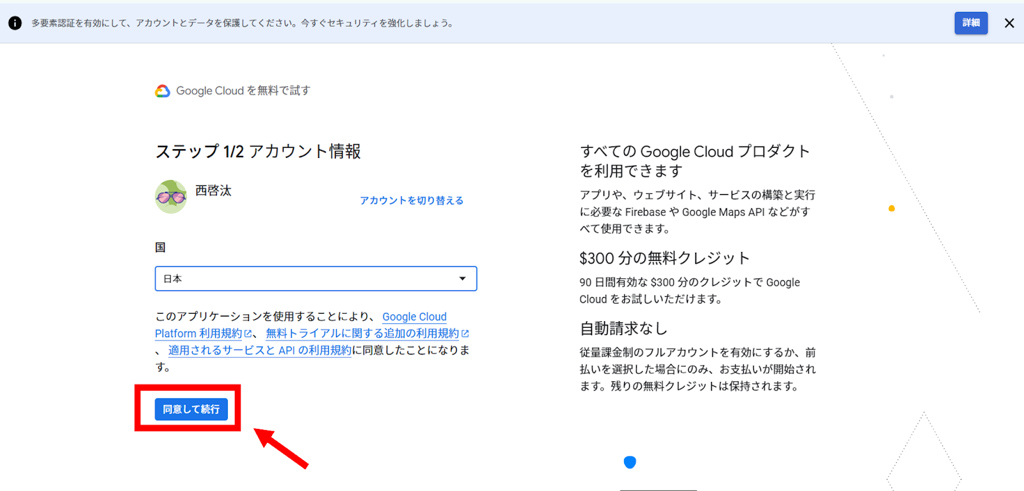
使用したいGoogleアカウントであるかを確認をしてください。
その後、利用契約を確認し、問題なければ、「同意して続行」を選択します。
支払い情報の入力
次に本人確認と支払い情報の入力が必要です。
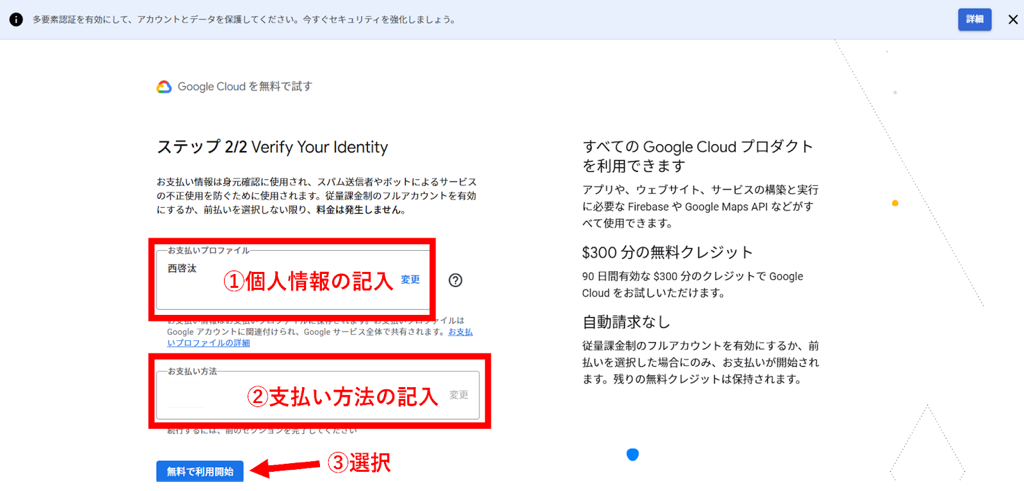
個人情報と支払い情報の入力が終了後、「無料で利用開始」を選択します。
BigQueryプロジェクトの作成
BigQueryを利用するには、Google Cloud Platform上でプロジェクトを作成する必要があります。
プロジェクトの作成は、BigQueryの機能を使用するための必須条件です。
これを行うことで、データセットの管理やSQLクエリの実行ができます。
以下に、BigQueryプロジェクトの設定手順を詳しく解説します。
- BigQueryを選択
- プロジェクトを作成
- プロジェクト情報を入力
- SQLクエリの入力画面に移行
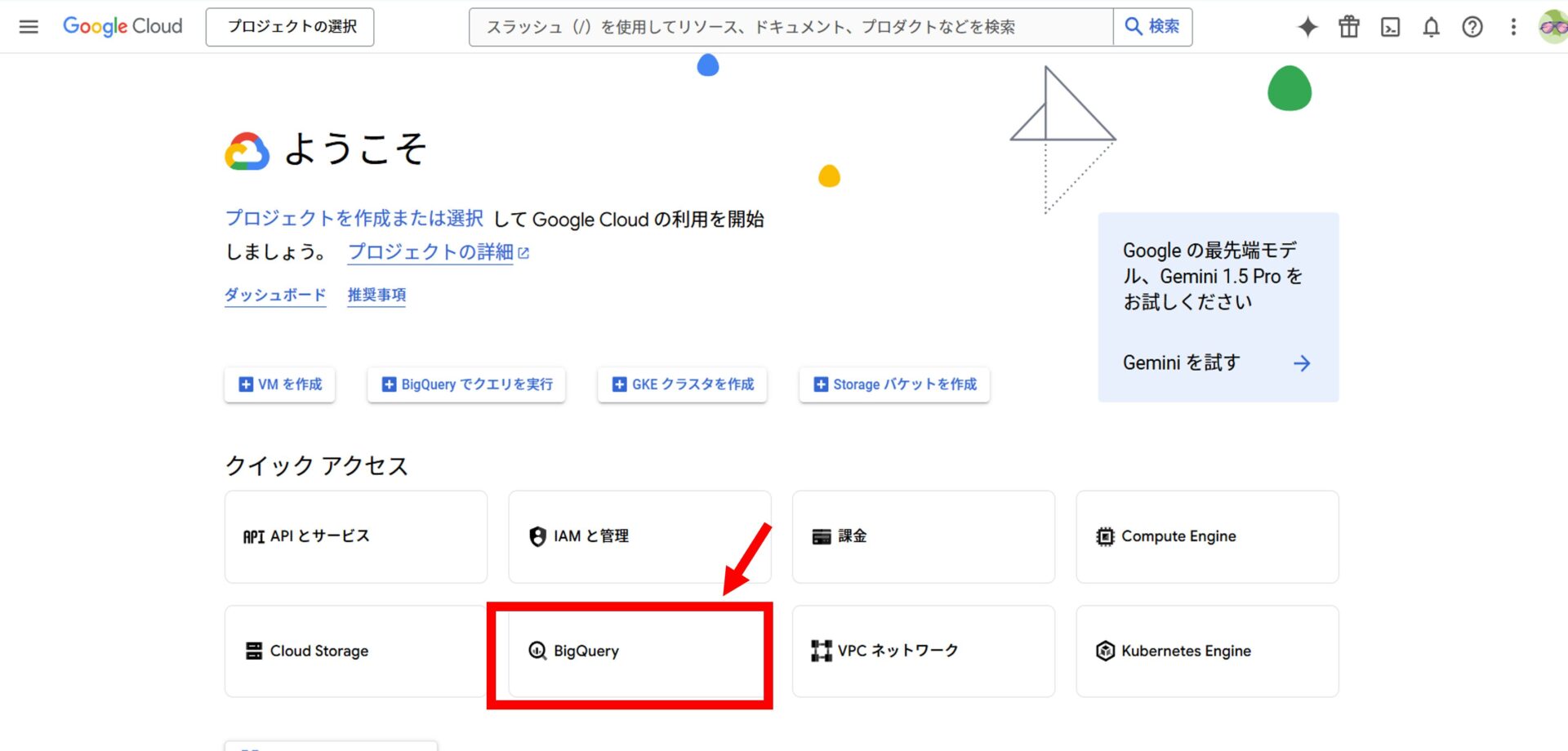
BigQueryを選択
Google Cloud Platformにアクセスして、メインダッシュボードから「BigQuery」を選択します。
クイックアクセスがない場合は検索窓から「BigQuery」を検索してください。
プロジェクトを作成
BigQuery Studioに移動すると、「プロジェクトを選択」または「プロジェクトの作成」ボタンが表示されます。
ここでは、新しくプロジェクトを作成していきます。
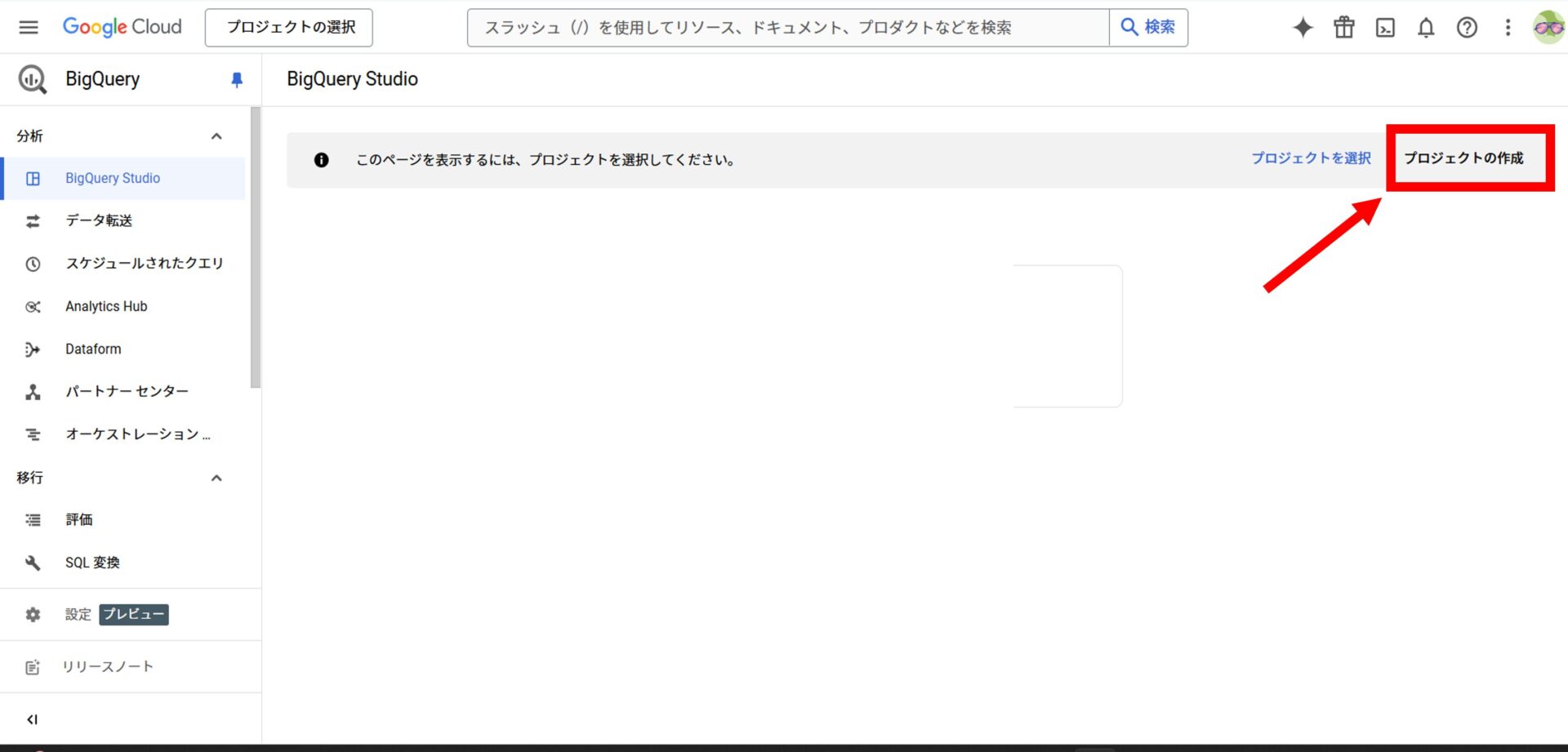
すでにプロジェクトを作成したことがある方も、この手順を参考にして進めてみてください。
プロジェクト情報を入力
新しいプロジェクト作成画面で、プロジェクト名を設定し、「組織なし」または既存の組織を選択します。
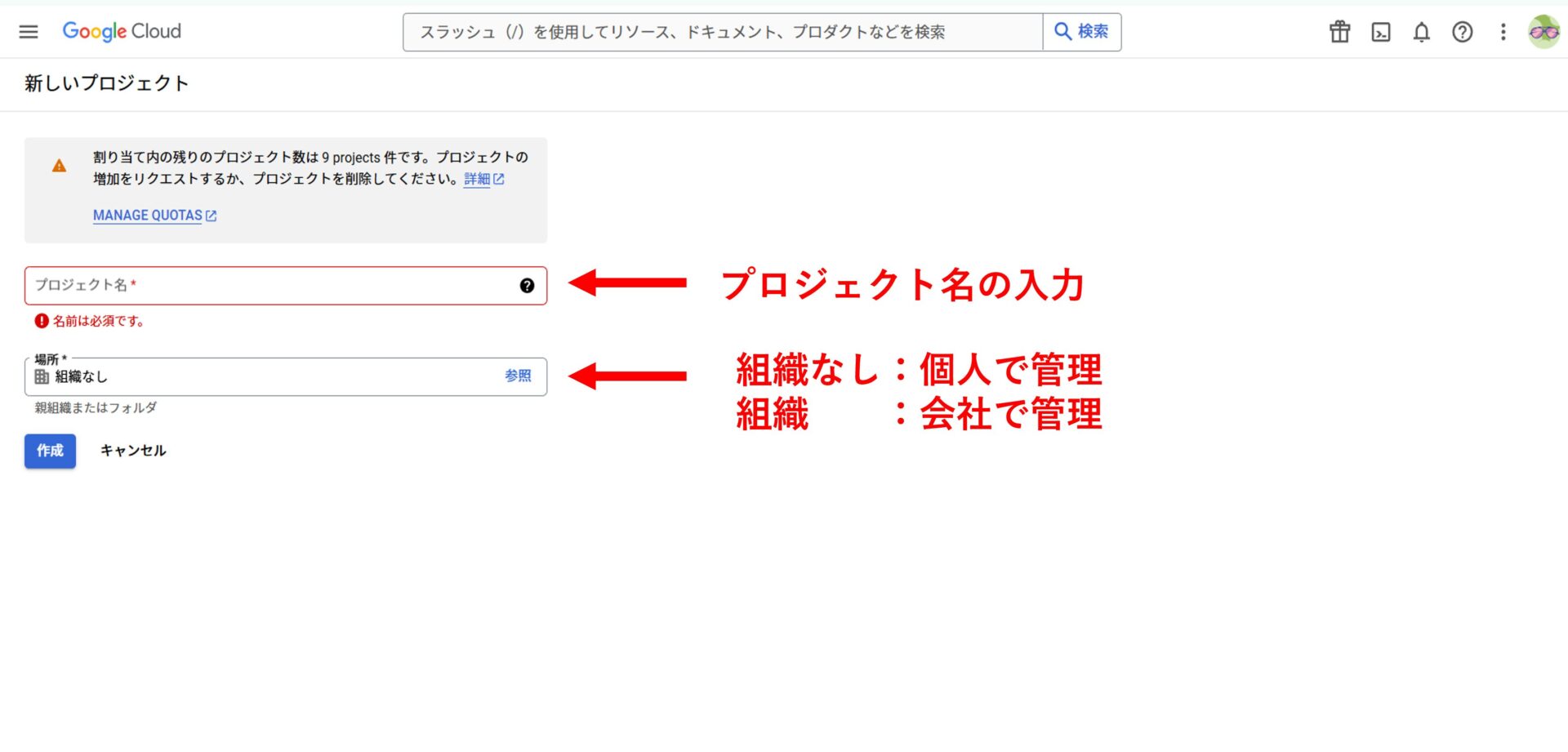
その後、必要な情報を入力して「作成」をクリックします。
SQLクエリの入力画面に移行
プロジェクトが作成されると、自動的にBigQueryのエクスプローラ画面に移動します。
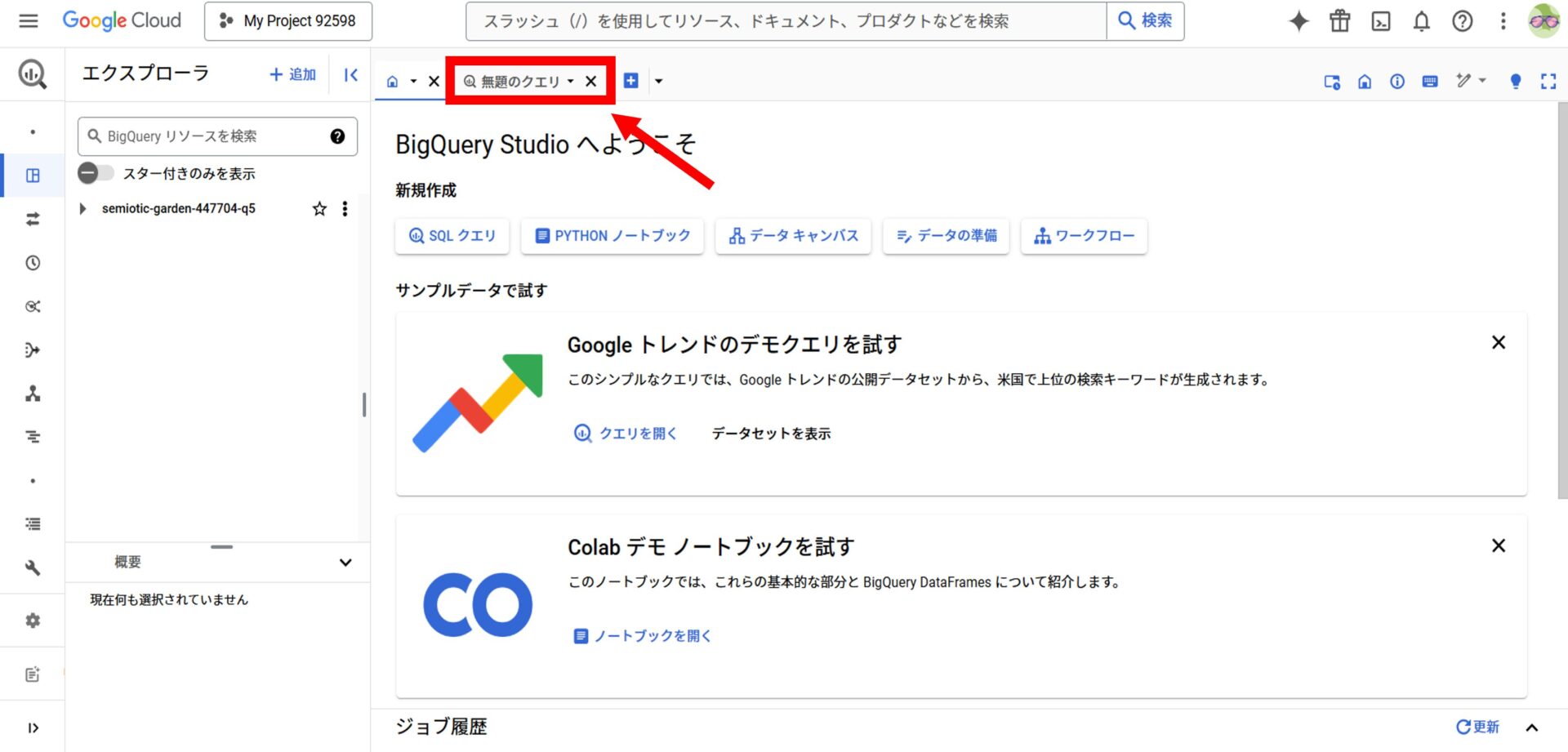
ここから、画面上部の「+ 無題のクエリ」をクリックしてクエリを開きます。
ChatGPTでSQLを生成しBigQueryで実行する手順
ChatGPTを使えば、SQLクエリの生成からBigQueryでの実行までの手順を紹介します。
- ChatGPTでSQLクエリを生成する
- 生成したSQLクエリをBigQueryに送信して実行する
