share



Stable Diffusionの使い方完全解説!インストール・操作方法・モデル選びと商用利用のポイント

AI画像生成技術に興味があるけれど、「Stable Diffusionって難しそう」「インストールや使い方がわからない」と感じていませんか?
多くの人が不安を同様の不安を抱えており、せっかくの機会を逃してしまっています。
本記事では、Stable Diffusionの使い方を初心者にもわかりやすく解説します。
インストール方法から基本的な操作、プロンプトの書き方、上級者向けの設定まで、段階的に学べる内容です。
この記事を読むことで、あなたもStable Diffusionを自在に操り、創造性豊かな画像を生成できるようになるでしょう。

監修者
SHIFT AI代表 木内翔大
2026年5月30日(土)、SHIFT AI × romptn ai「クリエイターセミナー」を開催します!
第一線で活躍中のクリエイターが、最新の画像生成AIを使いながら、画像生成AIを活用した収益化についてお話しします。
無料で参加していただけますので、「画像生成AIを使って収益化したい!」「SNSで投稿したい!」という方は、ぜひ以下のボタンからセミナーにご参加ください。
Stable Diffusion WEB UIのインストール方法
Stable Diffusionは、誰でも無料で自由に使えるオープンソースの画像生成AIとして注目されています。
WEB UIをインストールすることで、画像生成をスムーズに開始可能です。
本章では、Stable DiffusionをWindowsとMacにインストールする手順を、以下の4つにわけて詳しく説明します。
- Stable DiffusionのWindowsへのインストール方法
- Stable DiffusionのMacへのインストール方法
- Windows環境でのアップデート方法
- Mac環境でのアップデート方法
本章で解説するStable Diffusion WEB UI「AUTOMATIC1111」は、2024年7月リリースのv1.10.0 以降更新がありません。
後述する『Stable Diffusionのインストールを簡単にするツール一覧』で紹介している、最新の状況に対応したEasy ForgeやEasy Reforgeのインストールをおすすめします。
Stable DiffusionのWindowsへのインストール方法
Stable Diffusion WEB UI(AUTOMATIC1111)をWindowsにインストールする方法は、以下のとおり比較的簡単です。
- GitHubからAUTOMATIC1111のリポジトリをクローンまたはダウンロード
- ダウンロードしたZIPファイルを任意の場所に解凍
- Pythonをインストール
- WEB UIの起動
AUTOMATIC1111版のインストール手順をくわしく説明します。
GitHubからAUTOMATIC1111のリポジトリをクローンまたはダウンロード
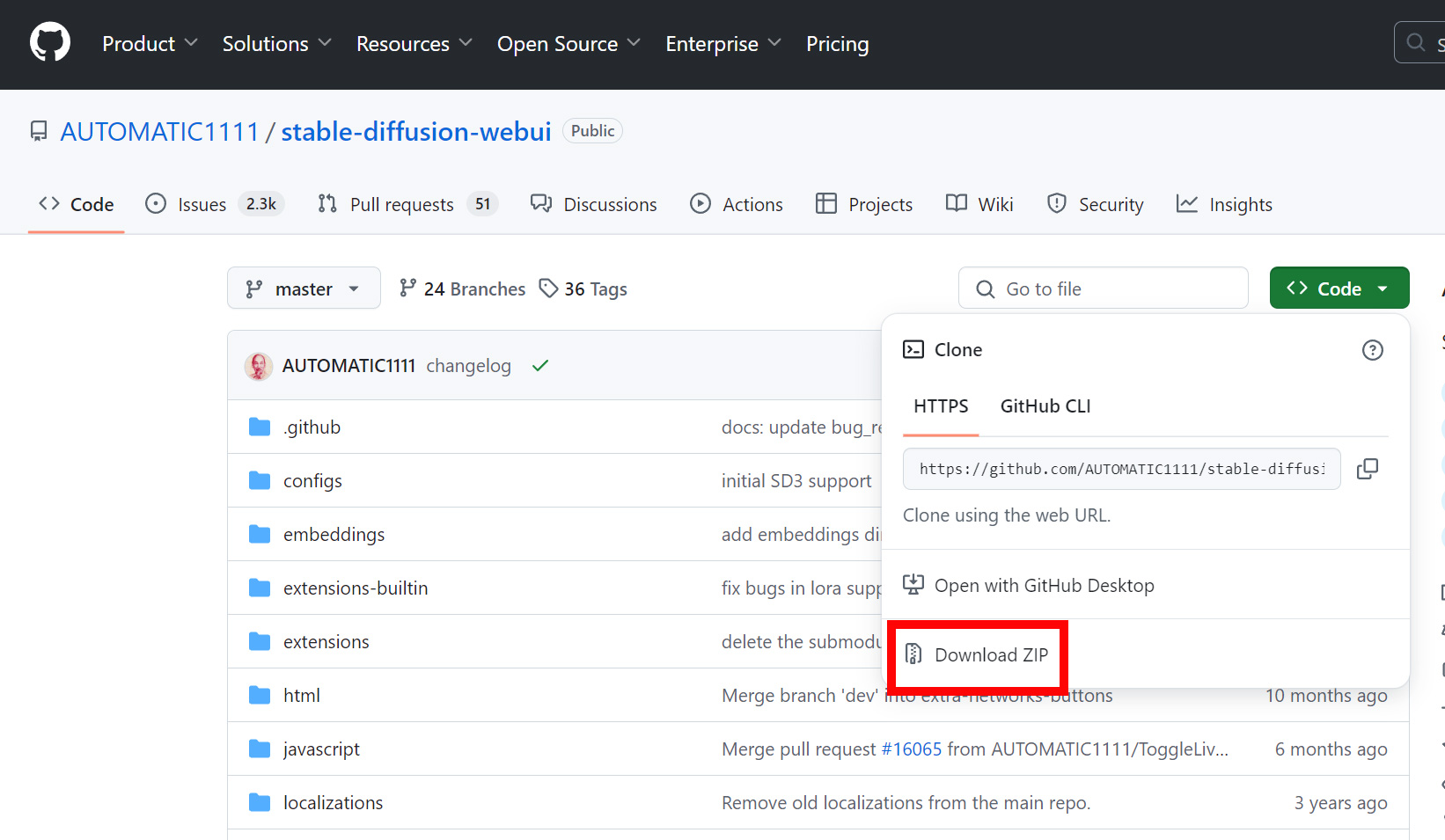
GitHubのページから「Code」ボタンをクリックし、「Download ZIP」を選択してファイルをダウンロードします。
>AUTOMATIC1111のダウンロードはこちら
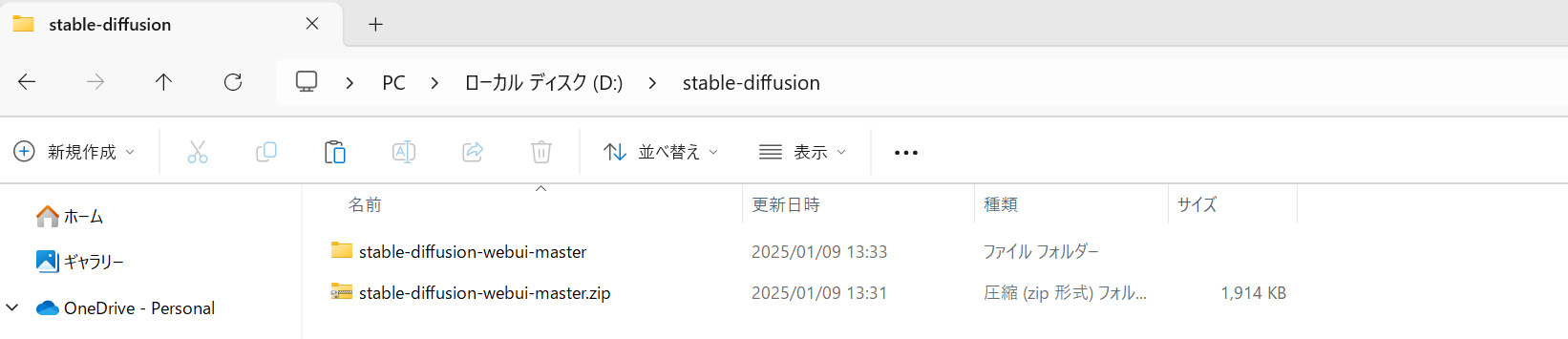
ダウンロードしたZIPファイルを任意の場所に解凍
「C:\stable-diffusion」のようなフォルダを作成し、解凍してください。
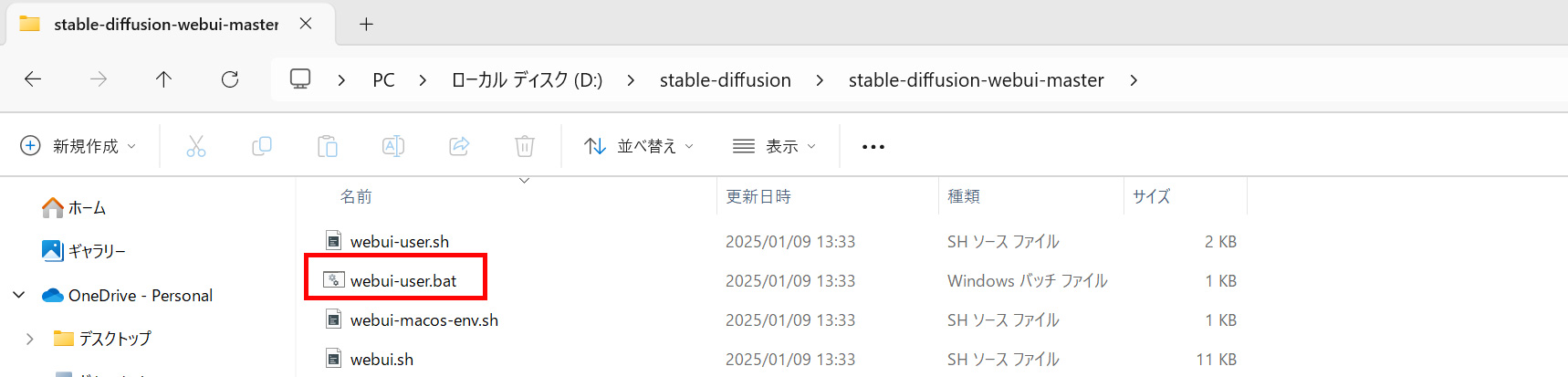
WEB UIの起動
解凍したフォルダ内にある「webui-user.bat」ファイルをダブルクリックして実行します。
初回実行時は、必要な依存関係がダウンロードされるため、処理が完了するまで時間を要することがあります。

