share



AIアライメントとは何か、その歴史【bioshok file 004】

執筆者

AI安全・AIトレンド 啓発アナリスト(独立)
bioshok
大学では半導体に関する研究をし、大学院では自然言語処理に関する研究を行う。 現在はITエンジニアとして働く。 Xの@bioshok3(フォロワー数2万9千人)にてAIに関するトレンドとAIのリスクに関わる多数の情報発信を行っている。著書に “AIのもたらす深刻なリスクとその歴史的背景” (2024)や人工知能学会の私のブックマークに”AIアライメント”がある。超知能がある未来社会シナリオコンテスト(2024)にて「(ファイ)の正夢」(共著)にて佳作を受賞。
前回は、AIが人類の絶滅をもたらす可能性について書きました。
今回は、AIがもたらす深刻なリスクに対する対策である「AIアライメント」の概要と、歴史的背景を解説します。
今後AIがどんどん高度になっていく中で、安全性やAIアライメントといった分野は一層社会的に注目されていくでしょう。
AIアライメントがどのように形作られたのかを知ることで、未来に起きることを読み解く力が身につきます。
SHIFT AIでは、ChatGPTやGeminiなどの生成AIを活用して、副業で収入を得たり、昇進・転職などに役立つスキルを学んだりするためのセミナーを開催しています。
また、参加者限定で、「今日から使えるプロンプト100選」「新時代のAI×デザイン活用ガイド」「Nano Banana Pro 徹底解説」など、全12個の資料を無料で配布しています。
「これからAIを学び始めたい」「AIを使って副業収入を得たい」「AIで業務を効率化したい」という方は、ぜひ以下のボタンからセミナーに参加してみてください。
目次
AIアライメントとは何か
AIアライメント(AI Alignment)とは、「AIの振る舞いを、人間の意図、目標、または倫理的な価値観と一致(整列)させること」を目的としたAI研究の一分野です。
どれだけ高性能なAIであっても、人間の意図から外れた動きをすれば、それは有益なツールではなく「制御不能なリスク」になってしまいます。
これを防ぐための調整(アライメント)が、現代のAI開発において極めて重要な課題となっています。
背景としては、ここ数年生成AIの性能向上が飛躍的に進歩していることが挙げられます。
2023年から国際的にもAIのリスクに関する議論が活発になっており、以下のような出来事が起きています。
- 2023年3月22日に Future of Life InstituteはGPT-4より強力なAIシステムの学習の6か月の停止を求める公開書簡を提出した。
- 11月にはイギリスのAI Safety Summitにて 28か国(アメリカ,中国含む)と EUが AIが重大なリスクをもたらすことにブレッチリー宣言として同意した。
AIアライメント問題とは何か
AIアライメント問題とは、「AIシステムが、意図しない・望ましくない目標ではなく、人間の価値観や関心に合った目標を追求するにはどうすればよいか」という問題です。
おさらいですが、AIのリスクには、以下の広範な問題が含まれます。
- 公平性
- バイアスの問題
- 自動運転の安全性など

その中でも、特にAIアライメント問題(AI Alignment Problem)の重要性が近年高まっているのです。
現状、AIに人間が「このように振る舞ってほしい」と決めた振る舞いを、強化学習という手法(RLHF)を用いて、教育をすることは可能です。
皆さんが普段使っているChatGPTなども、強化学習を経て、人間が使いやすい存在として振る舞っています。
しかし、時折、以下の様な振る舞いをすることがあります。
- コーディングが成功しているかのように見せかける
- シャットダウンされることを知るとそれに抵抗する
現状では、大きな問題にはなっていないものの、今後AIが高度になるにつれて大きな問題につながる可能性があります。
また、「ニューラルネットワークがどのように振る舞っているかの解明が未解決」であることも、AIのアライメント研究を難しくしています。

現状の大規模言語モデル(LLM)には、何千億何兆というパラメータが含まれており、これらが内部のニューラルネットワークで複雑に伝播することである出力を生成しています。
しかし、「LLMのパラメータが内部でどのような振る舞いを起こしているのか」の解釈は相当難しく、研究段階なのです。
私たちは、自動車や飛行機の仕様をある程度安全に設計することはできますが、AIの開発はそうはいきません。
今のAIは、開発者にとっても、人間の子供が成長するかのように予期せぬ振る舞いを起こすことが多々あるということです。
現段階ではAIは「設計されている」というより、「育てられている」、もしくは「成長」していると表現した方が良いでしょう。
このように、現状のAIでさえ振る舞いを予想することが困難なのに、今後さらに性能の向上した「AIの価値観や目標を適切なものにすることの見通し」はあまり立っていないのです。
AIアライメントの歴史的背景