ChatGPTとBigQueryを組み合わせることで、業務の効率化を実現し、迅速な意思決定に役立つデータ分析ができます。
それでは、最初のステップ「ChatGPTでSQLクエリを生成する」から始めましょう。
ChatGPTを活用してデータ分析を行う際のメリットやデメリットなどを詳しく知りたい方は、ぜひこちらの記事をご覧ください。
ChatGPTでSQLクエリを生成する
ChatGPTを使うことで、自然言語からSQLクエリを簡単に生成可能です。
SQLに詳しくない場合でも、ChatGPTが適切なクエリを作成してくれるため、簡単にデータ分析を始められます。
さらに、SQLの学習に時間をかけずに必要なクエリを素早く取得でき、データ分析の作業効率を大幅に向上できます。
以下の手順でSQLクエリを作成していきます。
- ChatGPTにSQLクエリを作成する指示を出す
- ChatGPTがSQLクエリを生成
- 生成されたSQLクエリをコピー
ChatGPTにSQLクエリを作成する指示を出す
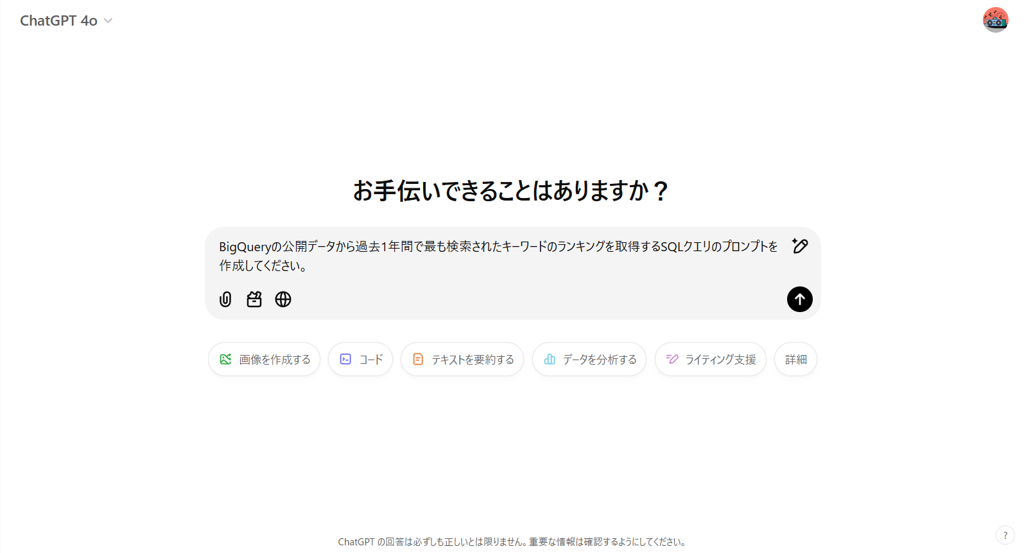
まず、ChatGPTにSQLクエリを作成する指示を出します。具体的な内容を伝えることで、必要なクエリを生成できます。
今回は以下のプロンプトを入力します。
BigQueryの公開データセットを使って、Googleトレンドデータから過去1年間の人気検索キーワードを取得するクエリを作成してください
ChatGPTがSQLクエリを生成
ChatGPTが指定した内容に基づいてSQLクエリを生成します。生成されたSQLクエリは画面上に表示されます。
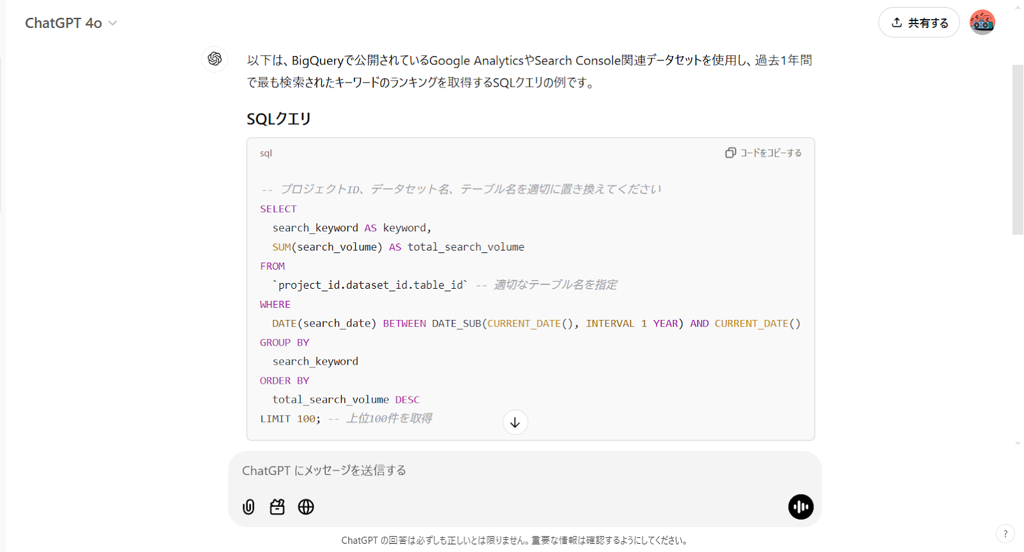
内容を確認して、必要に応じて修正点があれば再度指示を出して調整します。
生成されたSQLクエリをコピー
ChatGPTが生成したSQLクエリをコピーします。
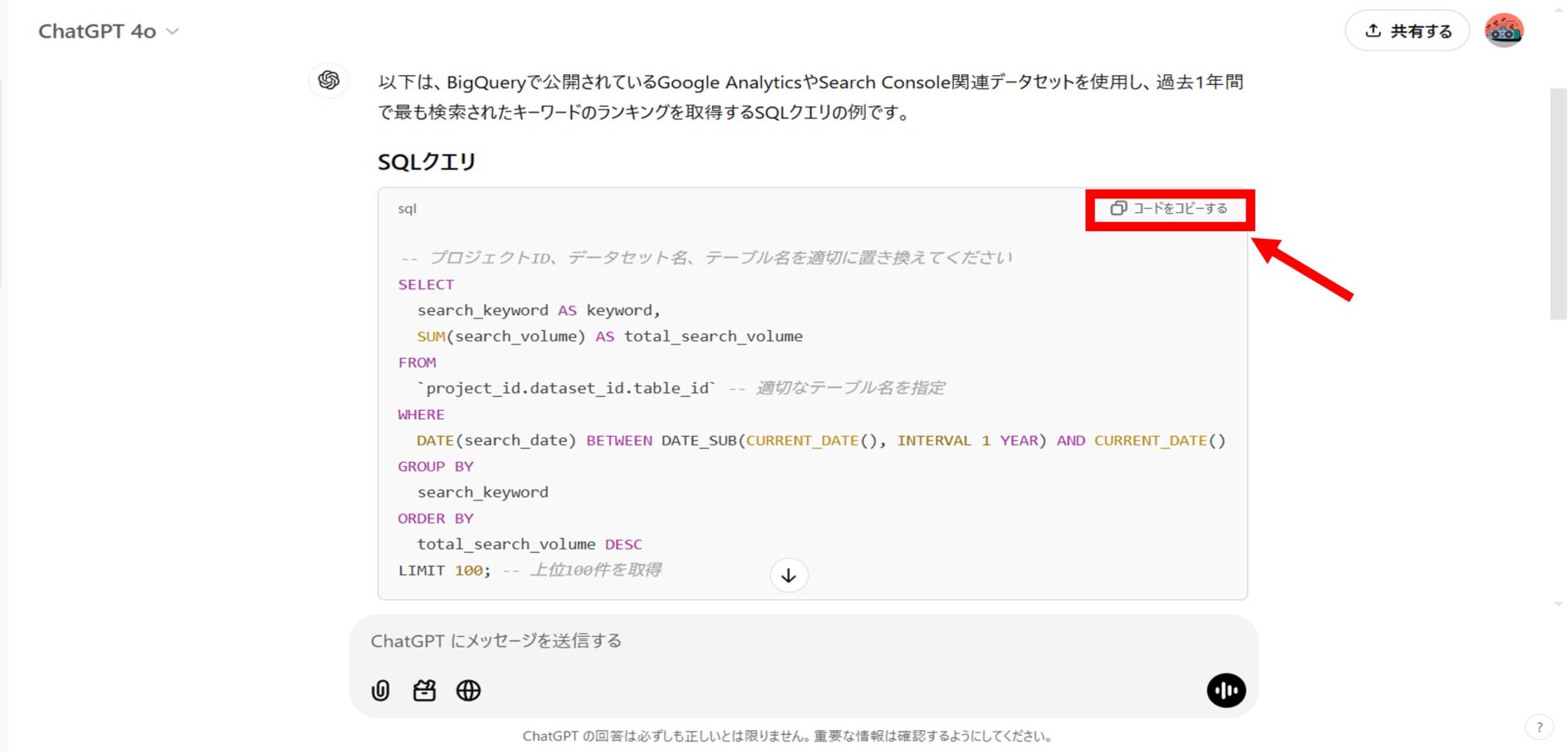
生成したSQLクエリをBigQueryに送信する
ChatGPTで生成したSQLクエリをBigQueryに送信し、データ分析を実行します。
BigQueryは大量データを短時間で処理できるため、効率的に分析結果を得ることができます。
以下の手順でBigQueryで実行していきます。
- SQLワークスペースを開く
- SQLを貼り付ける
- クエリを実行
SQLワークスペースを開く
Google Cloud Platformにアクセスし、「BigQuery」を選択してコンソールを開きます。
その後、先ほど作成したプロジェクトを選択し、画面上部に表示される「+ 無題のクエリ」をクリックしてSQLワークスペースを開きます。