インストールが完了すると、自動的にWebブラウザが起動し、Stable Diffusion WEB UIのインターフェースが表示されます。
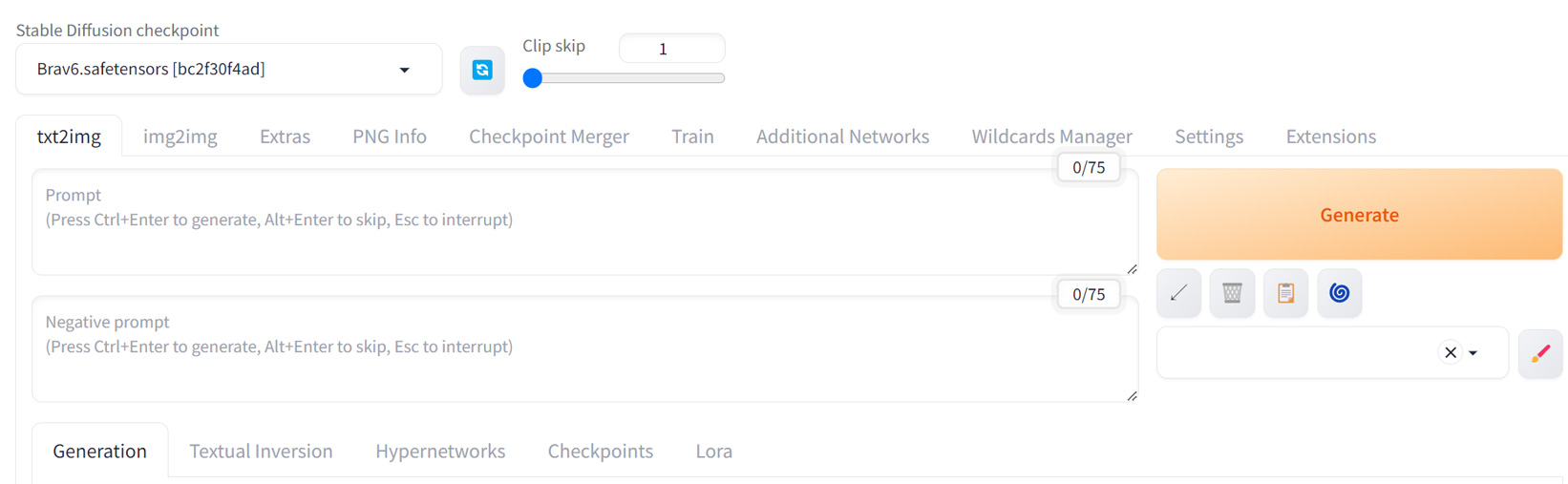
以上で、Windowsでの基本的なセットアップは完了です。インストールが完了すると、自動的にWebブラウザが起動し、Stable Diffusion WEB UIのインターフェースが表示されます。
最後に、生成モデルをダウンロードする必要があります。モデルは「models/Stable-diffusion」フォルダに配置してください。
たとえば、Civitaiなどのサイトから適切なモデルをダウンロードし、このフォルダに配置することで使用できます。
初回の設定後は、「webui-user.bat」を実行するだけで、Stable Diffusionを起動できます。
Stable DiffusionのMacへのインストール方法
Stable Diffusion WEB UIのMacへのインストールは、ターミナルを使用しインストールします。手順は以下の通りです。
- ターミナルを開き、以下を入力してHomebrewをインストール
- PythonとGitのインストール
- Stable Diffusionリポジトリのクローン
- 必要なモデルファイルをダウンロード
- 必要な依存関係のインストール
- 起動
まずはターミナルを開き、以下を入力してHomebrewをインストールします。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"次に、ターミナルで以下を実行してPythonとGitをインストールします。
brew install python gitインストール後、「python3 –version」と「git –version」で確認してください。
確認したのち、Stable Diffusionリポジトリをクローンします。ダウンロードと移動、起動スクリプトの実行権限付与を行いましょう。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui次に、必要なモデルファイル(例: model.ckptまたはmodel.safetensors)をダウンロードします。「stable-diffusion-webui/models/Stable-diffusion」フォルダに配置します。
配置したら、必要な依存関係のインストールを行いましょう。
python3 -m pip install -r requirements.txt最後に起動して完了です。
python3 launch.pyWindows環境でのアップデート方法
Windows環境でのアップデート手順は以下のとおりです。
- Web UIを終了
- webui-user.batをダブルクリック
- 自動的に更新の確認と適用が行われます
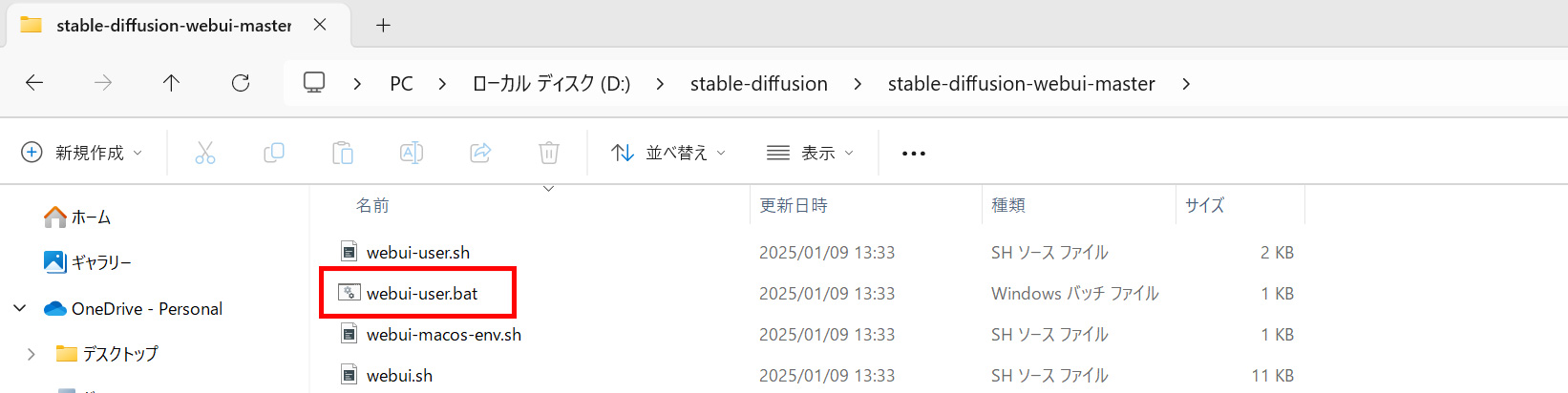
また、拡張機能の更新は以下の手順で行いましょう。
Web UIを起動- Extensionsタブを開く
- 「Check for updates」をクリック
- 更新がある場合は「Apply and restart UI」をクリック
Mac環境でのアップデート方法
Mac環境でのアップデート手順は以下のとおりです。
- ターミナルを開く
- cd ~/Documents/stable-diffusion-webuiでインストールしたディレクトリに移動
- git pullでポジトリのアップデート情報を取得
- ./webui.sh を実行
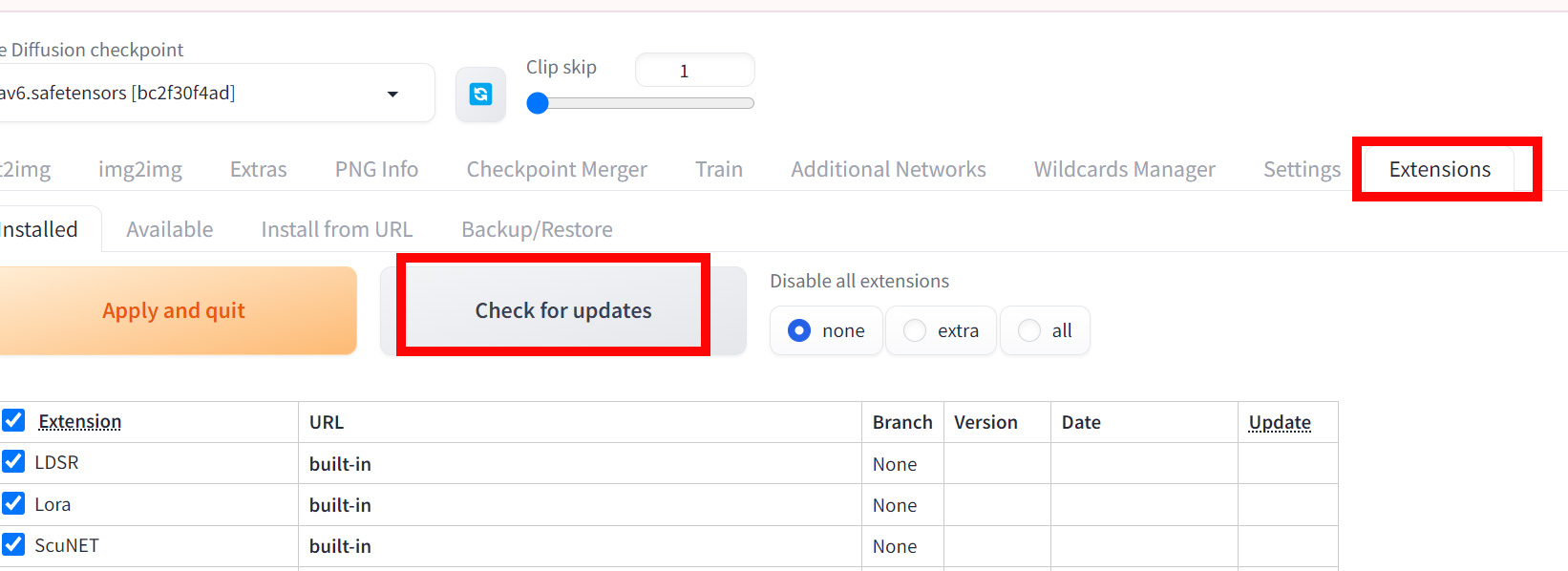
また、拡張機能の更新は以下の手順で行いましょう。Windowsの手順と同様です。
- Web UIを起動
- Extensionsタブを開く
- 「Check for updates」をクリック
- 更新がある場合は「Apply and restart UI」をクリック
これらの手順で、安全かつ確実にStable Diffusionを最新版に更新できます。
更新後は必ず動作確認を行い、問題が発生した場合は各OSのトラブルシューティング手順に従って対処することをおすすめします。
Stable Diffusionを使う2つの方法
「パソコンのスペックが心配」「環境構築が難しそう」と、Stable Diffusionの利用を検討しながらも、始めることを躊躇していませんか?
そのままだと画像生成AIの可能性を試せず、クリエイティブなチャンスを逃すかもしれません。
本章では、インストール不要ですぐに始められる2つの方法を紹介します。
- Google Colabでオンライン使用する方法
- Webサービスで登録だけで始める方法
それぞれのメリットや始め方を解説します。
Google Colabでオンライン使用する方法
Google Colabを使えば、プログラミング知識がなくてもStable Diffusionを始められます。
クラウド上のGPUを利用するため、パソコンのスペックを気にせずに画像生成を試せるのが大きな魅力です。
公開されているノートブックを使えば、環境構築や実行も簡単です。日本語対応のノートブックを使えば、日本語での操作も可能です。無料版でも画像生成の基本機能を試せます。
Google Colabのオンラインでの使用方法は以下のとおりです。
- Google Colabにアクセス
- Colabノートブックを用意
- ノートブックを開いて設定を実行
- GPUの選択
- セルを順番に実行
- Web UIで利用開始
Google Colabにアクセス
まずはGoogleアカウントを作成し、Google Colabにアクセスします。
Google Driveにアクセス権限が必要です(モデルデータを保存するため)。
>Google Colabの利用はこちら
Colabノートブックを用意
Stable Diffusion用の公開されているノートブックを利用するのが便利です。
代表的なノートブックとして、AUTOMATIC1111版のStable Diffusionノートブックが挙げられます。
>stable-diffusion-webui-colabの利用はこちら
このノートブックを使用することで、Google Colab上で簡単にStable Diffusionの環境を構築でき、画像生成を行えます。
ノートブックを開いて設定を実行
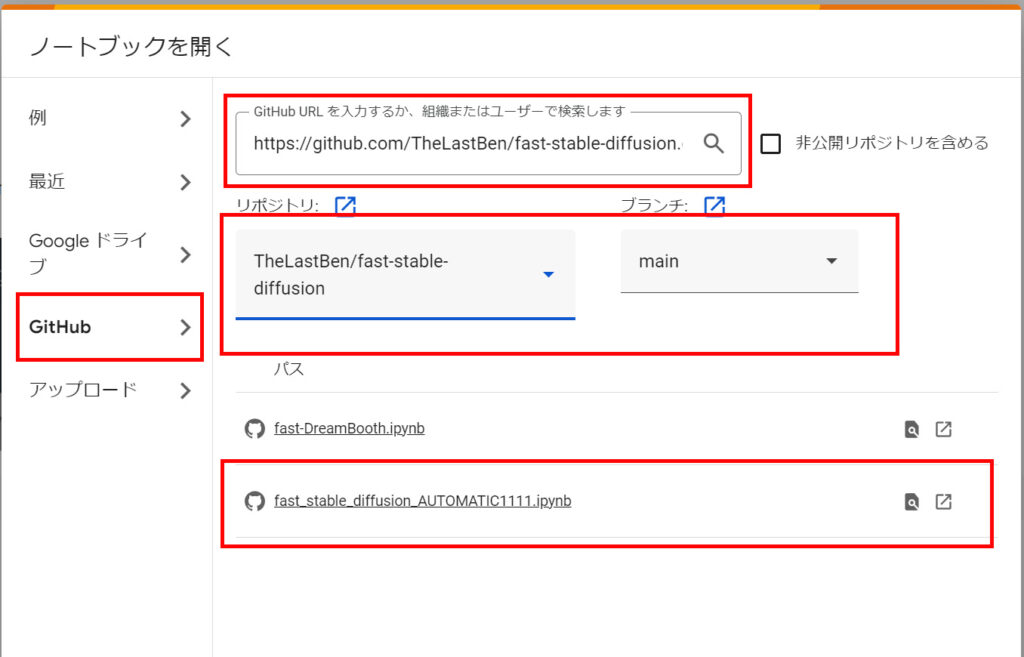
ノートブックをGoogle Colabで開きます。
左のGitHubのタブを選択し、「https://github.com/TheLastBen/fast-stable-diffusion.git」を入力してください。
リポジトリ・ブランチ・パスは画像と同じように設定してください。
GPUの選択
上部にあるタブから「ランタイム」をクリックし、ランタイムの変更を選択します。
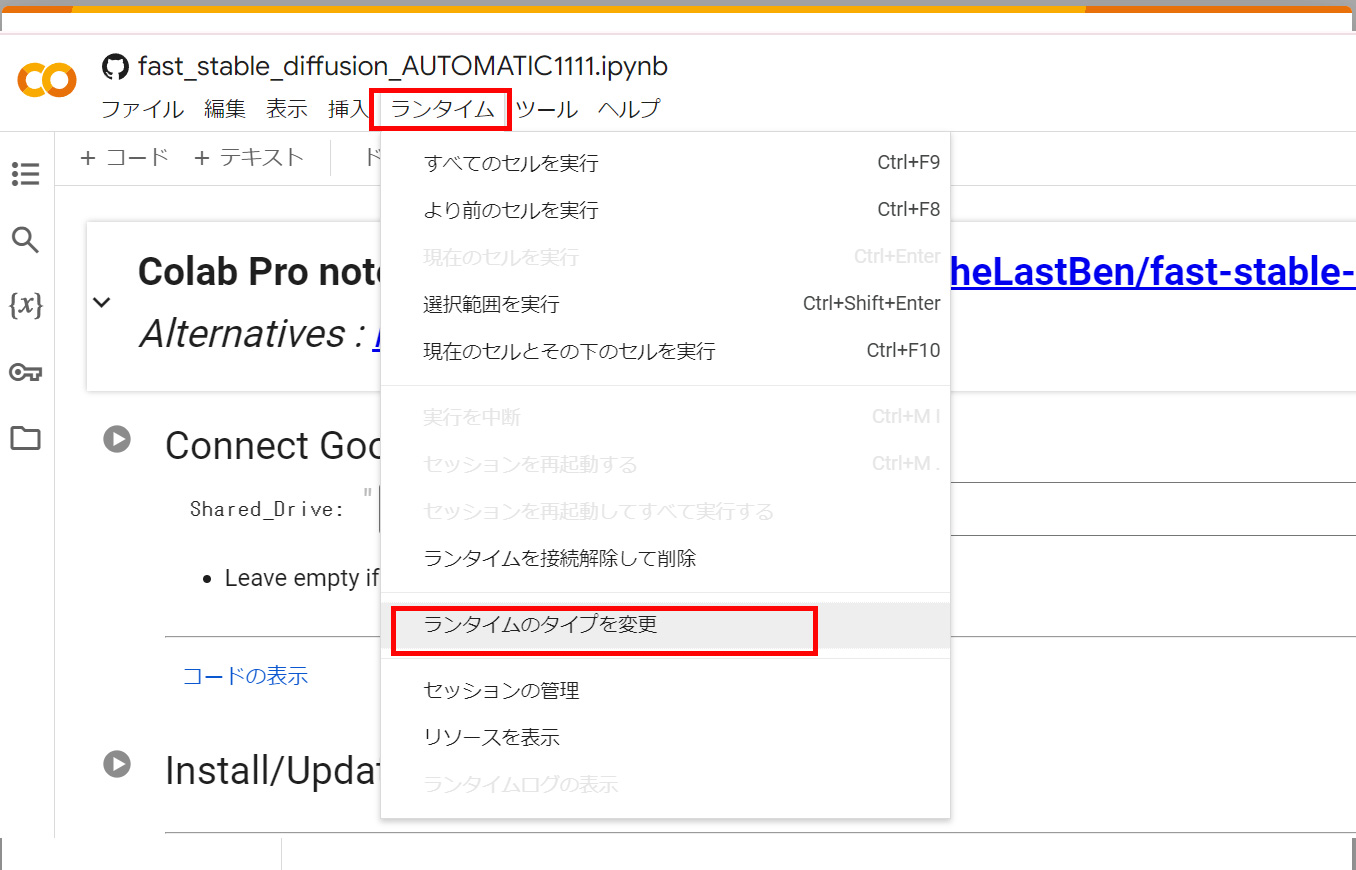
以下の画面が表示されますので、ランタイムを選択し、保存を押してください。性能の順は「A100 GPU > V100 GPU >T4 GPU」です。
選択が完了したら、右上の接続をクリックしましょう。