SQLを貼り付ける
ChatGPTで生成したSQLクエリをコピーし、SQLワークスペースに貼り付けます。
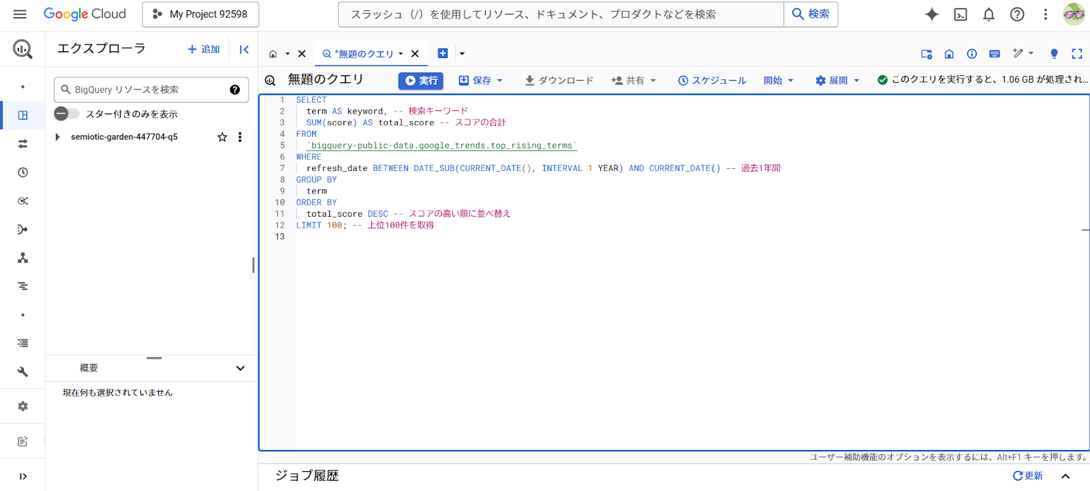
クエリを実行
SQLクエリを確認したら、画面上部の「実行」ボタンをクリックしてクエリを実行します。
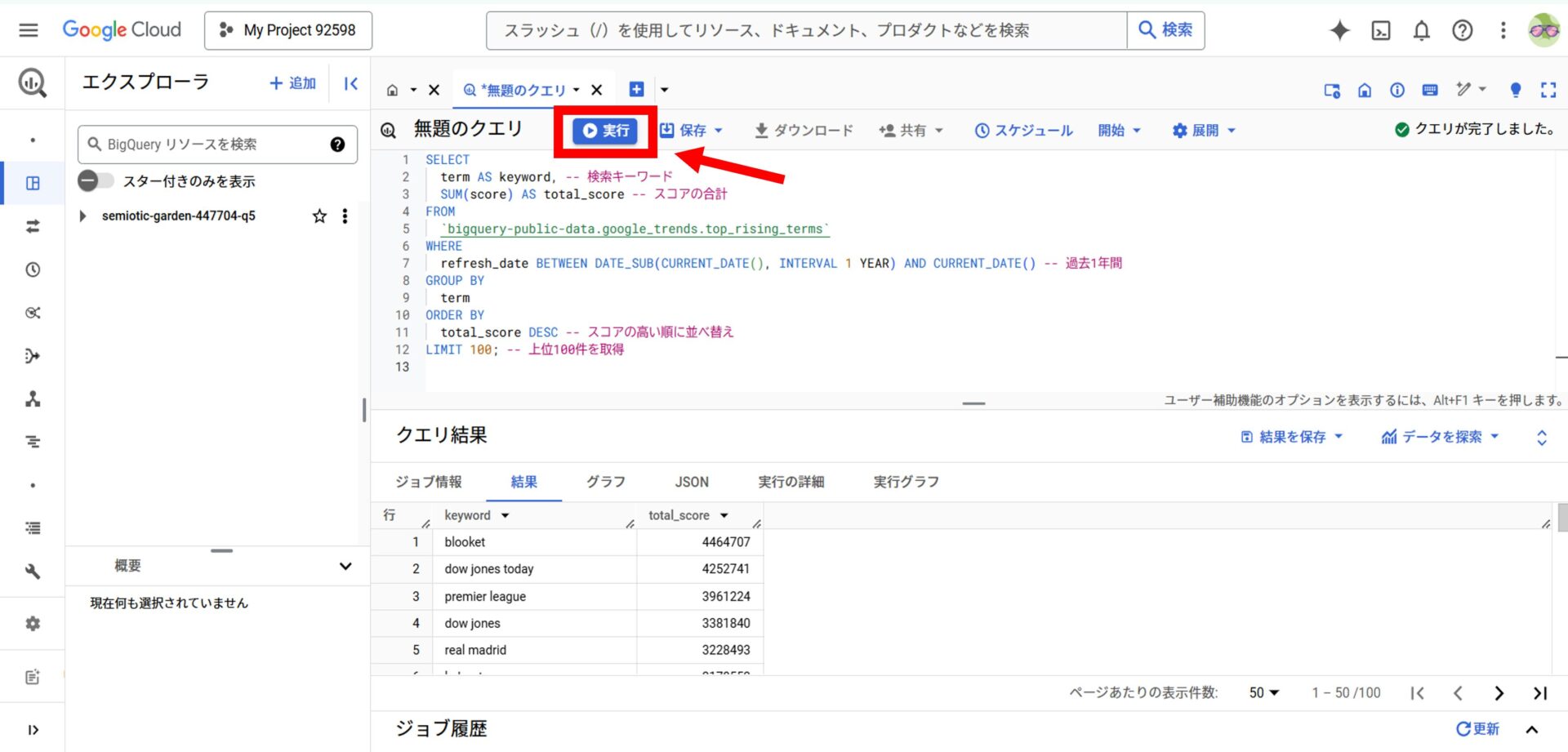
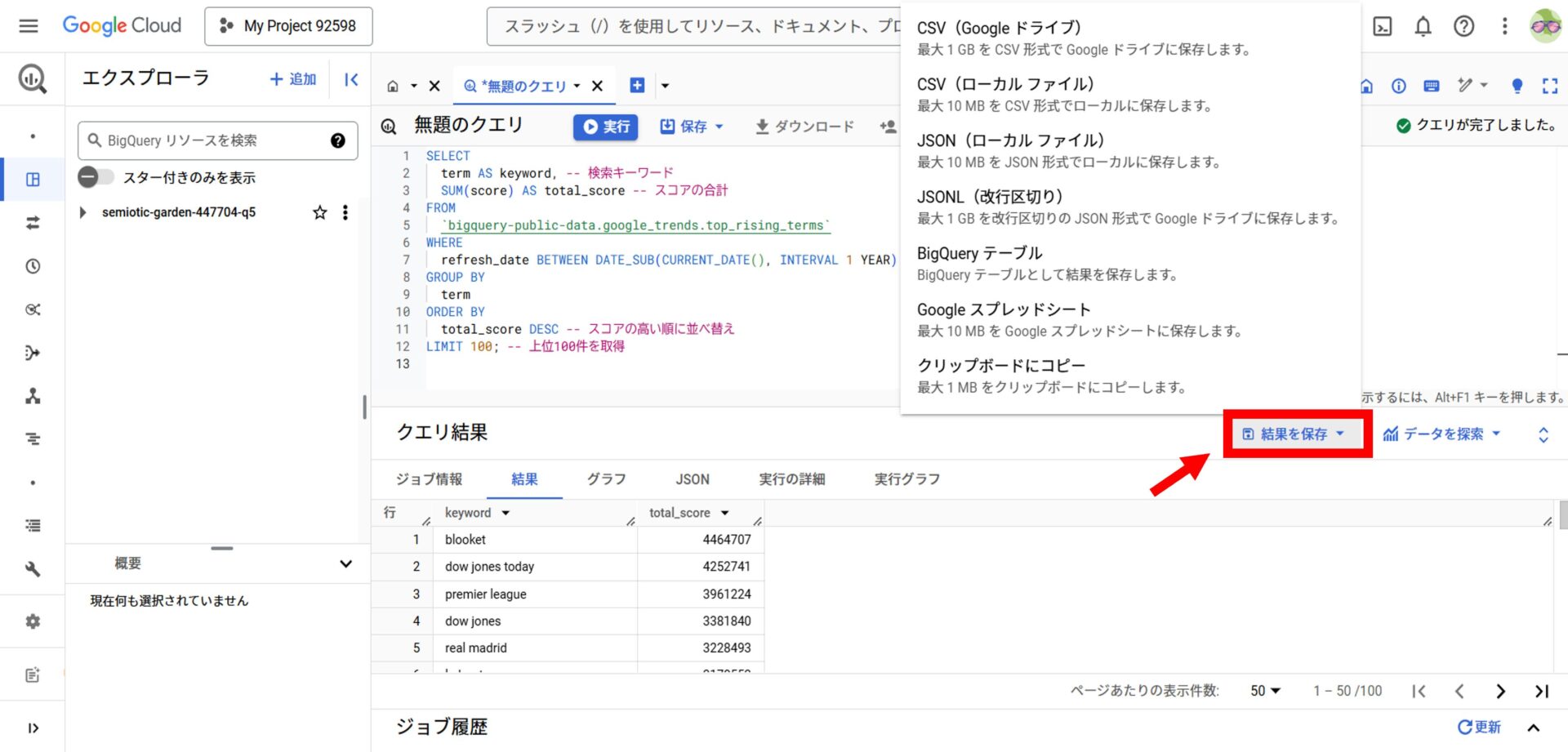
実行結果は画面下部に表示され、必要に応じて結果をダウンロードや保存することも可能です。
BigQueryに外部ファイルをインポートして分析する手順
前述では、BigQuery内のデータセットを活用してデータ分析を行う手順を紹介しましたが、BigQueryでは外部ファイルをインポートして分析を行うことも可能です。
ここでは、CSVやJSONなどの外部ファイルをBigQueryにインポートして実行する方法を解説します。
- 外部ファイルをインポートする
- ChatGPTに外部ファイルを入れて生成する
- 生成したSQLクエリをBigQueryに送信する
これから解説する手順を参考に、外部ファイルを効率的にインポートし、データ分析を始めましょう。
外部ファイルをインポートする
BigQueryに外部ファイルをインポートする手順は以下のとおりです。
- 外部ファイルを選択する
- データセットを作成する
- テーブルを作成する
外部ファイルを選択する
BigQueryコンソール内の「エクスプローラ」から「+ 追加」をクリックします。
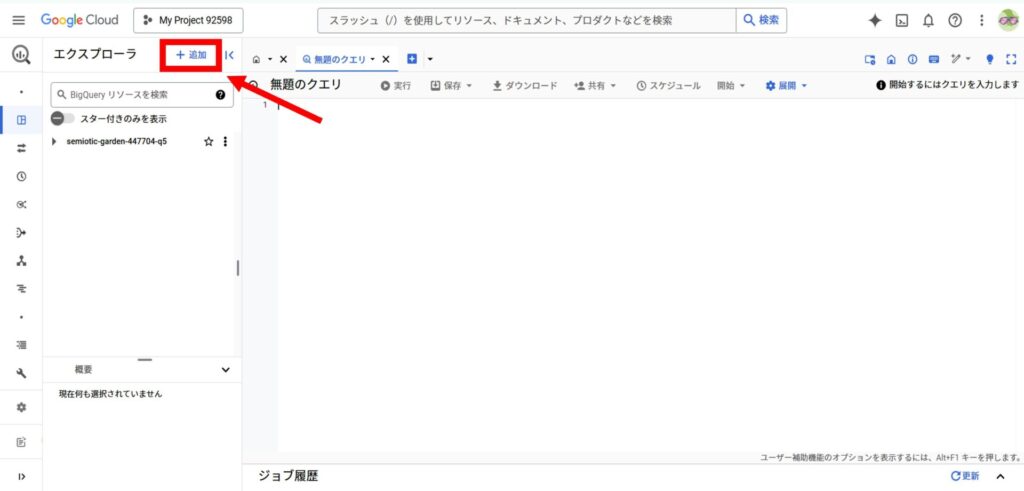
表示されるメニューから「ローカルファイル」を選択します。
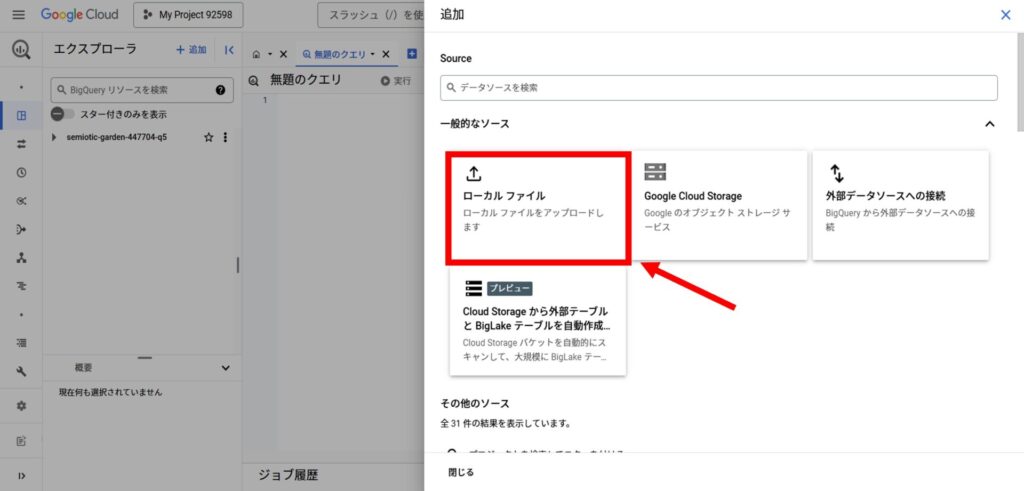
「ローカルファイル」を選択すると、ファイルアップロード画面が表示されます。
「ファイルを選択」の項目で自分のコンピュータ内のアップロードしたいファイルを選びます。

データセットを作成する
ファイルをアップロードする際に、保存先となるデータセットを作成する必要があります。

「データセット」を選択し、ドロップダウンメニューから「新しいデータセットの作成」を選択してください。
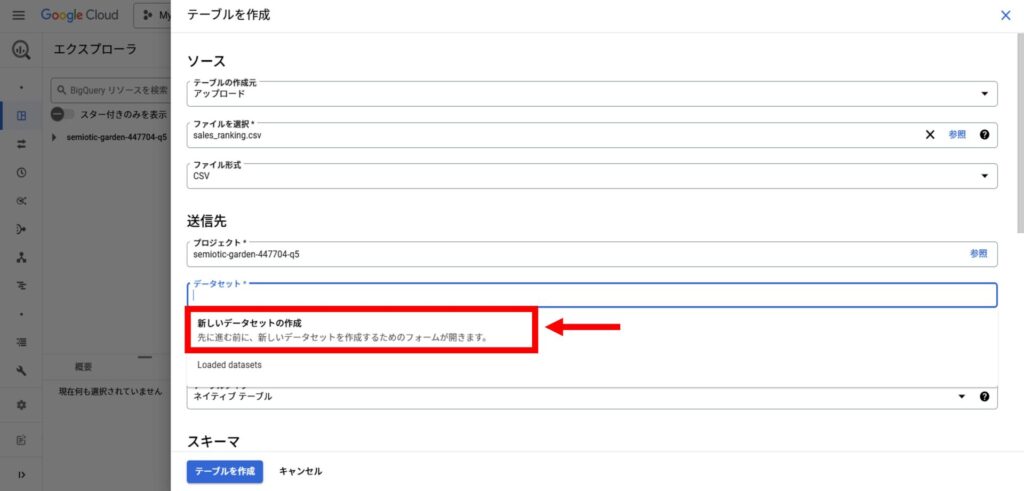
「新しいデータセットの作成」を選択すると、データセットIDを設定する画面が表示されます。
データセットID(例: data_set)を入力し、保存場所や有効期限の設定を必要に応じて行います。入力後「データセットを作成」ボタンを選択します。
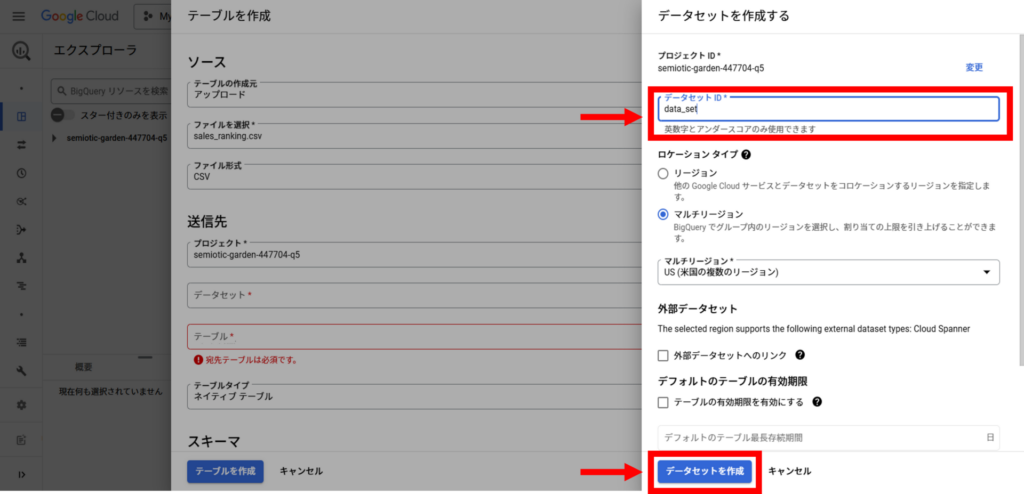