セルを順番に実行
次に、ノートブックの各セルを順番に実行します。
上から順番に「▶」のマークをクリックし実行してください。
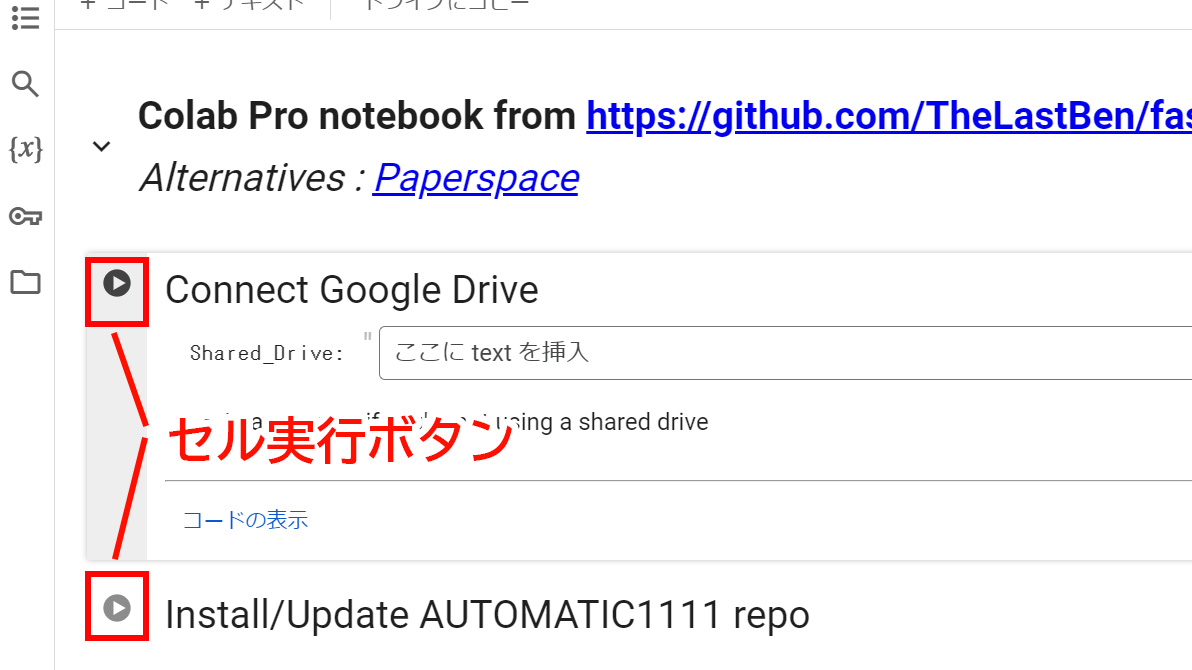
実行時にGoogleアカウントの認証やドライブへのアクセス許可を求められる場合があります。
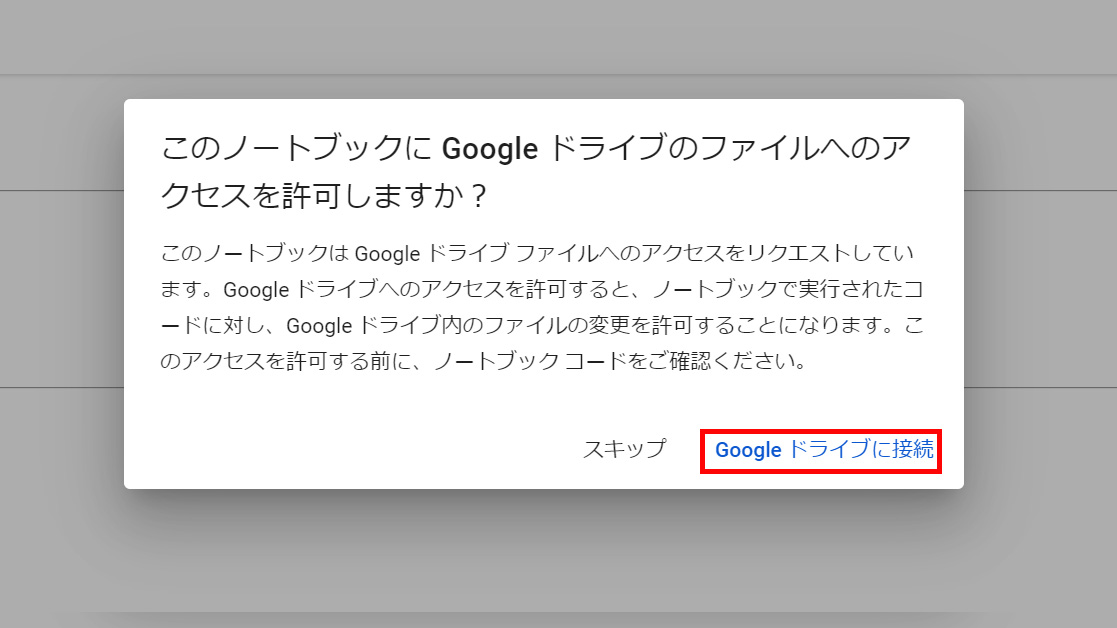
Web UIで利用開始
すべてのセルを実行後、ノートブック内に「ランタイムリンク」が表示されます。
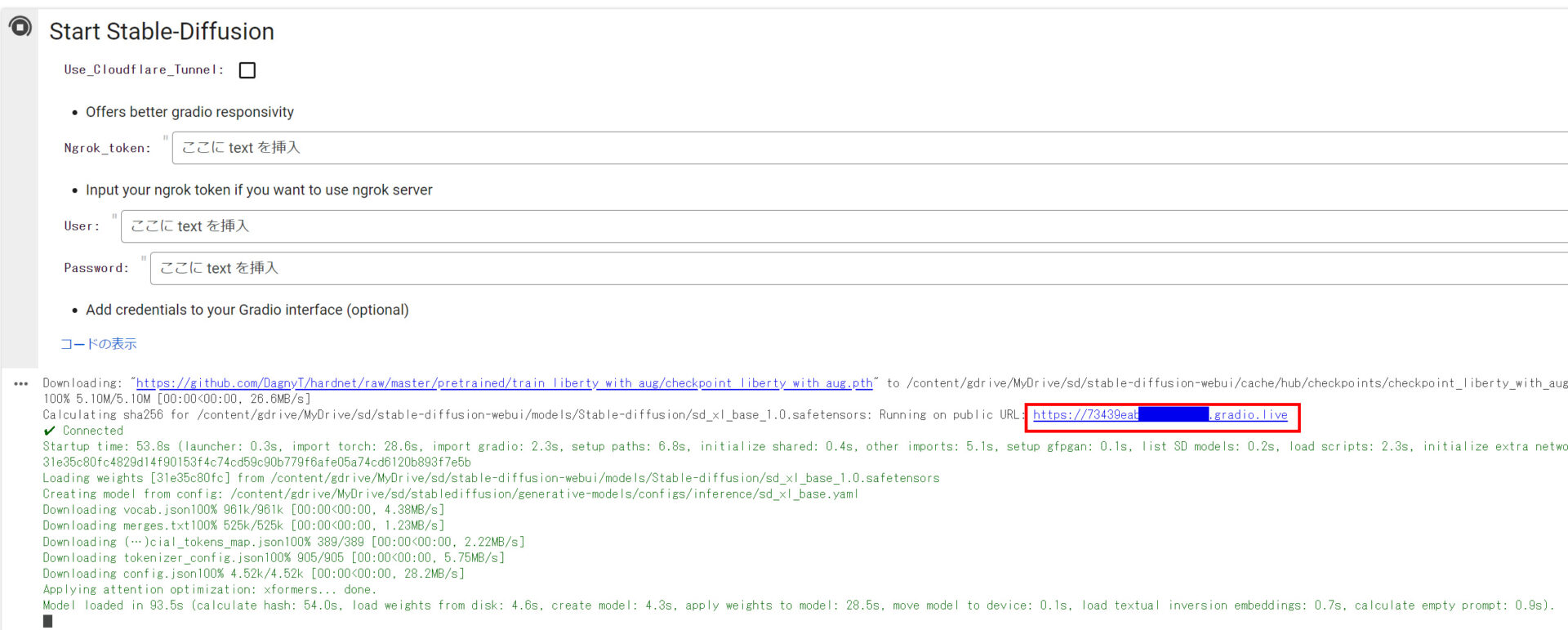
リンクをクリックすると、Stable DiffusionのWeb UIにアクセスできます。
以上の手順で、Google Colabを利用した、Stable Diffusionのセットアップと基本的な使い方は完了です。
また、無料枠制限について、Google Colab無料プランでは利用可能な時間やGPUリソースに制限がありますので注意しましょう。
Webサービスで登録だけで始める方法
Webサービスを利用する方法は、アカウント登録だけで即座にStable Diffusionを使い始められる手軽さが魅力です。
パソコンの性能や環境構築を気にする必要がなく、ブラウザさえあれば利用できます。
複数のWebサービスが提供されており、代表的なものとしてLeonardo.aiやDream Studioがあります。
>Leonardo.aiの利用はこちら
>Dream Studioの利用はこちら
これらのサービスは、ユーザーフレンドリーなインターフェースを備えており、直感的な操作で画像生成が可能です。
テキストを入力するだけで画像を生成できる基本機能に加え、画像の編集や変更も簡単に行えます。
Webサービスの多くは、無料プランと有料プランを用意されており、無料プランでは、一定数の画像生成クレジットが提供され、基本的な機能を試すことができます。
Stable Diffusionのインストールを簡単にするツール一覧
Stable Diffusionのインストールや環境構築に不安を感じる方のために、セットアップを自動化する便利なツールが登場しています。
これらのツールは、通常は複雑な手順が必要なインストール作業を、わずか数クリックで完了できるように設計されているものです。
技術的な知識がなくても、安全かつ確実にStable Diffusionの環境を構築ができます。
ツールを使用する際の注意点は以下の2点です。
- インストール前にウイルス対策ソフトを一時的に無効にする
- 管理者権限で実行する
また、インストール先のフォルダパスに日本語や空白を含めないようにすることで、トラブルを防げます。
本記事では、以下3つのツールをピックアップして紹介します。
StabilityMatrix
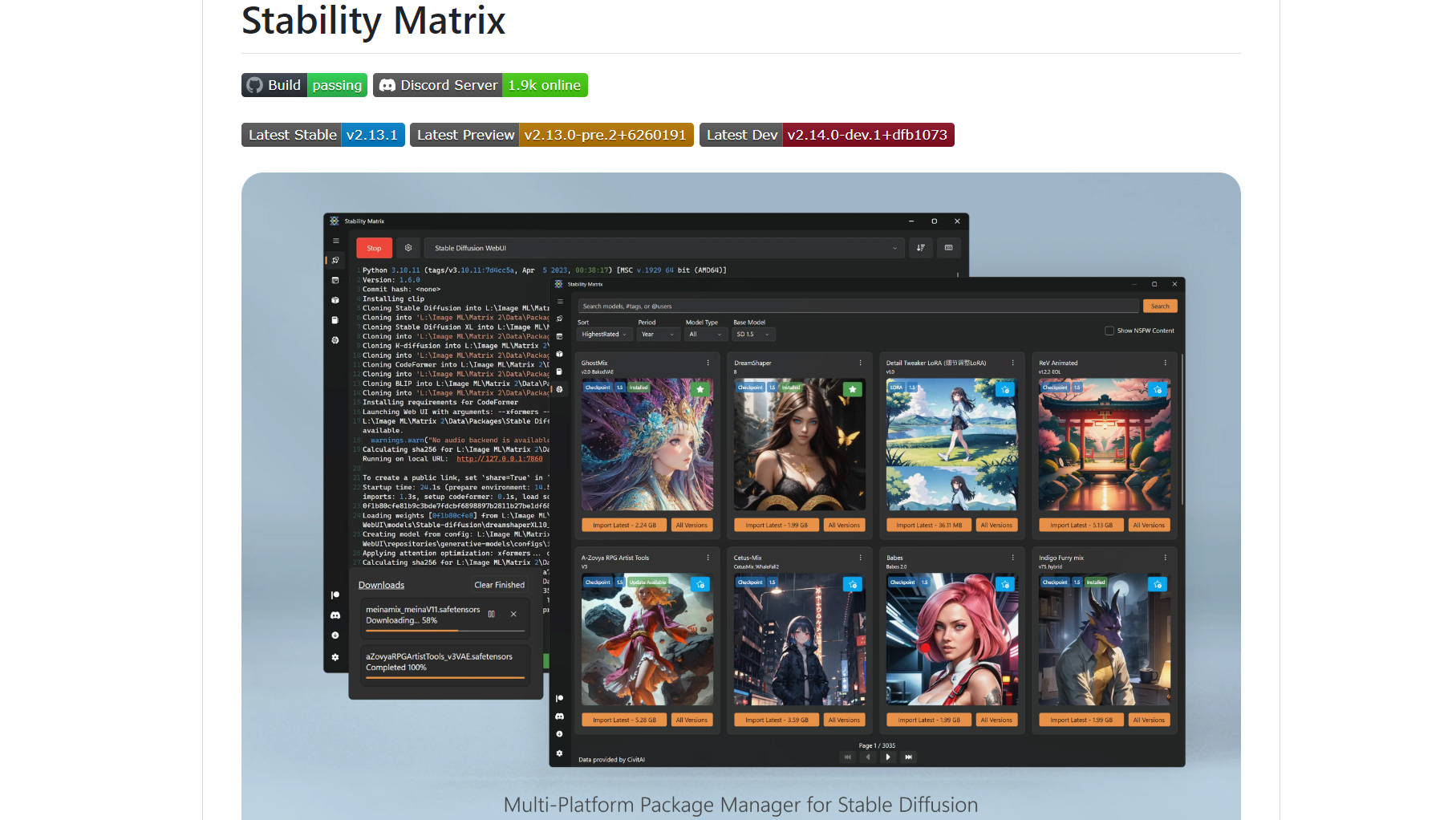
StabilityMatrixは、日本語対応の使いやすいインストーラーとして人気があります。
インストール方法は、公式サイトからインストーラーをダウンロードし、実行ファイルを起動するだけです。
起動後は画面の指示に従って進めるだけで、Pythonのインストールや必要なモデルの設定まで自動で完了します。
>StabilityMatrixのダウンロードはこちら
Easy Forge
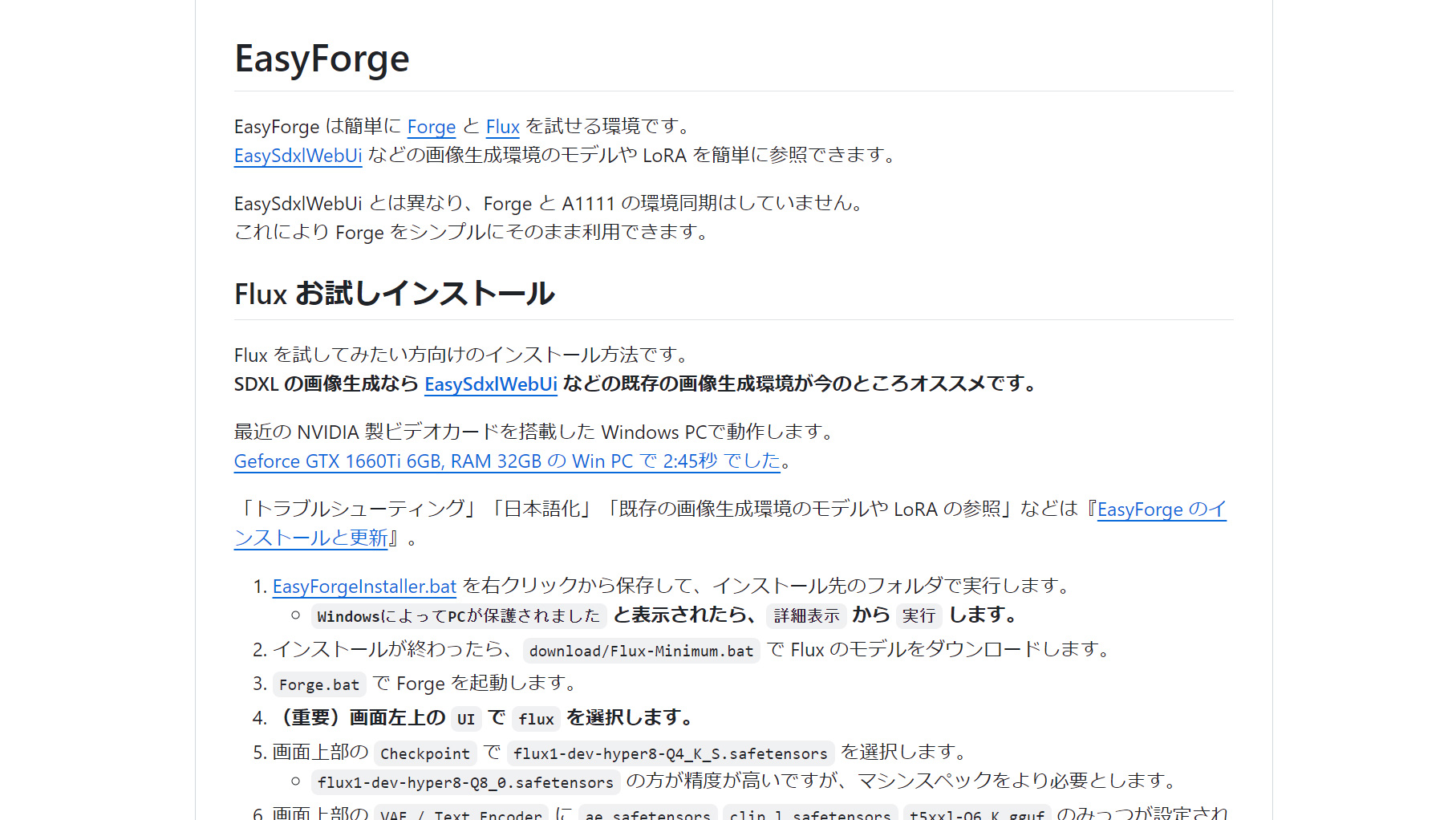
Easy Forgeは、Forgeに特化したインストール支援ツールとして注目を集めています。
Stable Diffusion Forgeは、Stable Diffusionを使いやすくするためにカスタマイズされたWEB UIです。初心者から上級者まで幅広いユーザーに対応し、シンプルで直感的な操作が特徴です。
インストール手順は、GitHubからZIPファイルをダウンロードして解凍し、install.batを実行するだけです。
Forgeの基本機能に加えて、よく使用される拡張機能やモデルをまとめてインストールできる仕組みを備えています。
画像生成に必要な基本的なモデルや、日本語対応の拡張機能が初期状態で組み込まれているため、インストール直後から本格的な使用が可能です。
>Easy Forgeのダウンロードはこちら
Easy Reforge

Easy ReforgeはEasy Forgeの改良版として開発されました。アニメ風のイラスト生成に優れた性能の、NoobAIのEpsilon-Prediction版(NoobE)とV-Prediction版(NoobV)をサポートしています。
インストール方法はEasy Forgeと同様ですが、追加の設定オプションが用意されています。
Easy Reforgeの特徴は、システムの互換性チェックや最適な設定の自動調整機能を備えていることです。GPUのメモリ使用量の最適化や、VAEの自動ダウンロードなどが含まれます。
インストール後のアップデートも簡単に行えるため、長期的な運用を考える方に適しています。
>Easy Reforgeのダウンロードはこちら
2026年5月30日(土)、SHIFT AI × romptn ai「クリエイターセミナー」を開催します!
第一線で活躍中のクリエイターが、最新の画像生成AIを使いながら、画像生成AIを活用した収益化についてお話しします。
無料で参加していただけますので、「画像生成AIを使って収益化したい!」「SNSで投稿したい!」という方は、ぜひ以下のボタンからセミナーにご参加ください。
スキルゼロから始められる!
無料AIセミナーに参加するStable Diffusionの説明書と使い方
「インストールしたけれど機能が多すぎて使い方がわからない」「設定が難しく、画像をうまく生成できない」と困っていませんか?
多くのユーザーが、せっかく導入しても使いこなせずに悩んでいます。
基本操作や設定を理解しないままだと、画像生成の効率が悪くなり、期待する高品質な画像を作れず、クリエイティブな可能性を活かせないかもしれません。
本章では、Stable DiffusionのWEB UIの基本的な画面の見方、設定のコツを詳しく解説します。初心者でもわかりやすいよう、画面説明や具体的な例を交えて段階的に説明します。
- WEB UI画面の基本的な見方(上部タブ)
- WEB UI画面の基本的な見方(生成設定セクション)
- インストール後の初期設定
- WEB UIの各ボタンの役割
- 画像の生成に必要な基本設定
- 生成結果の保存方法
WEB UI画面の基本的な見方(上部タブ)
Stable DiffusionのWeb UI画面は、効率的な画像生成のために機能的に設計されています。主要な構成要素を詳しく解説します。
上部タブメニューのうち、主に使用するのは以下の4つです。
| タブ名 | 内容 |
|---|---|
| txt2img | テキストから画像生成 |
| img2img | 画像から画像生成 |
| extra | 追加処理 |
| PNG Info | 情報確認 |
| Settings | 詳細設定 |
「txt2img(テキストから画像生成)」では以下のことが行えます。
- メインとなる画像生成機能
- テキストプロンプトから新規に画像を生成
- 最も基本的で使用頻度の高い機能
上段は「ポジティブプロンプト入力欄」、下段は「ネガティブプロンプト入力欄」です。

「img2img(画像から画像生成)」では以下のことが行えます。
- 既存の画像を元に新しい画像を生成
- 画像のアップロード機能
- Denoising strengthで変化度合いを調整
- Inpaint機能で部分的な修正も可能

「extras(追加処理)」では以下のことが行えます。
- 生成画像の後処理を行うタブ
- アップスケール機能
- 顔の修正機能
- 画像の補正や加工

「PNG Info(情報確認)」では以下のことが行えます。
- 生成画像の設定情報を確認
- プロンプトやパラメータの確認
- 設定の再利用が可能

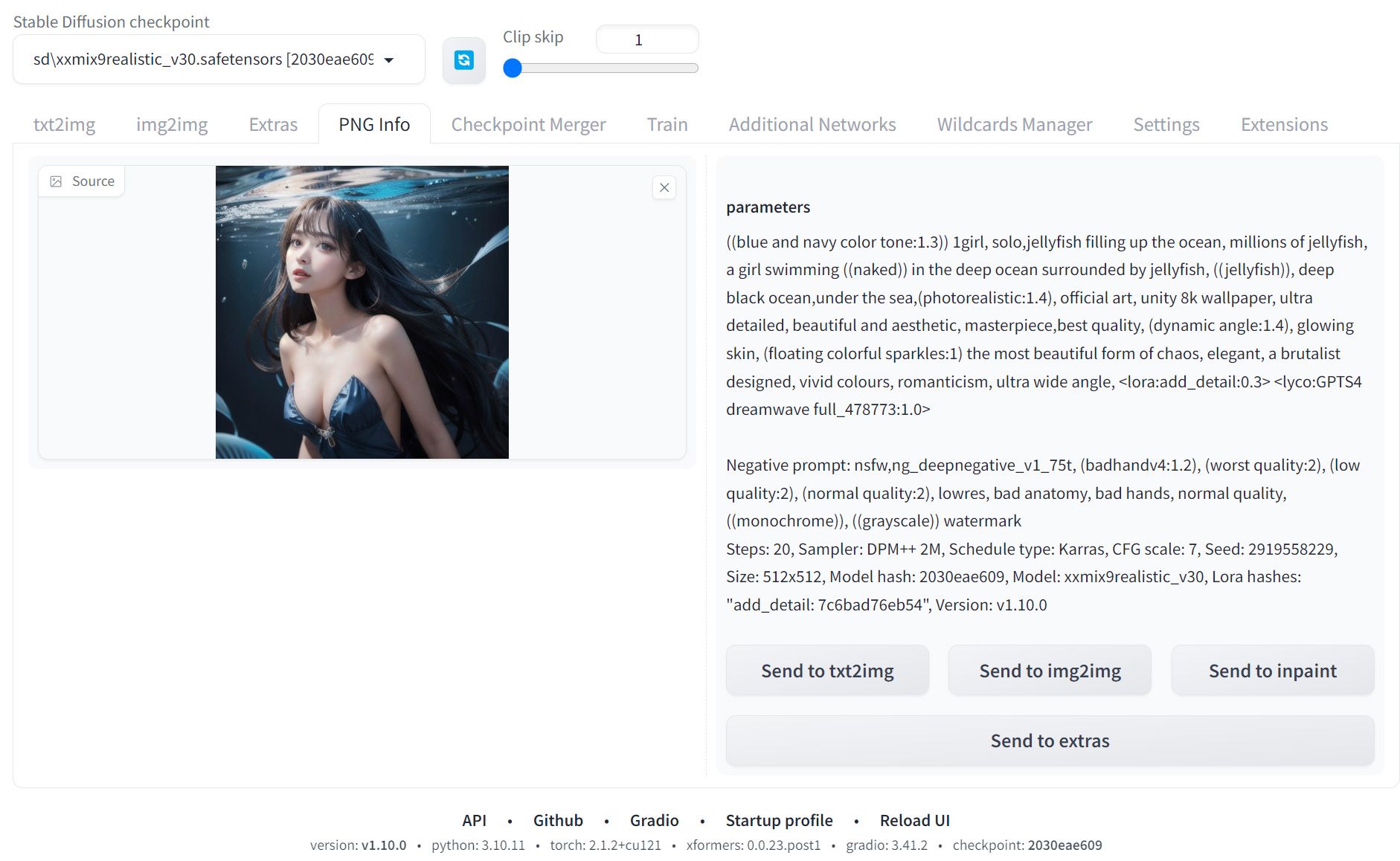
「Settings(詳細設定)」では以下のことが行えます。
- 全体設定の管理画面を開く
- パフォーマンス設定
- 保存設定
- インターフェース設定
WEB UI画面の基本的な見方(生成設定セクション)
Stable DiffusionのWeb UI画面のうち、生成設定セクションについて解説します。生成設定セクションは以下のような画面です。
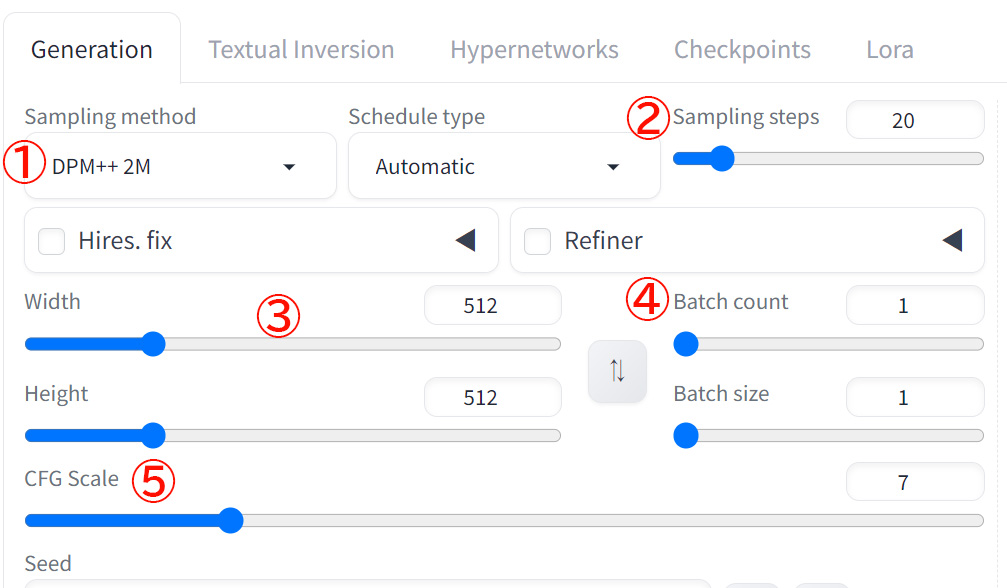
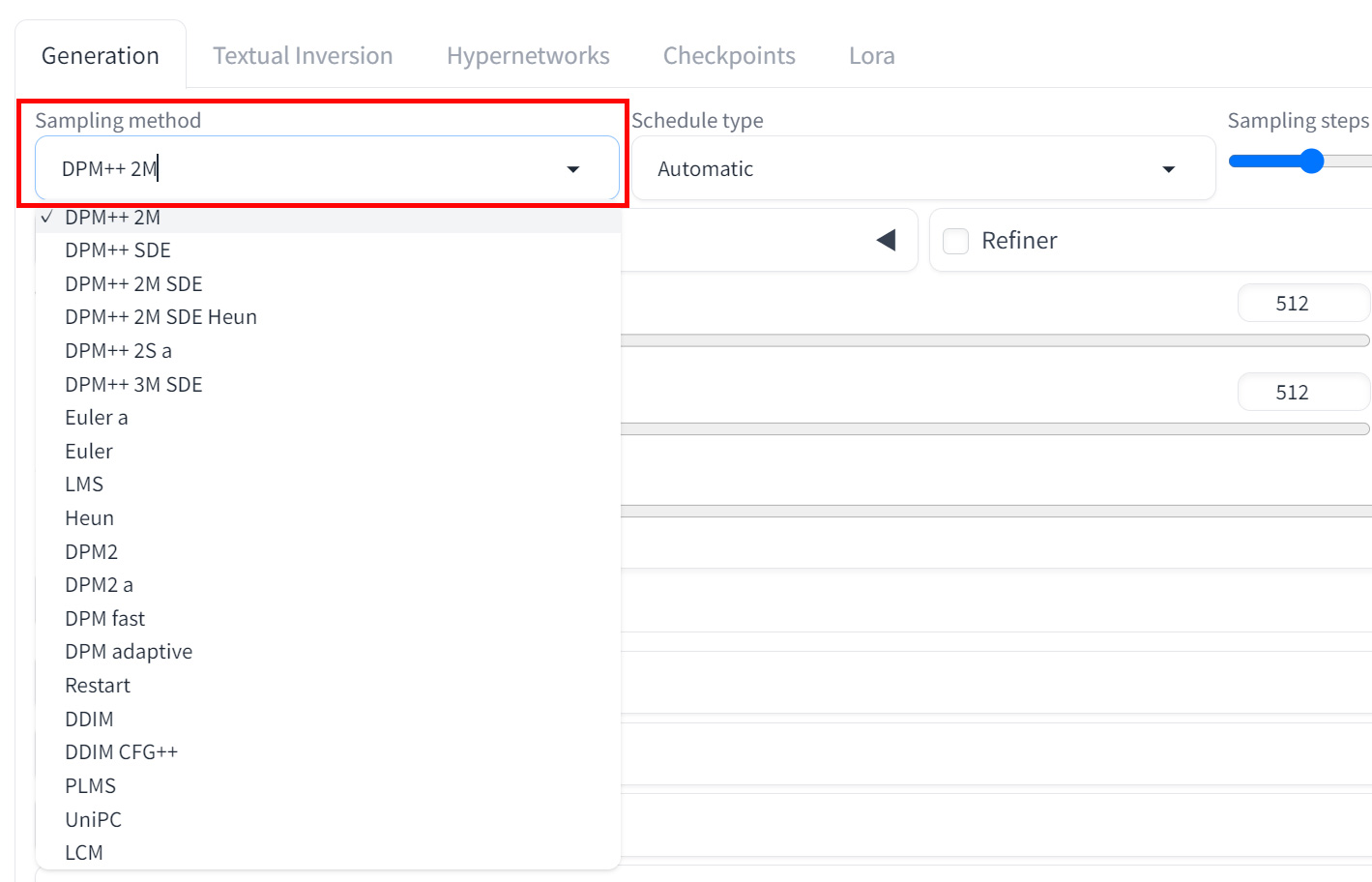
- Sampling Method(サンプリング方式選択)
- Sampling Steps(生成ステップ数)
- Width/Height(画像サイズ設定)
- Batch count/size(一括生成設定)
- CFG Scale(プロンプトの影響度)
「Sampling method」では以下のことが行えます。
- サンプリングアルゴリズムの選択
- DPM++ 2M Karras:高品質な生成向け
- Euler a:高速生成向け
- DDIM:安定した生成向け
「Batch count/size」では以下のことが行えます。
- 一度に生成する画像の数を設定
- VRAMの使用量に影響
- 処理時間とのバランスを考慮
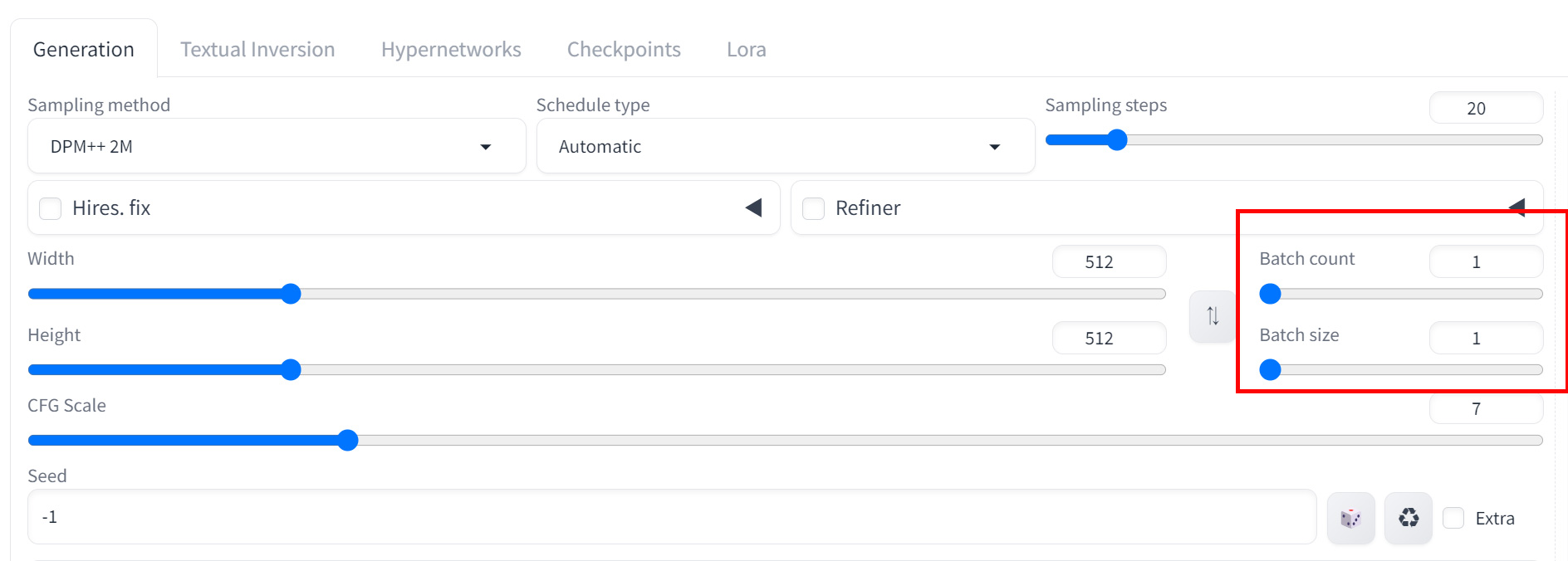
「Batch count/size」はバッチ処理関連です。Batch countは生成する画像の枚数を指定、Batch sizeはBatch countで指定した画像生成の繰り返し回数を設定するパラメータです。
Batch countを2、Batch sizeを2とした場合、2枚の生成を2回繰り返す設定となります。
インストール後の初期設定
モデルとVAEの初期設定は、生成される画像の品質を大きく左右する重要な要素です。最適な設定を解説します。
まずはモデルの配置です。配置場所は「models/Stable-diffusion」にしましょう。