テーブルを作成する
データセットが選択されると、次にテーブルの作成を行います。
テーブル名を入力し、スキーマ設定で「自動検出」を選択します。
「テーブルを作成」を選択すると、CSVファイルが指定したデータセット内にアップロードされ、テーブルとして利用できます。

「テーブルに移動」から作成したテーブルの詳細を確認できます。
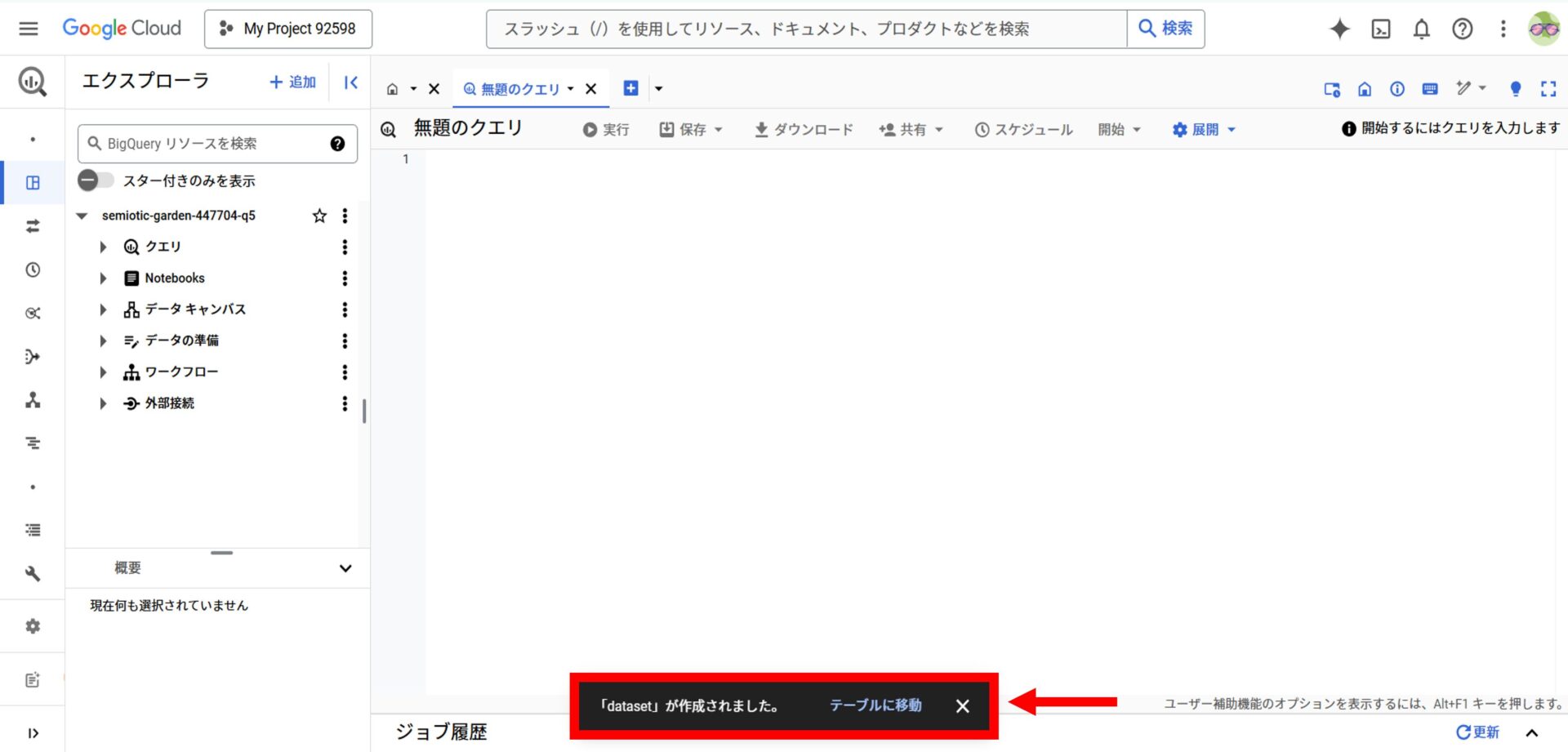
これで、外部ファイルのインポートが完了しました。
ChatGPTに外部ファイルを入れて生成する
使用する外部ファイルをChatGPTに添付し、そのデータを基にSQLクエリを作成します。以下の手順で進めてください。
- 外部ファイルをChatGPTに添付する
- SQLクエリ生成の指示を入力する
- 生成されたSQLクエリをコピー
外部ファイルをChatGPTに添付する
ChatGPTのプロンプトに使用するデータファイルを添付します。
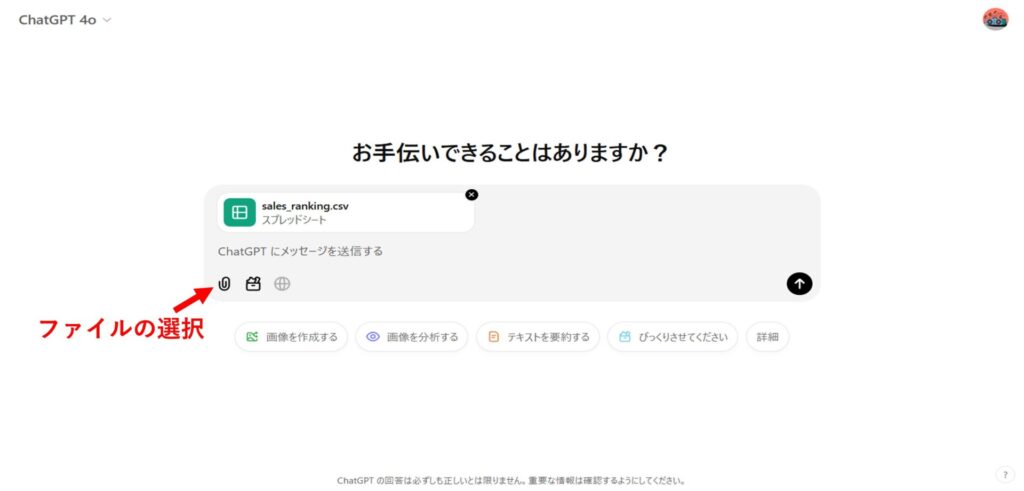
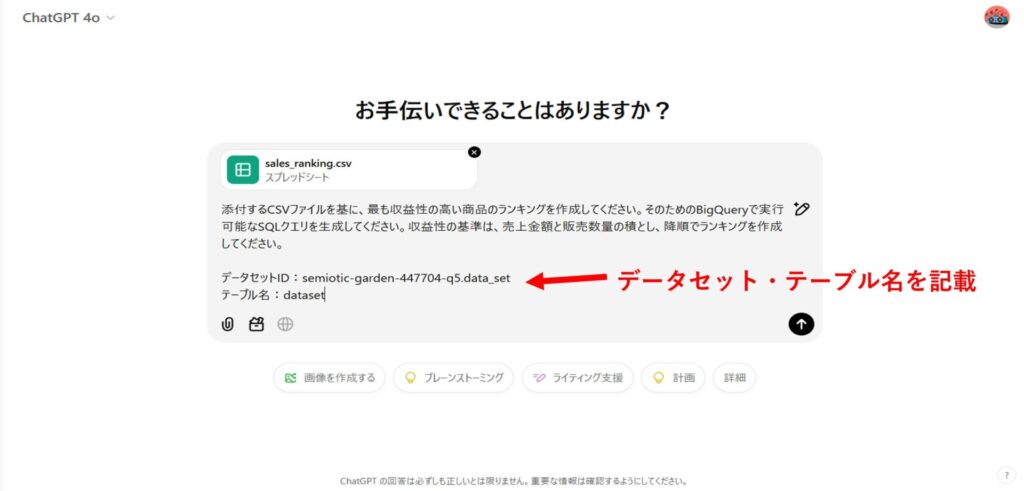
SQLクエリ生成の指示を入力する
今回は以下のプロンプトを入力します。
添付するCSVファイルを基に、最も収益性の高い商品のランキングを作成してください。そのためのBigQueryで実行可能なSQLクエリを生成してください。収益性の基準は、売上金額と販売数量の積とし、降順でランキングを作成してください。
データセットID:semiotic-garden-447704-q5.data_set
テーブル名:dataset※データセットIDやテーブル名は、BigQueryでデータをインポートした際に設定した値を使用してください。
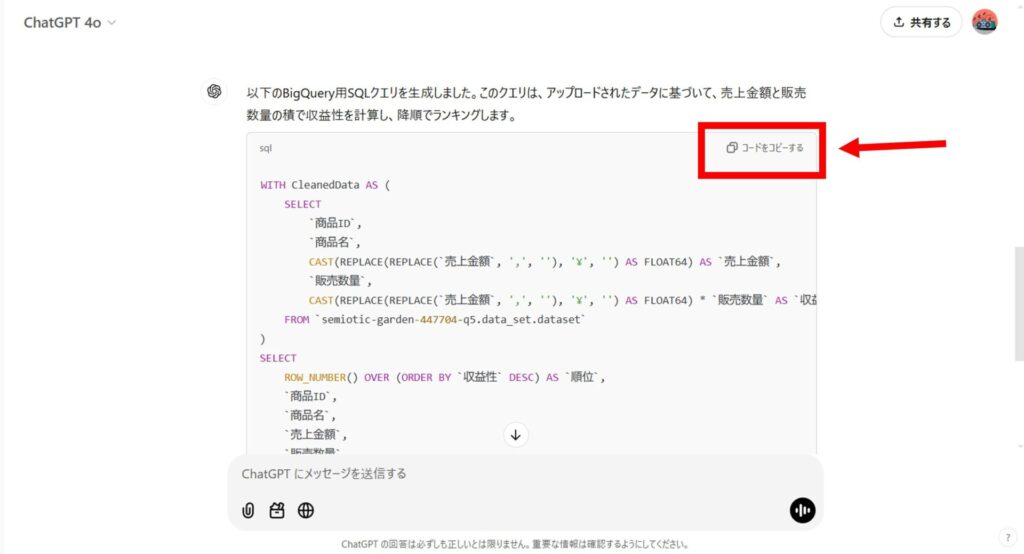
生成されたSQLクエリをコピー
ChatGPTが生成したSQLクエリをコピーします。
生成したSQLクエリをBigQueryに送信する
ChatGPTで生成したSQLクエリをBigQueryで実行します。以下の手順を通じて、外部データを活用したデータ分析が可能です。
- ChatGPTで生成したSQLクエリを貼り付ける
- クエリを実行
ChatGPTで生成したSQLクエリを貼り付ける
先ほど生成したSQLクエリをBigQueryに貼り付けます。
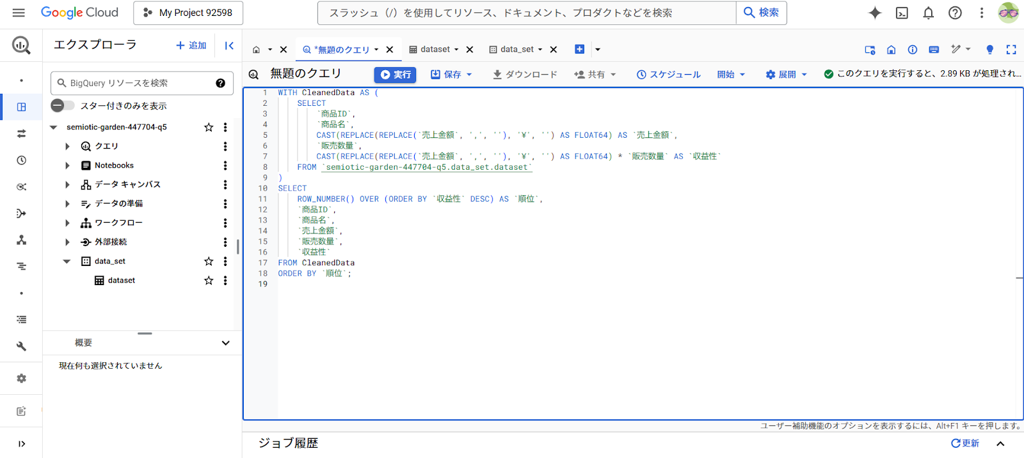
クエリを実行
SQLクエリの貼り付け後、画面上部の「実行」ボタンをクリックしてクエリを実行します。
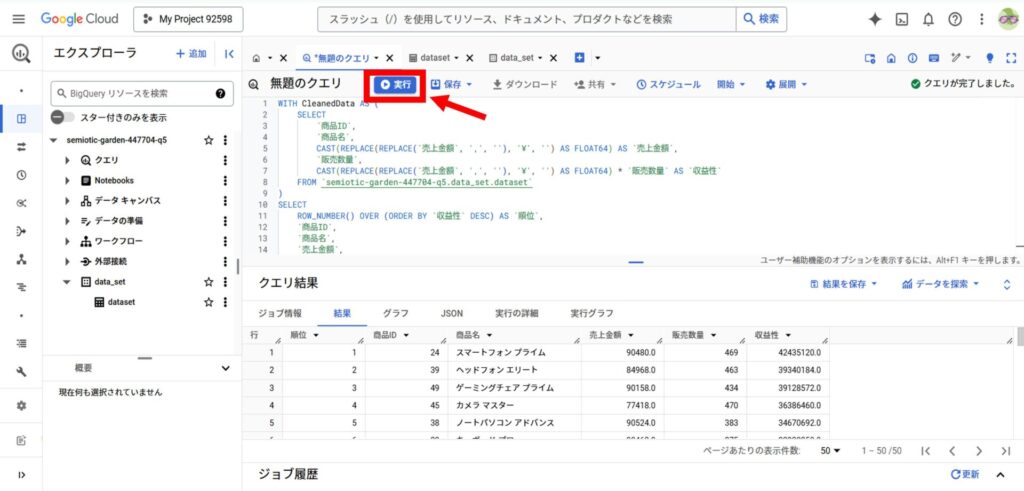