モデルの選択に際して、推奨モデルを2つ紹介しますので、ぜひ利用してみてください。
1つ目は「GhostMix」で、アニメ調の汎用モデルです。
>GhostMixのダウンロードはこちら
2つ目は「Beautiful Realistic Asians」で、写実的な表現に特化しています。
>Beautiful Realistic Asiansのダウンロードはこちら
次にVAEの初期設定について解説します。配置場所は「models/VAE」にしましょう。
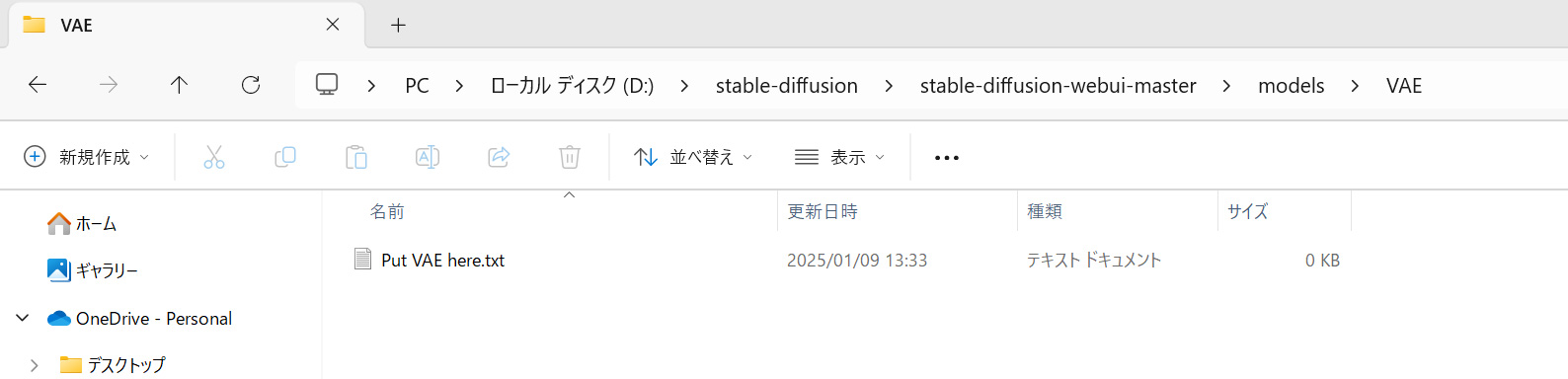
推奨するVAEは「vae-ft-mse-840000-ema-pruned.safetensors」です。
>vae-ft-mse-840000-ema-pruned.safetensorsのダウンロードはこちら
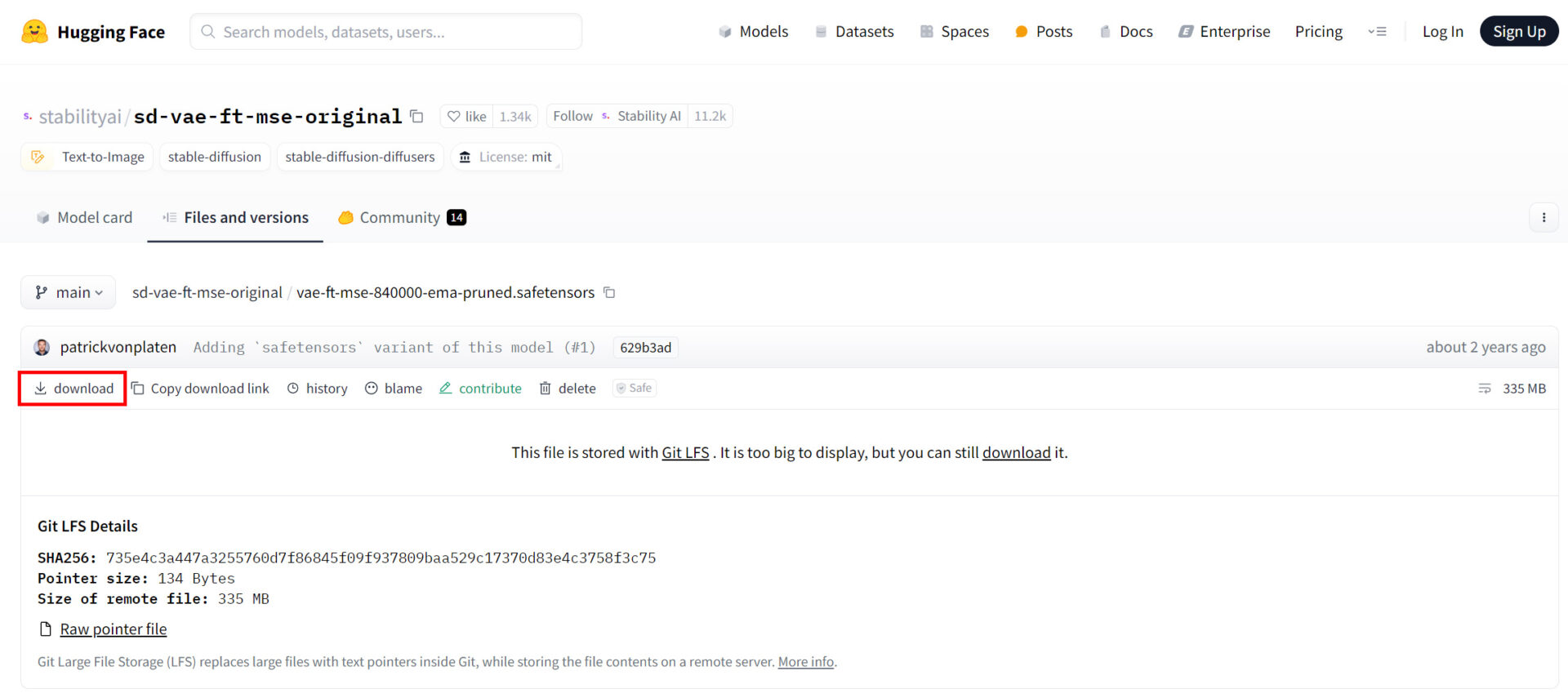
これらの設定は、使用するGPUの性能やメモリ容量に応じて適宜調整が必要です。
また、新しいモデルや拡張機能をインストールする際は、都度設定の見直しをおすすめします。
WEB UIの各ボタンの役割
Stable Diffusion Web UI画面の各ボタンの役割について解説します。
- Generate
- Interrupt/Skip
- リロード
- 消去
- スタイル編集
Generateボタンでは以下のことが行えます。
- 画像生成を開始する
- 生成中は「Interrupt」ボタンに変化
- 設定した内容に基づいて画像を生成
- プロンプトが空の場合は警告を表示