【実践】ChatGPTで生成したSQLをBigQueryで活用する事例3選
ChatGPTで生成したSQLをBigQueryで活用すれば、複雑なデータ分析が効率的に行えます。
- 売上データからの自動ランキング作成
- 顧客データを基にしたターゲットリストの生成
- 広告パフォーマンスデータの可視化サポート
これらの活用事例を参考にすることで、ChatGPTとBigQueryの組み合わせが業務効率化にどのように役立つか具体的に理解できます。
それでは、3つの事例を詳しく見ていきましょう。
売上データからの自動ランキング作成
架空の売上データを基に、自動でランキングを作成する仕組みを構築しました。
手作業でデータを分析してランキングを作成するのは非効率ですが、ChatGPTでSQLを生成しBigQueryで実行することで、作業を効率化できます。
ChatGPTに次のように依頼しました。
添付するCSVファイルを基に、最も収益性の高い商品のランキングを作成してください。そのためのBigQueryで実行可能なSQLクエリを生成してください。
収益性の基準は、売上金額と販売数量の積とし、降順でランキングを作成してください。
データセットID:semiotic-garden-447704-q5.data_set
テーブル名:dataset※今回使用してるデータセットIDは使用できません。
以下はChatGPTが生成したSQLクエリです。
WITH CleanedData AS (
SELECT
`商品ID`,
`商品名`,
CAST(REPLACE(REPLACE(`売上金額`, ',', ''), '¥', '') AS FLOAT64) AS `売上金額`,
`販売数量`,
CAST(REPLACE(REPLACE(`売上金額`, ',', ''), '¥', '') AS FLOAT64) * `販売数量` AS `収益性`
FROM `semiotic-garden-447704-q5.data_set.dataset`
)
SELECT
ROW_NUMBER() OVER (ORDER BY `収益性` DESC) AS `順位`,
`商品ID`,
`商品名`,
`売上金額`,
`販売数量`,
`収益性`
FROM CleanedData
ORDER BY `順位`;この結果、以下のようなランキング表を得られました。
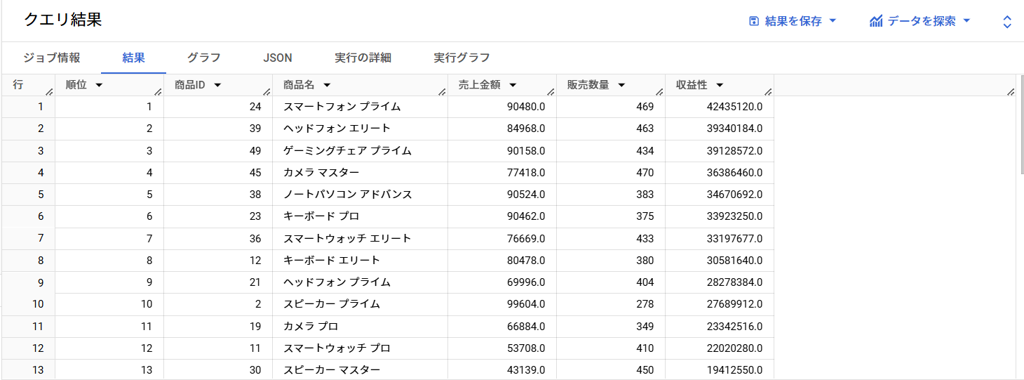
この方法は、売上データの中から収益性の高い商品を迅速に特定できるため、販売促進活動や在庫管理の優先順位を明確にできます。
顧客データをもとにしたターゲットリストの生成
架空の顧客データを分析し、特定の条件に合致するターゲットリストを自動生成しました。