Interrupt/Skipボタンでは以下のことが行えます。
- Interrupt:現在の生成処理を中断
- Skip:現在の画像をスキップして次の生成へ移行
- バッチ処理中に特に有用
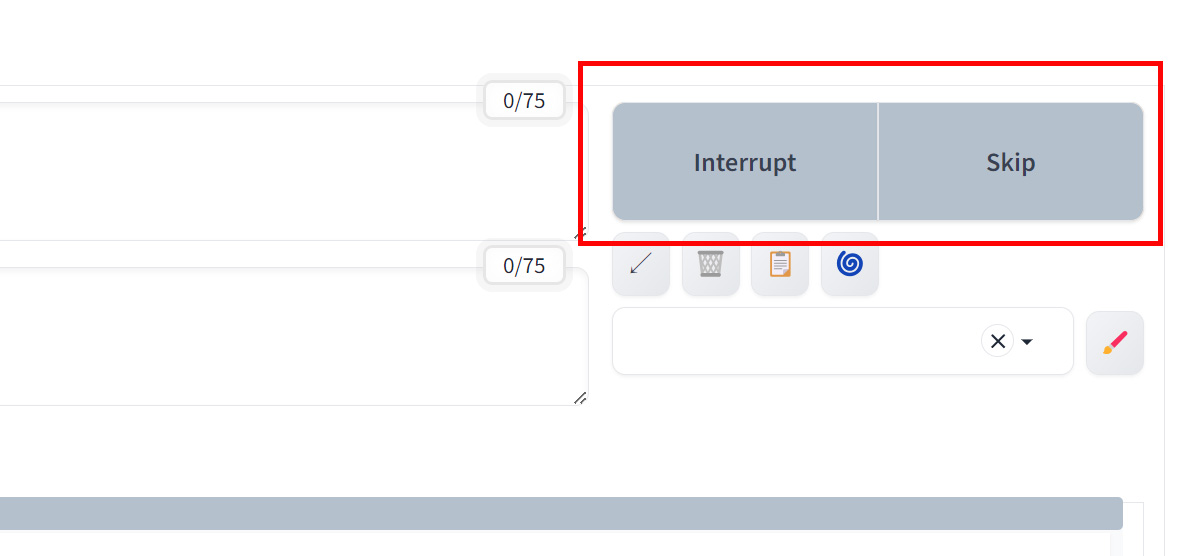
リロードボタンでは以下のことが行えます。
- プロンプトを含む前回の設定を呼び出し
- エラーなどで再起動した際に有用
消去ボタンを押すと、入力されているプロンプト・ネガティブプロンプトの削除が行えます。
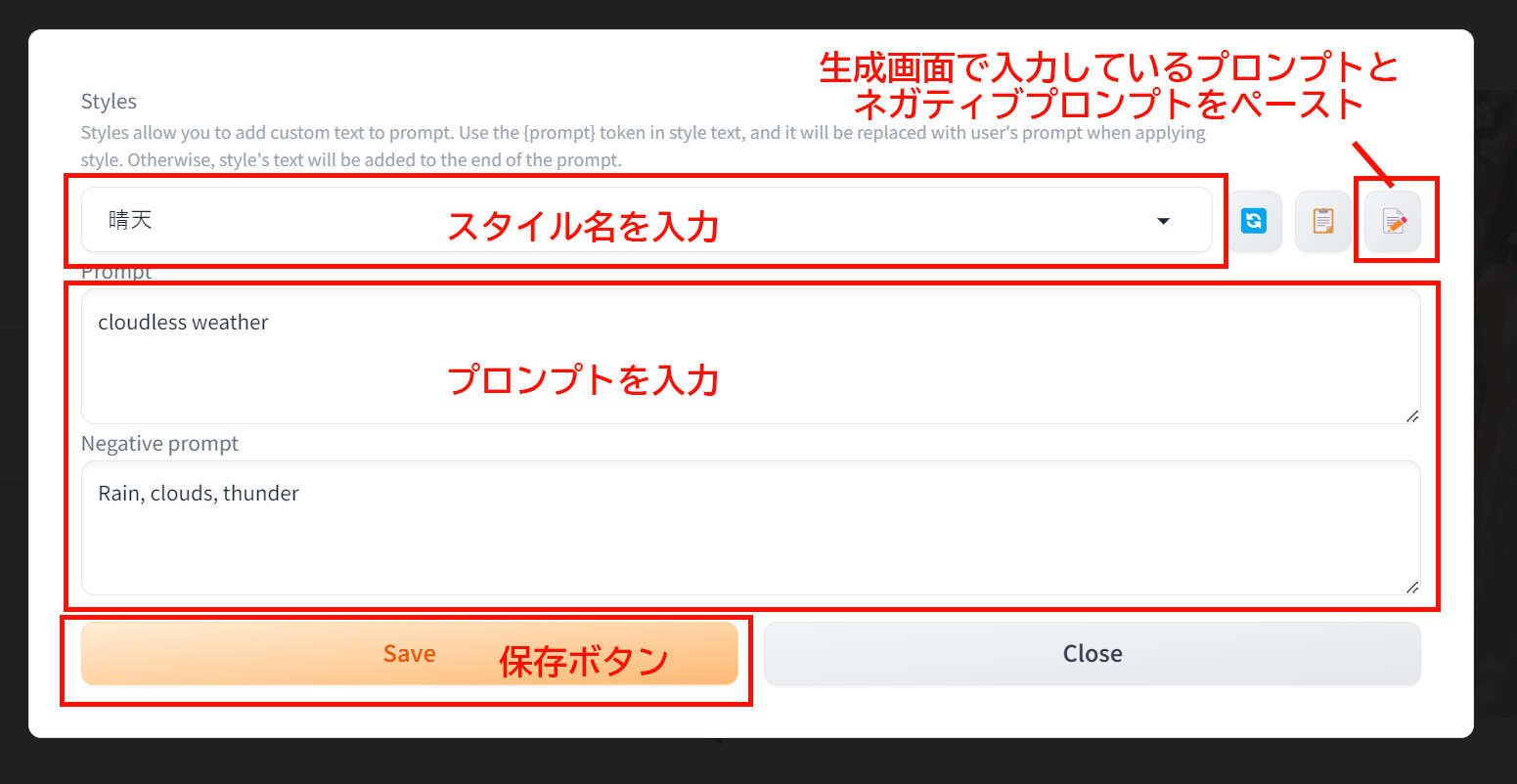
スタイル編集ボタンでは以下のことが行えます。
- プロンプトやネガティブプロンプトを保存し、呼び出すための機能
- 一部や全部のプロンプトを名前を付けて保存できる
- 選択したスタイルはプロンプトの末尾に挿入
画像の生成が完了すると、生成された画像の下に以下のボタンが表示されます。
- 画像フォルダ呼び出し
- 画像保存
- 画像圧縮保存
- 画像移動
画像フォルダ呼び出しボタンを押すと、生成した画像が格納されているフォルダの呼び出しを行えます。
画像保存ボタンを押すと、生成した画像を任意の場所に保存できます。
画像圧縮保存ボタンは、生成した画像をZip形式で圧縮して保存するときに使用します。
画像移動ボタンは3種類あり、左から順番に以下のことが行えます。
- 左:生成した画像をimg2img画面に移動
- 中央:生成した画像をinpaintのインペイントタブへ移動
- 右:生成した画像をextrasへ移動
画像の生成に必要な基本設定
生成画像の品質は、適切なパラメータ設定によって大きく変わります。モデルごとの最適な設定と、目的に応じた調整方法を説明します。
SD 1.5モデルで最適なサンプリング方式は以下のとおりです。
| Sampling method | 品質 | ステップ数 |
|---|---|---|
| DPM++ 2M Karras | 最も安定した高品質な結果 | 25-30 |
| Euler a | 高速な生成が可能 | 20-25 |
| DDIM | 再現性の高い生成 | 30-35 |
SDXLモデルで最適なサンプリング方式は以下のとおりです。
| Sampling method | 品質 | ステップ数 |
|---|---|---|
| DPM++ SDE Karras | SDXLに最適化された方式 | 25-30 |
| UniPC | 高速で安定した生成 | 20-25 |
| DDIM | 再現性の高い生成 | 30-35 |
推奨される画像サイズとアスペクト比もモデルによって異なります。SD 1.5モデルの推奨画像サイズは以下のとおりです。
| 標準 | 横長 | 縦長 |
|---|---|---|
| 512×512 | 768×512 | 512×768 |
SDXLモデルでは、以下のサイズが推奨されています。
| 標準 | 横長 | 縦長 |
|---|---|---|
| 1024×1024 | 1344×768 | 768×1344 |
生成結果の保存方法
Stable Diffusionで生成した画像を効率的に管理し、後から設定を参照できるよう、適切な保存方法を解説します。
生成された画像は「stable-diffusion-webui」フォルダ内の「outputs」に保存されています。
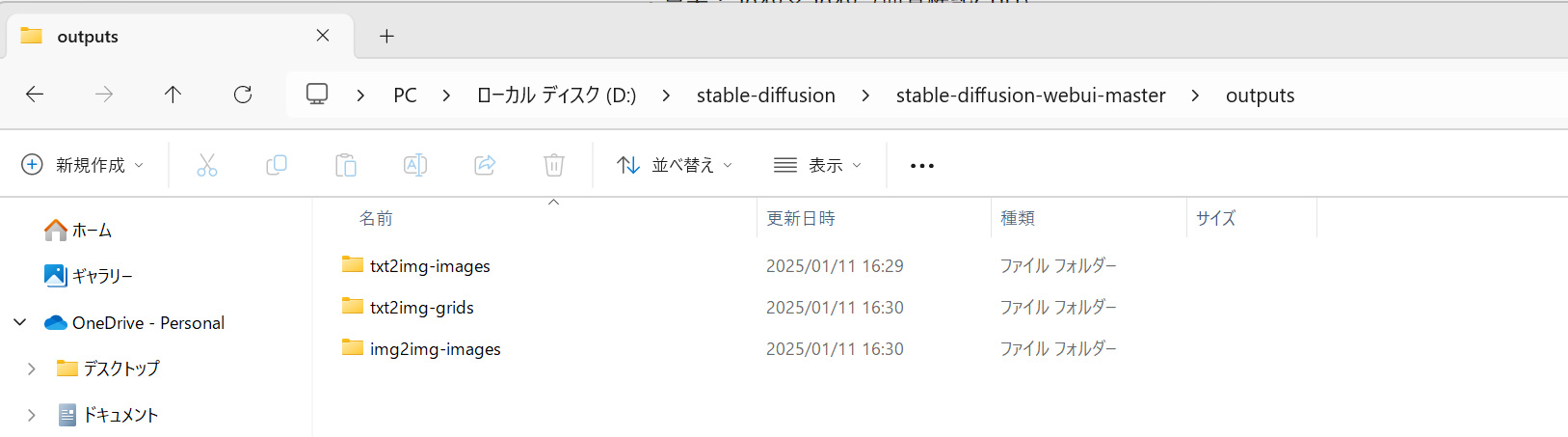
txt2img-imagesは1枚で生成した画像が保存、txt2img-gridはバッチサイズを2以上にした際に生成される画像を1枚にまとめたグリッド画像が保存されています。
保存形式の選択はデフォルトのPNGが推奨です。目的に応じて、最適な保存方法の選択をおすすめします。
| 保存形式 | 品質 | 容量 |
|---|---|---|
| PNG | 最高品質 | 大 |
| JPEG | WEB投稿向き | 中 |
| WebP | 高圧縮・高品質 | 小 |
2026年5月30日(土)、SHIFT AI × romptn ai「クリエイターセミナー」を開催します!
第一線で活躍中のクリエイターが、最新の画像生成AIを使いながら、画像生成AIを活用した収益化についてお話しします。
無料で参加していただけますので、「画像生成AIを使って収益化したい!」「SNSで投稿したい!」という方は、ぜひ以下のボタンからセミナーにご参加ください。
スキルゼロから始められる!
無料AIセミナーに参加する【初級】プロンプト使い方・基礎と応用知識
「思い通りの画像が生成されない」「プロンプトの書き方がわからない」と悩んでいませんか?プロンプトの基本を知らないまま、多くの時間を無駄にしている方も多いはずです。
適切なプロンプトを理解しないと、画像生成の効率が悪くなり、クオリティの高い作品を作れない状態が続くかもしれません。
ここからは、プロンプトの基本から応用テクニックまで、実践的に解説します。
ポジティブプロンプトとネガティブプロンプトの基本的な使い方や、高度な表現を実現するためのコツを、以下3つのモデルでの具体例を交えながら解説します。
- アニメ調汎用モデル:GhostMix
- 写実調モデル:Beautiful Realistic Asians
- SDXLモデル:XXMix_9realisticSDXL
アニメ調汎用モデル:GhostMix
アニメ調汎用モデル「GhostMix」での生成例とプロンプトを紹介します。基本的なプロンプト構造は以下のとおりです。
[品質タグ], [キャラクター], [服装], [表情], [ポーズ], [背景], [画風]
今回は以下のプロンプトで画像を生成してみました。
masterpiece, best quality, 1girl, long silver hair, detailed eyes, wearing white sundress, gentle smile, standing pose, cherry blossom background, soft lighting
生成した画像のプロンプトに要素を加え、生成の変化を見てみます。追加した部分は、プロンプトのうち太字になっている箇所です。
品質タグ「ultra detailed, award winning, extremely detailed」を追加した生成結果が以下の画像です。
masterpiece, best quality,ultra detailed, award winning, extremely detailed,1girl, long silver hair, detailed eyes, wearing white sundress, gentle smile, standing pose, cherry blossom background, soft lighting
次に、顔周りの表現として表情タグ「detailed facial features, perfect face, beautiful eyes」を追加した生成結果が以下の画像です。
masterpiece, best quality, 1girl, long silver hair, detailed eyes, wearing white sundress, gentle smile,detailed facial features, perfect face, beautiful eyes, standing pose, cherry blossom background, soft lighting
次に、髪の表現としてポーズタグ「flowing hair, detailed hair, hair between eyes」を追加した生成結果が以下の画像です。
masterpiece, best quality, 1girl, long silver hair, detailed eyes, wearing white sundress, gentle smile,detailed facial features, perfect face, beautiful eyes, standing pose,flowing hair, detailed hair, hair between eyes, cherry blossom background, soft lighting
また、ネガティブプロンプトとしては以下の要素を使うと効果的でしょう。
bad quality, worst quality, low quality, normal quality, lowres, blurry, bad anatomy, bad hands, extra digits, fewer digits, missing arms写実調モデル:Beautiful Realistic Asians
写実調モデル「Beautiful Realistic Asians」での生成例とプロンプトを紹介します。基本的なプロンプト構造は以下のとおりです。
[撮影品質], [被写体], [撮影設定], [環境], [カメラ設定], [後処理]
今回は以下のプロンプトで画像を生成してみました。
RAW photo, professional portrait, young woman, natural skin texture, detailed facial features, outdoor session, natural lighting, bokeh background, Canon EOS R5, professional color grading
生成した画像のプロンプトに要素を加え、生成の変化を見てみます。追加した部分は、プロンプトのうち太字になっている箇所です。
撮影品質タグ「8k uhd, professional photography」を追加した生成結果が以下の画像です。
RAW photo, professional portrait,8k uhd, professional photography, young woman, natural skin texture, detailed facial features, outdoor session, natural lighting, bokeh background, Canon EOS R5, professional color grading
次に、テクスチャとして被写体タグ「pores, subsurface scattering」を追加した生成結果が以下の画像です。
RAW photo, professional portrait, young woman, natural skin texture,pores, subsurface scattering, detailed facial features, outdoor session, natural lighting, bokeh background, Canon EOS R5, professional color grading
次に、ライティングとして環境タグ「golden hour」を追加した生成結果が以下の画像です。
RAW photo, professional portrait, young woman, natural skin texture, detailed facial features, outdoor session, natural lighting, golden hour, bokeh background, Canon EOS R5, professional color grading
次に、カメラ設定「85mm lens, f/1.4」を追加した生成結果が以下の画像です。
RAW photo, professional portrait, young woman, natural skin texture, detailed facial features, outdoor session, natural lighting, bokeh background, Canon EOS R5,85mm lens, f/1.4, professional color grading
また、ネガティブプロンプトとしては以下の要素を使うと効果的でしょう。
cartoon, anime style, illustration, painting, drawing, artificial, fake, 3d render, bad quality, deformed faceSDXLモデル:XXMix_9realisticSDXL
SDXLモデル「XXMix_9realisticSDXL」での生成例とプロンプトを紹介します。基本的なプロンプト構造は以下のとおりです。
[撮影品質], [被写体], [撮影設定], [環境], [カメラ設定], [後処理]
今回は以下のプロンプトで画像を生成してみました。
ultra detailed photograph, professional portrait, attractive young woman, designer fashion outfit, high end studio setup, dramatic lighting, cinematic composition, shot on Hasselblad
生成した画像のプロンプトに要素を加え、生成の変化を見てみます。追加した部分は、プロンプトのうち太字になっている箇所です。
写真表現として、撮影品質タグ「cinematic, editorial photography, fashion magazine style」を追加した生成結果が以下の画像です。
ultra detailed photograph, professional portrait,cinematic, editorial photography, fashion magazine style, attractive young woman, designer fashion outfit, high end studio setup, dramatic lighting, cinematic composition, shot on Hasselblad
次に、テクスチャとして被写体タグ「intricate details, fabric weave, skin texture, environmental details」を追加した生成結果が以下の画像です。
ultra detailed photograph, professional portrait, attractive young woman, designer fashion outfit,intricate details, fabric weave, skin texture, environmental details, high end studio setup, dramatic lighting, cinematic composition, shot on Hasselblad
次に、照明表現として環境タグ「volumetric lighting, rim light, ambient occlusion」を追加した生成結果が以下の画像です。
ultra detailed photograph, professional portrait, attractive young woman, designer fashion outfit, high end studio setup, dramatic lighting, cinematic composition,volumetric lighting, rim light, ambient occlusion, shot on Hasselblad
また、ネガティブプロンプトとしては以下の要素を使うと効果的でしょう。
amateur, noisy, grainy, blurry, oversaturated, undersaturated, blown out highlights, crushed blacks, bad compositionプロンプト作成の応用
プロンプト作成では、単なるキーワードの羅列ではなく、意図に沿った戦略的な構成が重要です。
基本的には、主要な要素から詳細な特徴へと段階的に記述していきます。例えば、「若い女性」という基本要素から髪型・服装・表情など具体的な特徴を加えて展開します。
重み付けも有効で、「(important:1.2)」のように括弧を使うと要素の強調が可能ですが、1.5以上は歪みの原因になるため注意が必要です。
画風や雰囲気の調整には、複合表現が役立ちます。「{fantasy and realistic}」のような記述やライティング・構図の要素を追加することで、より完成度の高い画像が生成できます。
プロンプトは、重要な要素を前半に、詳細な指定を後半に配置することで、AIが意図を正確に理解しやすくなります。
テクニックを状況に応じて組み合わせ、生成結果を確認しながら改善を繰り返すことで、高品質な画像生成が実現します。
プロンプト作成の注意点
「プロンプトを書いても思い通りの画像ができない」「表現がマンネリ化して画像のバリエーションが増えない」と悩んでいませんか?
具体的な書き方やミスの対処法がわからず、試行錯誤を繰り返している方も多いはずです。
プロンプトの記述ミスや曖昧な表現が続くと、画像生成の精度が向上せず、時間を浪費するだけでなく、安定した成果を得られなくなります。
本章では、プロンプト作成時のよくあるミスと回避方法、曖昧な表現を具体的にするテクニックを解説します。
よくある記述ミスとその回避方法
プロンプト作成で初心者が陥りやすいミスとその対策を説明します。
文法ミスは生成結果に大きな影響を与えます。「beautiful,girl,dress」のようにカンマ後のスペースを省くと認識精度が低下しますので、正しく「beautiful, girl, dress」と記述する必要があります。
重複表現も避けるべきです。「cute girl, kawaii girl」のような類似表現は効果が薄く、「cute girl with gentle expression」のように具体的な情報を加える方が効果的です。
さらに、括弧の使い過ぎも注意が必要です。「((masterpiece))」のような過度な重み付けは画像の歪みを招く恐れがあるため、基本的な品質指定で十分です。
曖昧な表現を避けるための工夫
曖昧な表現は意図しない結果を招く原因になるため、具体的な表現を心がけることが重要です。
抽象的な形容詞は避け、「beautiful scene」ではなく「sunlit garden with blooming roses and clear blue sky」のように具体的な要素を記述することで、望ましい結果が得られます。
また、「colorful」のような曖昧な色指定よりも、「pale pink, sky blue, mint green」と具体的に記述する方が意図した配色を実現しやすくなります。
構図や光の表現も、「good composition」ではなく、「front view, natural lighting from left, soft shadows」といった具体的な特徴を指定することが効果的です。
具体的で明確なプロンプトを意識することで、より意図に沿った高品質な画像を生成できます。結果を確認しつつ、少しずつプロンプトを改善することも大切です。
生成した画像の保存形式と用途
「画像を生成できたけれど、どの形式で保存すればいいのか」「用途に合った活用方法がわからない」と悩んでいませんか?
適切な保存形式を理解しないと、画質の劣化やストレージの無駄遣いにつながり、用途に合った活用が難しくなる恐れがあります。
本章では、PNG・JPEG・WEBPなど各保存形式の特徴と用途を詳しく解説します。
拡張子ごとの用途
画像形式は、画質と用途のバランスを考えて選ぶ必要があります。
PNG形式は、画質を損なわず、細部を保持したい場合に適しています。イラストやデザイン素材の保存に最適で、編集作業が必要な場合にも推奨されます。また、透明度情報を保持できるため、合成にも向いています。
JPEG形式は、データサイズを抑えながら実用的な画質を維持でき、ウェブサイトやSNSでの共有に適しています。品質設定を高めにすると、画質の劣化を最小限に抑えられます。
WEBP形式は、最新の圧縮技術により、PNGに近い画質を維持しながらJPEG並みの軽量化を実現します。特にウェブサイトで、表示速度と画質のバランスが必要な場合に効果的です。
用途に応じた適切な形式を選ぶことで、画像の品質と効率を両立できます。
生成画像の応用事例
Stable Diffusionで生成した画像は、さまざまな用途で活用可能です。それぞれの目的に応じた保存形式を選ぶことで、画像の価値を最大限に引き出せます。
ウェブコンテンツでは、画像のロード時間と品質のバランスが重要です。ブログのアイキャッチやSNS投稿には適度に圧縮したJPEG形式、商品画像やポートフォリオのように画質を重視する場合は、PNG形式がおすすめです。
印刷物では、高解像度と色情報の保持が求められます。パンフレットやポスター用にはPNG形式で保存し、必要に応じてTIFF形式に変換すると、印刷品質を確保できます。
デザイン素材では、編集のしやすさが重要です。ロゴやアイコンの制作には、透明度を保持できるPNG形式が適しており、他のデザインへの組み込みも容易です。
オリジナルデータはPNG形式で保存し、用途に応じて必要な形式に変換する運用が効果的です。
- 編集予定のある画像は必ずPNG形式で保存
- ウェブ用途では画質設定を確認しながらJPEG形式で保存
- 重要な画像は複数の形式でバックアップを作成
- ファイル名に生成時の設定情報を含める
これらの知識を活用することで、生成画像を目的に応じて最適な形式で保存し、効果的に活用することができます。
2026年5月30日(土)、SHIFT AI × romptn ai「クリエイターセミナー」を開催します!
第一線で活躍中のクリエイターが、最新の画像生成AIを使いながら、画像生成AIを活用した収益化についてお話しします。
無料で参加していただけますので、「画像生成AIを使って収益化したい!」「SNSで投稿したい!」という方は、ぜひ以下のボタンからセミナーにご参加ください。
スキルゼロから始められる!
無料AIセミナーに参加する画像生成の精度向上に便利な拡張機能の使い方
Stable Diffusionの画像生成精度を高めるために、さまざまな拡張機能が開発されています。
ここでは、特に効果的な拡張機能とその使い方について解説します。
ControlNetの活用
ControlNetは、画像生成の構図や姿勢を制御できる強力な拡張機能です。
基本的な使い方として、参考となる画像やスケッチを用意し、それをガイドとして新しい画像を生成します。
人物の姿勢を指定したい場合は、ポーズ画像を入力することで、同じポーズで異なるキャラクターを生成できます。
線画からの彩色や、風景写真を基にした画風変更なども可能です。
Dynamic Promptsの活用
プロンプトのバリエーションを自動的に生成できる拡張機能です。
基本となるプロンプトに変数を設定することで、複数のバリエーションを効率的に生成できます。
色や表情、背景などの要素を自動的に変更しながら、連続して画像を生成が可能です。
拡張機能を適切に組み合わせることで、作業効率も大幅に向上させることができます。
- 拡張機能は最新版を使用する
- 機能の組み合わせは段階的に試す
- 生成結果を確認しながら設定を調整する
- 使用頻度の高い設定はプリセットとして保存する
これらの拡張機能の活用により、Stable Diffusionでの画像生成の可能性が大きく広がります。
代表的なモデル紹介
Stable Diffusionの画像生成において、モデルの選択は出力される画像の品質と特徴を決定する重要な要素です。
現在人気の高いモデルについて、特徴と具体的な使い方を解説します。
モデルの特性を理解し、目的に応じて適切に選択することで、より質の高い画像生成が可能になります。
| モデル名 | 特徴 | 用途 |
|---|---|---|
| MeinaMix | ・安定した品質で汎用性が高い ・アニメ調のキャラクター生成に優れている | ・キャラクターイラスト ・立ち絵 ・表情の豊かな人物画 |
| epiCRealism | ・写実的な人物や風景の生成に優れている ・自然な質感表現ができる | ・ポートレート写真 ・風景写真 |
| blue_pencil-XL | ・高解像度で生成する能力に優れている ・背景や光の表現が強化されている | ・イラストレーション ・アニメーション |
| t3 | ・女性のポートレートや細部の質感表現に優れている | ・ポートレート写真 ・風景写真 |
1つ目はアニメ調モデル「MeinaMix」です。安定した品質で汎用性が高く、アニメ調のキャラクター生成に優れています。
キャラクターイラストや立ち絵、表情の豊かな人物画の生成に最適です。
>MeinaMixのダウンロードはこちら
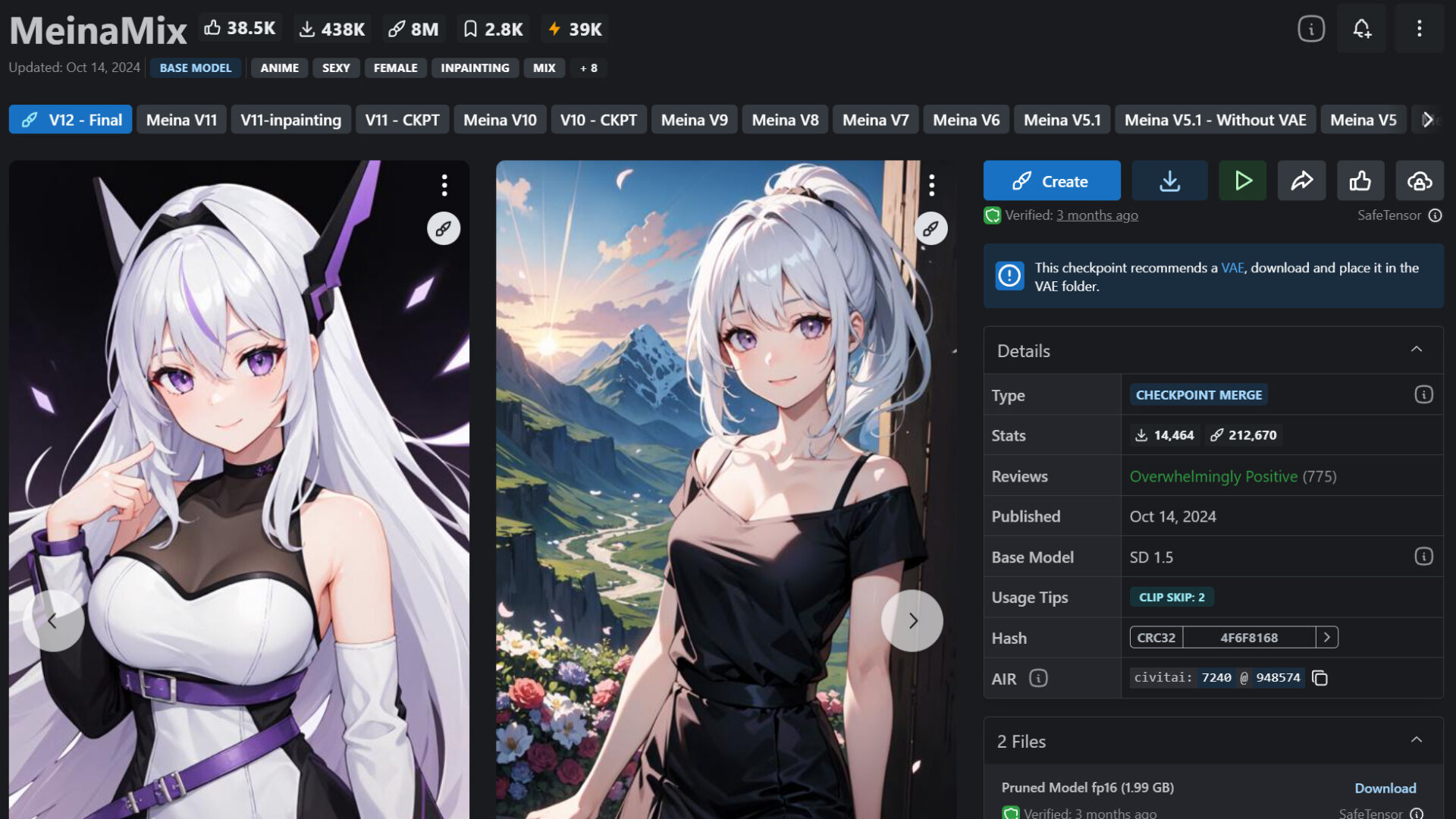
2つ目は実写系モデル「epiCRealism」です。写実的な人物や風景の生成に優れ、自然な質感表現ができるため、ポートレート写真や風景写真の生成に効果的です。
>epiCRealismのダウンロードはこちら
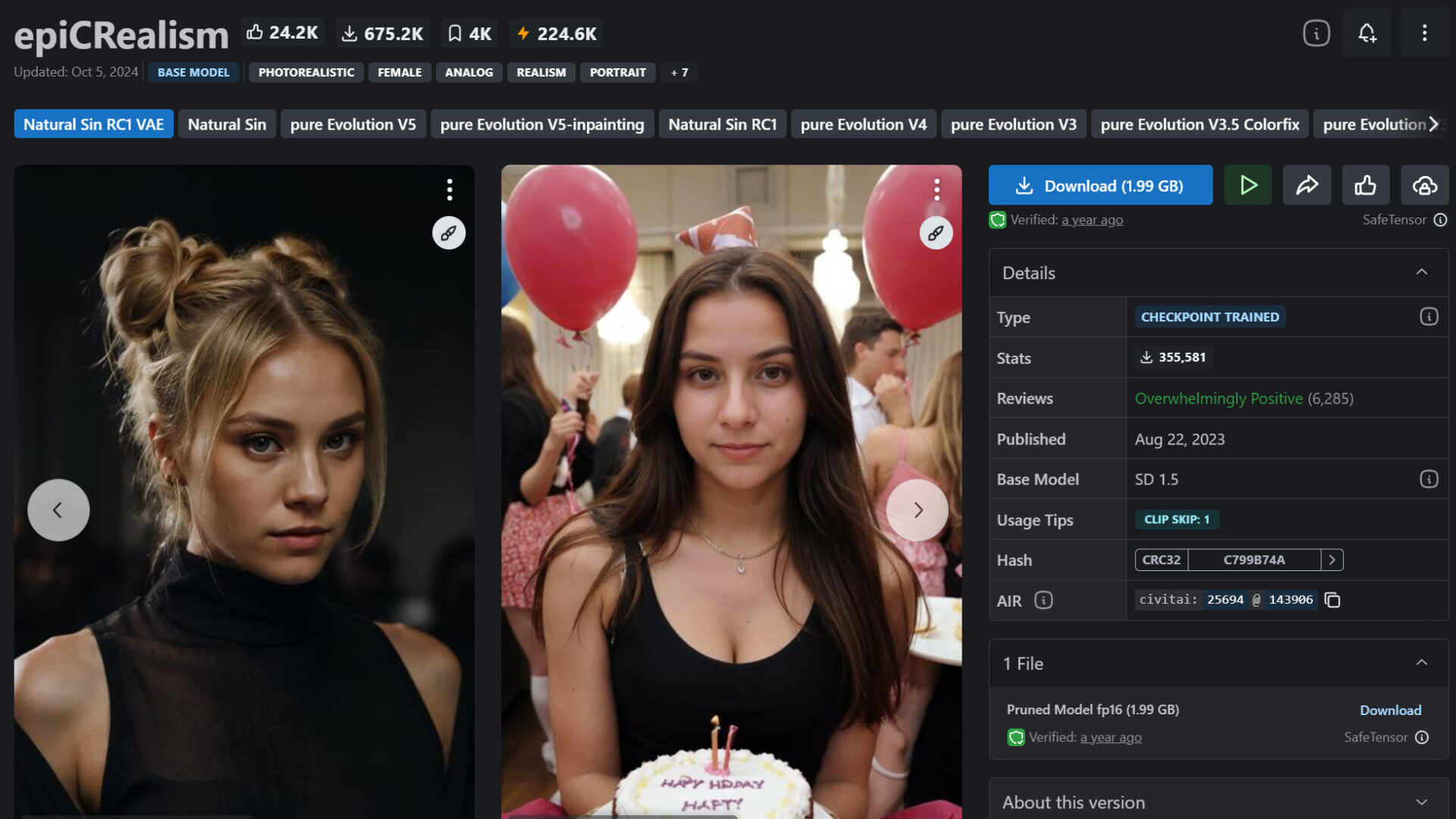
3つ目はSDXL 1.0アニメ調モデル「blue_pencil-XL」です。高解像度で生成する能力に優れ、特に背景や光の表現が強化されています。
イラストレーションやアニメーション制作に最適です。
>blue_pencil-XLのダウンロードはこちら
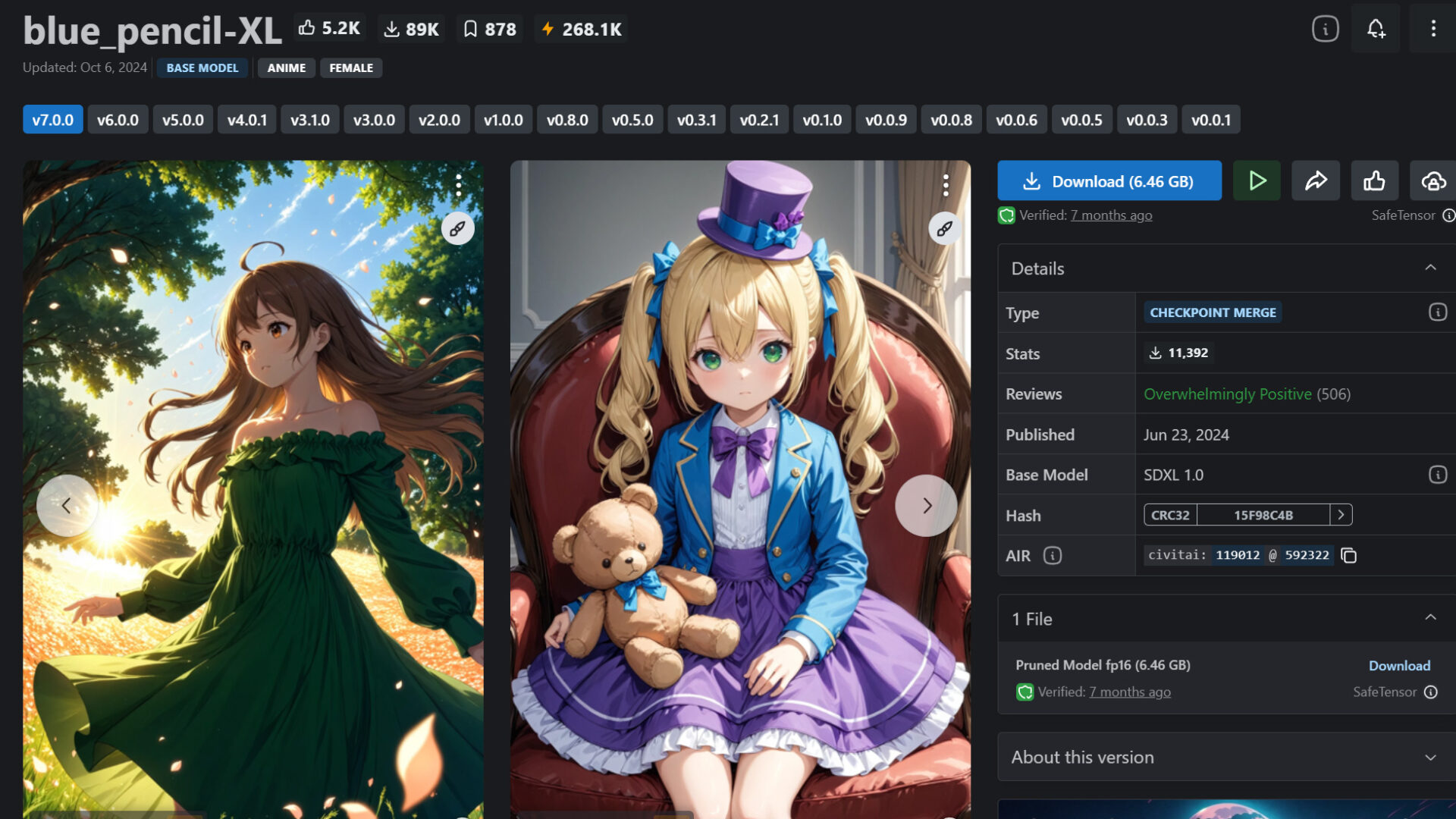
4つ目は実写系モデル「t3」です。女性のポートレートや細部の質感表現に優れており、ポートレート写真や風景写真の生成に適しています。
>t3のダウンロードはこちら
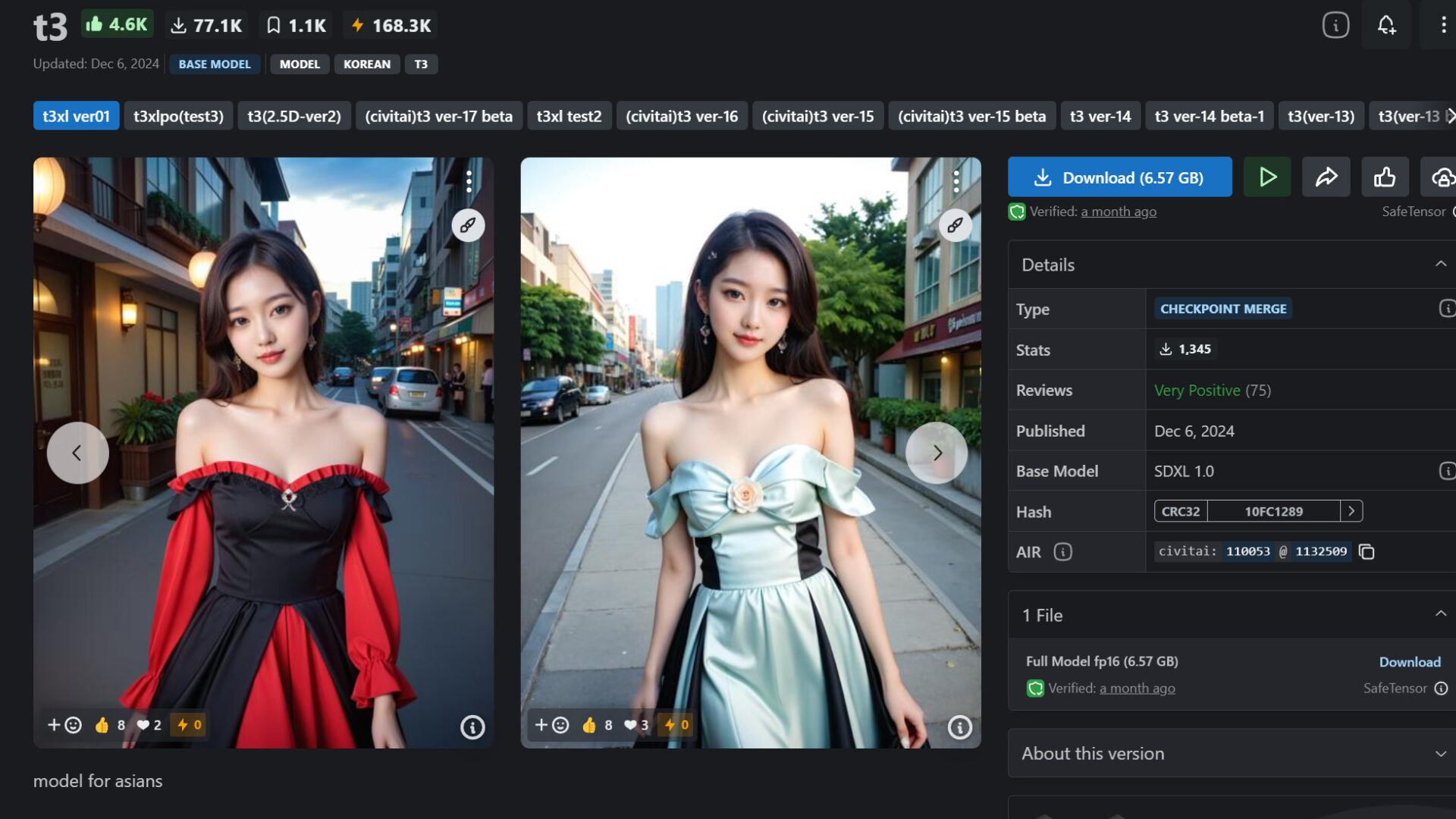
【中級】Stable Diffusionスキル向上に役立つツール3選
「基本操作は覚えたけれど、もっと思い通りの画像を作りたい」「画像の品質をさらに高めたい」と感じていませんか。
多くのユーザーが、Stable Diffusionの基本機能だけでは表現の限界に悩んでいます。
補助ツールの使い方を知らないと、画像生成の可能性を制限してしまい、試行錯誤に多くの時間を取られてしまいます。
本章では、画像の品質と表現力を高める「LoRA」「VAE」を詳しく解説します。
思い通りの画像を作るためのLoRAとは
LoRA(Low-Rank Adaptation)は、特定の特徴やスタイルを効率的に学習させた追加モデルです。主に以下の種類があります。
- キャラクタースタイル系:特定のキャラクターの特徴を再現
- 画風系:特定のアーティストや作品の画風を再現
- ポーズ系:特定のポーズや構図を制御
LoRAでは、基本モデルに組み合わせることで、より細かな表現の制御が可能になります。基本的な使い方は以下のとおりです。
- モデルの配置:「models/Lora」フォルダに.safetensorsファイルを配置
- プロンプトでの呼び出し:「lora:モデル名:強度」の形式で指定
今回は、顔が韓国人のようになる「koreanDollLikeness_v15」を用いて生成してみました。適用する前と後の生成例を紹介しますので、ぜひ見比べてみてください。
>koreanDollLikeness_v15のダウンロードはこちら
適用前のプロンプト
masterpiece, best quality, 1girl, cute face, detailed eyes
適用後のプロンプト
masterpiece, best quality, 1girl, <lora:koreanDollLikeness_v15:0.7>, cute face, detailed eyes※強度は0.1から1.0の間で調整しましょう。高すぎると画像が不自然になる場合があります。