条件に合うお客様を絞り込むことで、無駄を省いたキャンペーンの案内ができます。
以下は、30代の女性で、過去6ヶ月以内に購入歴があるお客様を対象としたリスト作成の例です。
ChatGPTに次のように依頼しました。
添付するCSVファイルを基に、30代の女性で、過去6ヶ月以内に購入歴があるお客様のリストを抽出するためのSQLクエリを生成してください。
データセットID:semiotic-garden-447704-q5.data_set
テーブル名:dataset※今回使用してるデータセットIDは使用できません。
以下はChatGPTが生成したSQLクエリです。
WITH CleanedData AS (
SELECT
`顧客ID`,
`性別`,
CAST(`年齢` AS INT64) AS `年齢`,
`購入日時`
FROM `semiotic-garden-447704-q5.data_set.dataset`
)
SELECT DISTINCT
`顧客ID`,
`性別`,
`年齢`,
`購入日時`
FROM CleanedData
WHERE `性別` = '女性'
AND `年齢` BETWEEN 30 AND 39
AND DATE(`購入日時`) >= DATE_SUB(CURRENT_DATE(), INTERVAL 6 MONTH)
ORDER BY `購入日時` DESC;BigQueryで実行した結果です。
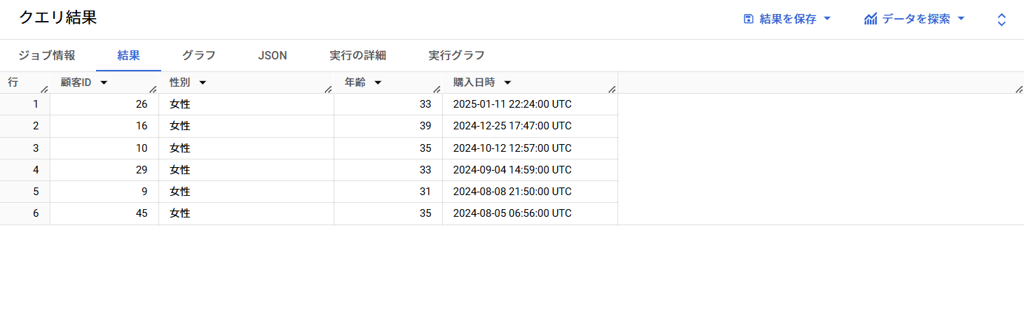
このようなターゲットリストを作成することで、特定のお客様に合わせたキャンペーンの実施ができます。
広告パフォーマンスデータの可視化サポート
広告パフォーマンスのデータを視覚的に整理することで、効果の高い広告や改善が必要な広告を簡単に把握できる仕組みを作りました。
数値だけでは広告の効果をイメージしにくいですが、可視化を通じてデータをグラフ化することで、意思決定がしやすいです。
ChatGPTに次のように依頼しました。
添付するCSVファイルを基に、クリック率(CTR)やコンバージョン率を計算し、それらを広告ごとに比較するSQLクエリを生成してください。また、上位の広告を効果順に並べてください。
データセットID:semiotic-garden-447704-q5.data_set
テーブル名:dataset※今回使用してるデータセットIDは使用できません。
以下はChatGPTが生成したSQLクエリです。
-- データセットIDとテーブル名を指定
WITH ad_data AS (
SELECT
`キャンペーン名`, -- 正しい列名に修正
SUM(`インプレッション数`) AS `インプレッション数`,
SUM(`クリック数`) AS `クリック数`,
SUM(`コンバージョン数`) AS `コンバージョン数`,
SUM(`広告費`) AS `広告費` -- 広告費用を広告費に修正
FROM
`semiotic-garden-447704-q5.data_set.dataset`
GROUP BY
`キャンペーン名`
)
SELECT
`キャンペーン名`,
`インプレッション数`,
`クリック数`,
`コンバージョン数`,
ROUND((`クリック数` / `インプレッション数`) * 100, 2) AS `クリック率`, -- CTR
ROUND((`コンバージョン数` / `クリック数`) * 100, 2) AS `コンバージョン率`, -- Conversion Rate
`広告費`,
ROUND(`広告費` / `コンバージョン数`, 2) AS `コンバージョン単価` -- Cost per Conversion
FROM
ad_data
ORDER BY
`クリック率` DESC, -- クリック率で降順
`コンバージョン率` DESC; -- コンバージョン率で降順(CTRが同率の場合)BigQueryで実行した結果です。
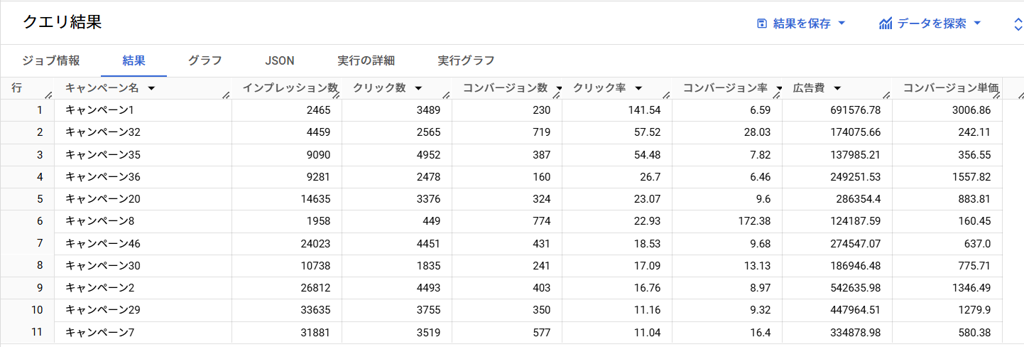
以下は、表のデータを可視化したグラフです。
※ヘッダーのグラフを選択
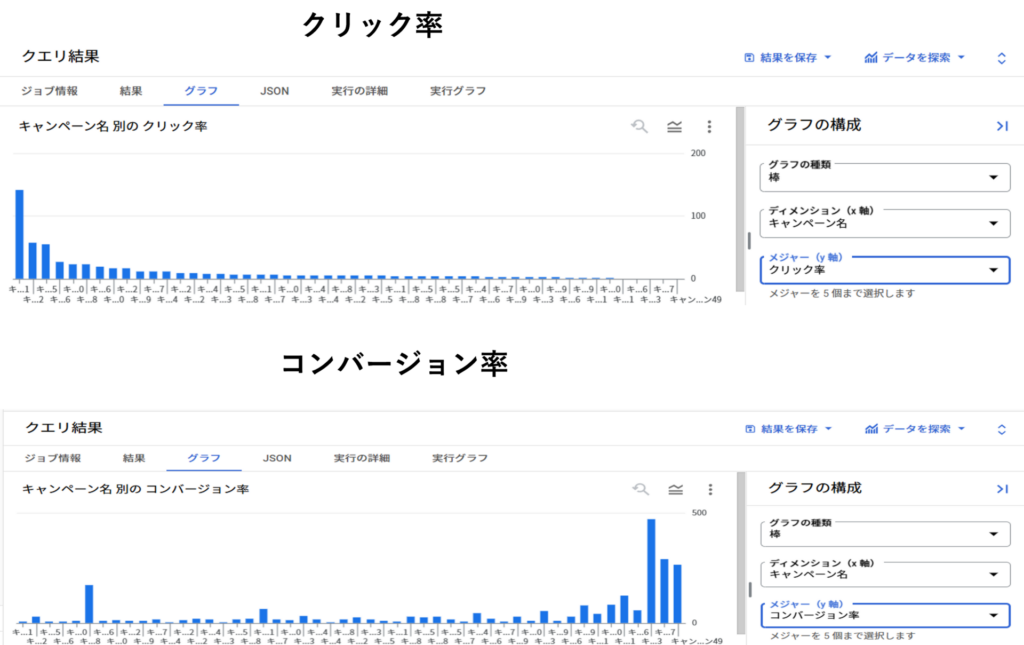
このような可視化があれば、どの広告に予算を割くべきか、どのキャンペーンが成功しているのかを即座に判断できます。
他にも、特定の地域や時間帯でのパフォーマンスデータを追加することで、さらに精緻な分析が可能です。
ChatGPTとBigQueryを使う際の注意点
ChatGPTとBigQueryを組み合わせて利用する際には、その便利さだけでなく、注意すべき点も押さえておく必要があります。
- 大量データの処理コストに注意
- 生成されたSQLの正確性に注意
注意点を知ることで、無駄を省き、より安定したデータ活用が可能です。
まずは、「大量データの処理コスト」に関する注意点を確認してみましょう。
大量データの処理コストに注意
BigQueryで大量データを処理する際には、予想外の高額なコストが発生しないよう注意が必要です。
BigQueryは従量課金制で、処理するデータ量に応じて料金が発生します。
不必要なデータを読み込むクエリを実行すると、想定外の料金がかかります。
たとえば、「SELECT *」を使うと不要なデータまで処理対象になり、コストが増えます。
必要な列だけを指定することで処理量を減らせます。
さらに、WHERE句で「2023年のデータだけ」など条件を絞り込むと、無駄な処理を防ぎ、コストを抑えられます。