画像の色彩と質感を向上させるためのVAEとは
VAE(Variational Auto-Encoder)は、画像の色調や質感の表現に大きく影響を与える重要な要素です。適切なVAEの選択により、生成画像の品質を大きく向上させることができます。
主要なVAEとそれぞれの特徴は以下のとおりです。
| VAE | 特徴 |
|---|---|
| vae-ft-mse-840000-ema-pruned | 汎用的で安定した結果が得られる |
| animevae.pt | アニメ調の画像に適している |
| kl-f8-anime2.ckpt | 色彩の再現性が高い |
VAEは、以下のポイントにそって選択するようにしましょう。
- 使用するモデルとの相性
- 生成したい画風との整合性
- 処理速度とのバランス
また、VAEの基本設定は以下のように行います。
- 配置場所:「models/VAE」フォルダ
- 設定方法:Settings画面のVAE項目で選択
【上級】画像生成のクオリティを向上させるStable Diffusion上の設定
「画像の品質をさらに上げたい」「複数モデルの特長を組み合わせて使いたい」「高解像度の画像を生成したい」と感じていませんか。
基本機能だけでは物足りなくなった方に向けた、画質向上の上級テクニックをご紹介します。
基本機能に頼り続けると、生成画像のクオリティに限界を感じることが増え、クリエイティブな可能性を十分に活かせなくなります。試行錯誤の時間も増えて非効率的です。
本章では、複数モデルを組み合わせる「モデルマージ」の手順や、高解像度化を実現する「アップスケーリング」の方法を詳しく解説します。
モデルマージと微調整の基本
モデルマージは、複数のモデルの特徴を組み合わせることで、新たな表現を可能にする高度な技術です。適切なマージにより、各モデルの長所を活かした画像生成が可能になります。
モデルマージを行うために、まずはCheckpoint Mergerをインストールする必要があります。インストールは以下の手順で行ってください。
- Stable Diffusion WebUIの「Extensions」タブを開く
- 「Install from URL」を選択
- URLを入力:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
- 「Install」ボタンをクリック
- インストール完了後、WebUIを再起動
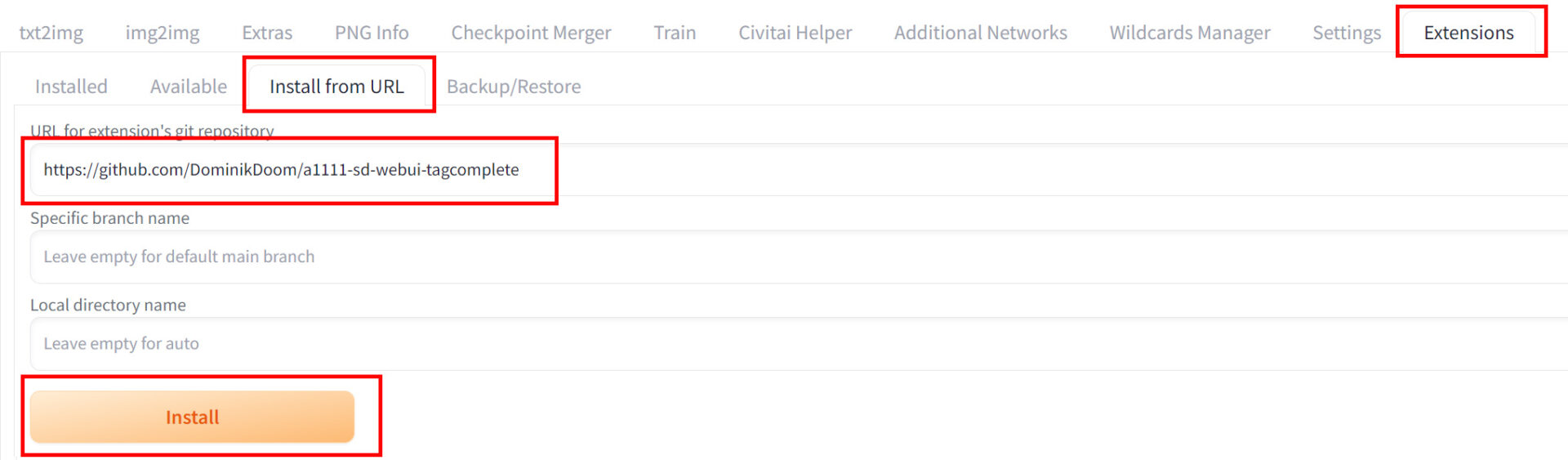
インストールが完了して、WebUIを再起動したら、次はマージの基本設定に移ります。以下の手順で行いましょう。
- 「Checkpoint Merger」タブを開く
- Primary model(ベースモデル)を選択
- Secondary model(特徴を追加するモデル)を選択
- Tertiary model(オプション)3つ目のモデルを選択
- Interpolation Methodは「Weighted sum」を推奨
- Multiplierでマージ比率を設定(0.1から0.9)「0.5」ではmodel(B)の割合を半分「0.3」ならmodel(A)は「0.7」、model(B)は「0.3」
- Custom Nameはマージ後のモデル名入力
- Mergeボタンをクリックしマージ開始
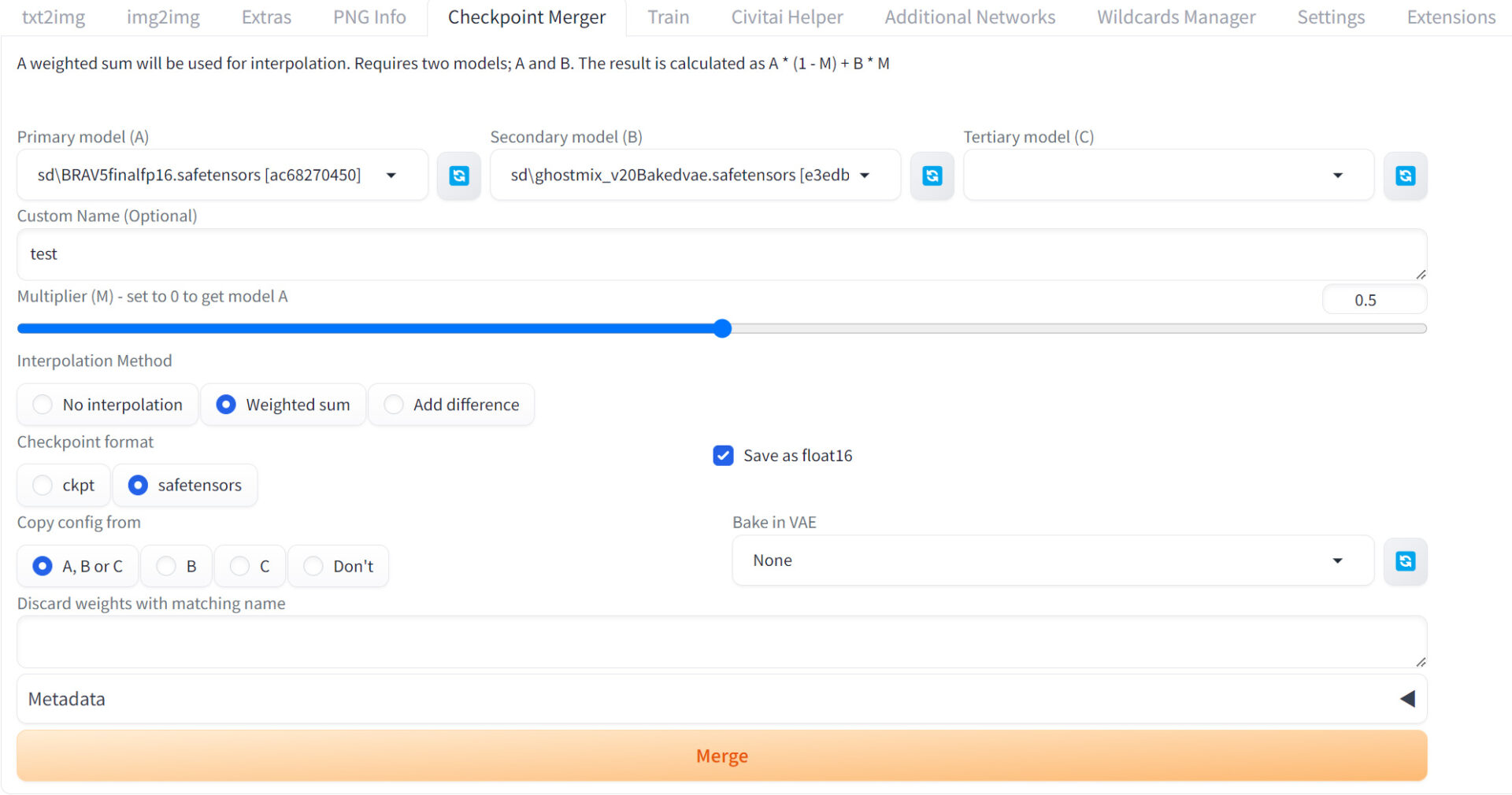
Multiplierでは、マージ比率を「0.1から0.9」の幅で設定可能です。「0.5」ではmodel(B)の割合を半分、「0.3」なら「model(A):model(B)=0.7:0.3」になります。
完成したモデルはモデルが保存されているフォルダに格納されます。
また、マージには十分なVRAM(8GB以上推奨)が必要です。元モデルのバックアップを必ず作成し、マージ比率は段階的に試験することを推奨します。
商用利用する場合は、各モデルのライセンスを確認しましょう。
アップスケーリング(高解像度化)の手順
アップスケーリング(高解像度化)の手順を、以下の順序で解説します。
- 初期生成設定
- Hires.fixの設定
- 出力を調整
初期生成設定
まずは、最終的な画質を左右する重要な土台となる適切な基本設定から始めます。
基本サイズは「512×512」もしくは「768×768」を選択し、サンプリングステップは「20-30」、CFG Scaleは「7-12」の範囲で設定しましょう。
Hires.fixの設定
画像の高解像度化には、Hires.fixを活用します。Upscaler(以下画像の左上)の選択が重要なので、以下の3つから目的に応じて選びましょう。
- Latent:処理速度を重視する場合
- R-ESRGAN:細部の品質を重視する場合
- Ultimate SD Upscale:バランスの取れた結果を求める場合
次に、以下の重要なパラメータを設定します。
- Upscale by:1.5-2.0倍で設定(大きすぎると処理時間が増加)
- Hires steps:15-20程度に設定
- Denoising strength:0.3-0.6の範囲で設定(低いほど元画像の特徴を維持)