コストを管理しながら、効率的なデータ活用を進めていきましょう。
ChatGPTが生成したSQLクエリの正確性に注意
ChatGPTが生成するSQLクエリが必ずしも正確であるとは限らないため、注意が必要です。
ChatGPTは自然言語をもとにSQLを生成しますが、データベースの構造やテーブル名、列名が間違っている場合や、意図にそぐわないクエリが作られることがあります。
たとえば、ChatGPTに「2023年の売上トップ10の商品を取得するクエリを作成して」と指示すると、生成されたSQLに実際のデータベースに存在しないテーブル名や列名が含まれることがあります。
この場合、そのまま実行するとエラーが発生するため、クエリを実行する前にテーブルや列名が正しいか確認する必要があります。
生成されたSQLを事前に確認し、修正を加える習慣をつけることで、エラーや不正確な分析を防ぐことができます。
Gemini in BigQueryを活用して作成する方法
ChatGPT以外にも、2024年8月に一般提供されたGemini in BigQueryを活用して作成することもできます。
Gemini in BigQueryはGoogleが提供する生成AIで、自然言語プロンプトからSQLやPythonコードを生成し、データ分析やインサイト発見を効率化します。
たとえば、「2023年の売上を月ごとに集計してグラフを作成してください」と指示すると、Geminiが自動でSQLを作成し、実行結果をグラフ化します。
ChatGPTとGemini in BigQueryを併用することで、より簡単にデータ分析を行えます。
BigQueryを使いこなしてデータ分析を始めよう!
ChatGPTを活用することで、自然言語からSQLクエリを生成し、BigQueryを使って簡単にデータ分析ができます。
ChatGPTを使ってSQLクエリを作成してみたい」「BigQueryでデータ分析を始めてみたい」という方は、本記事を参考に、試してみてください。
専門知識がなくても、ChatGPTとBigQueryを活用して効率的にデータ分析ができると知り、可能性を感じた方も多いのではないでしょうか。
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
30秒で簡単受取!
無料で今すぐもらう

執筆者

西啓汰
フリーランスのSEO/AIライターとして活動。
生成AIツールを実際に検証し、その知見をもとに実務で活用できる情報発信を行っている。
AI関連の最新動向や活用ノウハウを、初心者にもわかりやすく伝えるコンテンツ制作が強み。
趣味は野球観戦とラジオ聴取。











30秒で簡単受取!
無料で今すぐもらう