出力を調整
画像を生成したら、より最適な出力になるよう調整していきます。
アップスケール処理は段階的なアプローチで進めます。まず基本画像を生成して品質を確認し、一次アップスケールを実行しましょう。
結果を確認し、必要に応じて細部を調整し、最終的なアップスケールを実行してください。
生成後、さらに以下の点に注意して画質を調整します。
- シャープネスを適切に調整
- ノイズ除去レベルを確認
- 色調バランスを必要に応じて補正
アップスケーリング(高解像度化)を実践するうえでの注意点は以下のとおりです。
- VRAMの使用量を常に監視する
- 処理時間と品質のバランスを考慮
- 重要な生成結果はこまめにバックアップ
- 設定変更は段階的に行う
これらの手順に従うことで、高品質なアップスケーリングを実現できます。初めは基本的な設定から始め、段階的に詳細な調整を加えるのがおすすめです。
Stable Diffusionの商用利用・著作権
Stable Diffusionを商用目的で活用したいと考えていませんか。
商用利用には、モデルや拡張機能のライセンスを正しく理解することが不可欠です。適切なライセンス管理を行わないと、意図せず著作権や規約に違反してしまう可能性があります。
本章では、Stable Diffusionの商用利用に関する基本的なルールや、注意すべきポイントをわかりやすく解説します。
モデルのライセンス確認方法や、拡張機能を使用する際の注意点についても詳しく説明します。
モデルの商用利用ルールと注意点
Stable Diffusionの基本モデルは、CreativeML Open RAILMライセンスのもとで提供されています。このライセンスでは、商用利用が基本的に許可されています。
ただし、違法なコンテンツや有害な用途での使用は禁止されています。生成された画像の著作権は、原則として画像を生成したユーザーに帰属します。
カスタムモデルを使用する場合は、より慎重な確認が必要です。たとえば、ChilloutMixは個人利用に限定されているなど、モデルによって利用規約が大きく異なります。
Civitaiで配布されているモデルの場合ライセンスは以下の部分で確認することができます。
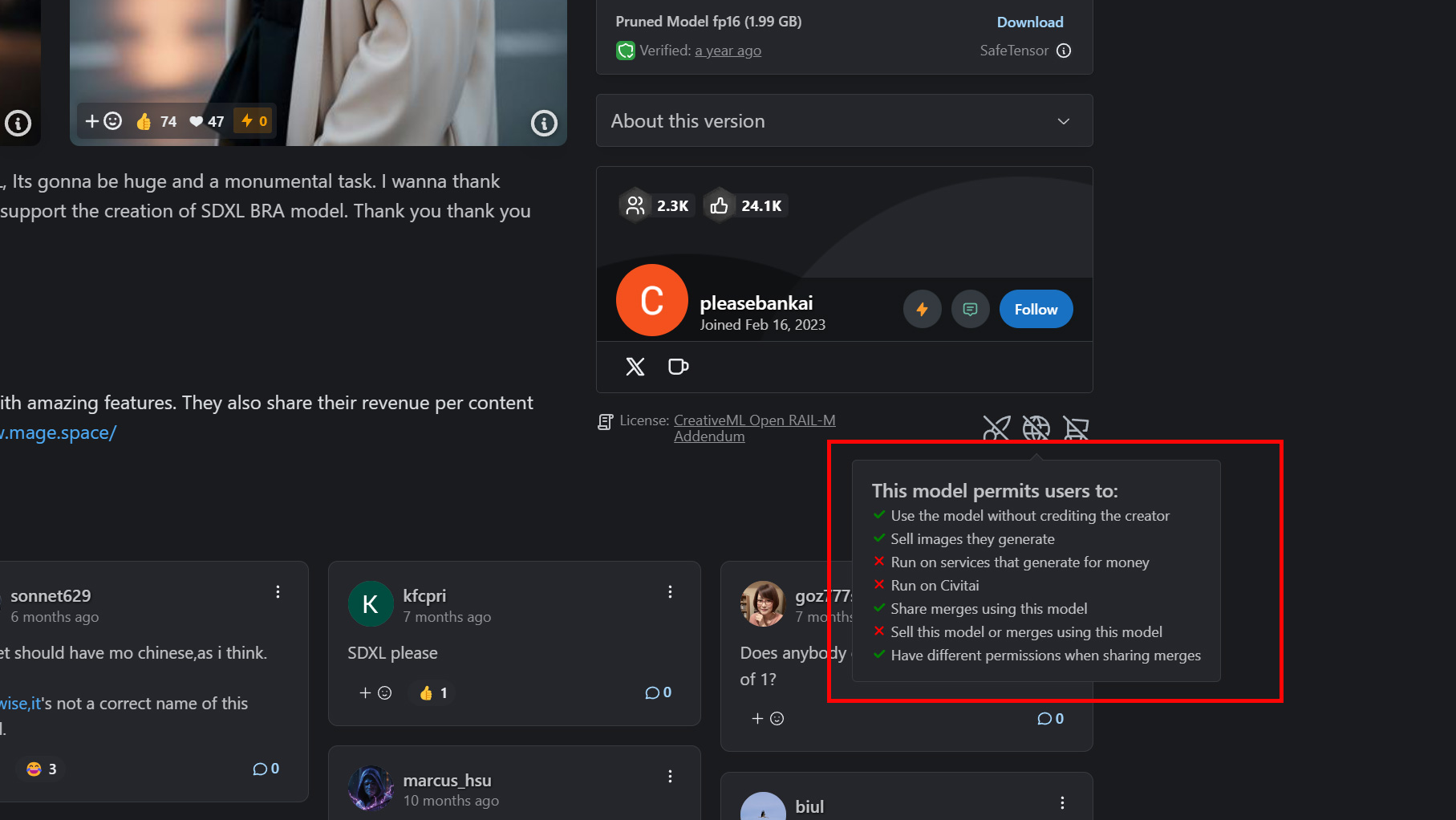
| 記載内容 | 意味 |
|---|---|
| Use the model without crediting the creator | クリエイターのクレジットを表示せずにモデルを使用する |
| Sell images they generate | 生成した画像を商業利用する(販売する) |
| Run on services that generate images for money | 画像生成サービスで利用し、収益を得る |
| Share merges using this model | このモデルを使用して作成したマージデータを共有する |
| Sell this model or merges using this model | このモデルや、作成したマージデータを販売する |
| Have different permissions when sharing merges | マージデータを共有する際に、異なる権限を適用する |
商用利用する際は、Sell images they generate にチェックが入っていることを確認してください。
また、同じモデルでもバージョン変更に伴い利用規約が更新される場合があるため、定期的な確認が重要です。
実務での運用においては、使用するモデルの利用規約をスクリーンショットで保存し、記録として残しておくことをおすすめします。
後から利用条件の確認が必要になった際にも、適切に対応することができます。
商用利用可能なモデルのリストを作成し、定期的に更新することで、安全な運用が可能になります。
拡張機能の商用利用ルールと注意点
拡張機能のライセンスは、GitHubページやREADMEファイルで確認できます。
ControlNetはMITライセンスで提供されており、商用利用が可能です。クレジット表記は任意で、改変や再配布も許可されています。
ただし、拡張機能で利用する個別のモデルやLoRAには別途ライセンス確認が必要です。本体だけでなく関連コンポーネントのライセンスもチェックすることが重要です。
ツールのライセンス情報はアーカイブ化して保存し、成果物の利用範囲を明確にしておきましょう。ライセンスに不明点がある場合は、開発者やコミュニティに直接確認するのが賢明です。
商用利用を検討する際は、法的リスクを最小限に抑えるため、専門家への相談もおすすめします。
これらのポイントを守ることで、Stable Diffusionを安全かつ効果的に商用活用できます。
Stable Diffusionを使いこなすためのポイント
Stable Diffusionは、適切な設定と知識で高品質な画像生成が可能な強力なツールです。基本操作を習得し、プロンプトの工夫やLoRA、VAEなど補助ツールを活用することで、より理想に近い画像が生成できます。
さらに、モデルマージやアップスケーリングなどの上級技術を学べば、独自性のある表現が可能になります。商用利用時には、ライセンスの確認と記録の保管が重要です。
本記事を参考に学習と実践を重ね、創造的な表現力を広げていきましょう。
Stable Diffusionを使いこなせるようになればさまざまなシーンで役立つはずです。
2026年5月30日(土)、SHIFT AI × romptn ai「クリエイターセミナー」を開催します!
第一線で活躍中のクリエイターが、最新の画像生成AIを使いながら、画像生成AIを活用した収益化についてお話しします。
無料で参加していただけますので、「画像生成AIを使って収益化したい!」「SNSで投稿したい!」という方は、ぜひ以下のボタンからセミナーにご参加ください。
スキルゼロから始められる!
無料AIセミナーに参加する目次


執筆者

画像・動画生成AIクリエイター/インフルエンサー
吉口智晃
2023年より画像・動画生成AIクリエイターとして活動し、最新技術やトレンドをキャッチし常に最先端の作品を制作。SNS総フォロワーは6万人。
NVIDIA製GPU(RTX 3060/RTX 4070)搭載の2台のゲーミングPCで画像・動画を制作。これまでAIで生成した画像・動画は100万点以上。SHIFT AIでは特別講師を務める。
制作実績:トヨタ自動車・伊藤園など











スキルゼロから始められる!