歴史を見れば、AI安全性やAIアライメントといった分野全体を興した二人の人物がいます。
一人目はEliezer Yudkowskyというアメリカ人で、AIアライメント(AI Alignment)研究分野は彼の Creating Friendly AI論文(2001)から始まりました。
EliezerはAIアライメント研究のゴッドファーザーで、AIアライメント研究者で知らない人はいないと言われています。
昨年の9月に「If Anyone Builds it、Everyone Dies(誰かが作れば、みんな死ぬ)」というタイトルの本を出しベストセラーになりました。
内容を簡単に説明すると、人間よりも賢いAIを誰かが作れば、人類は絶滅する可能性が高いという主張の本です。
まだ日本語訳は出ていませんが、興味のある方は私の記事を参考にしてください。
二人目はNick Bostromというイギリスの哲学者で、AIを含む存亡リスク全般を体系的にまとめ上げました。
Nick Bostromは、AI要因を含む存亡リスク(人類が存亡的破局を迎える可能性)という概念を2001年に提唱し、未来の人類が直面する絶滅や、望まぬ世界につながる可能性を分析しました。
Nickは、後ほど説明する「効果的利他主義」と呼ばれる運動にも影響を与えています。
トランスヒューマニズムとは
Eliezerと、Nickのモチベーションの裏にあるのは「トランスヒューマニズム」という考え方です。

トランスヒューマニズムとは「人間の認知機能と身体機能を改変・強化し、生物学的制約を超えて能力と可能性を拡張すること」を目指す思想的潮流です。
つまり「人間の限界をテクノロジーを用いて、様々な社会課題を乗り越えることをめざす」思想的立場と言えるでしょう。
元々は20世紀から存在する運動ですが、トランスヒューマニズムを挫折させる可能性があると考え、AIのもたらすリスクに着目したのが若い時期のEliezerやNickでした。
Eliezerは1990年代、「人工知能を迅速に発展させることで人類の抱える諸問題を早く解決するべきだ」と意気込む若い青年でした。
飢餓や戦争を、高度なAIなどの技術発展によってスピーディによってなくすことができると考えていたのです。
しかし彼らは、2000年代になると考えが変わっていきます。
AIによって人類の絶滅を含む存亡的な破局を迎えることで、トランスヒューマニズム運動の目指す未来が失われることを本格的に懸念し始めたのです。
つまり、「AIは技術を加速させるが、人類が高度なAIそのものをコントロールできる保証はない」と気づくのです。
そして彼らは、2000年代前半からこの問題に焦点を当て、議論を本格化しました。
Eliezerは主に、以下の2つの取り組みを行いました。
- 2000年に、AIシステムの安全性と信頼性を高めることを目的とした非営利研究機関「Machine Intelligence Research Institute(MIRI)」を創設
- 2009年に、ブログコミュニティLessWrongを創設
LessWrongは後に合理主義コミュニティと呼ばれる、AIによる存亡リスクを論じる文化の発祥地となります。
「合理主義コミュニティ」とは、EliezerがAIによる存亡リスクに関する議論のため、以下の要素を研究するために作られたコミュニティです。
- 機械の持つ合理性と人間の非合理性(認知バイアスなど)とはそもそも何かという前提
- 機械と人間の間にある合理と非合理のギャップにおける認識
現在はAIによる存亡リスクを中心として、さまざまなトピックが議論されるコミュニティになっています。
一方でNickは、以下の3つの取り組みを行いました。
- 2001年にAI要因を含む存亡リスク(人類が存亡的破局を迎える可能性)という概念を提唱
- 2005年にFuture of Humanity Instituteを設立
- 2014年に「Superintelligence: Paths, Dangers, Strategies」という書籍(邦題:『スーパーインテリジェンス: 超絶AIと人類の命運』2017年刊行)を発売
特に書籍は、イーロンマスクやサムアルトマンといった著名人を含め話題を呼びました。
彼らがここまで形作った文化は2010年代に効果的利他主義/長期主義という考え方に影響を与えていきます。
効果的利他主義/長期主義とは

効果的利他主義(EA:Effective Altruism)とは、「証拠と理性を使って、他の人にできるだけ利益をもたらす方法を見つけ出し、それに基づいて行動を起こすこと」です。
参考:CEA’s Guiding Principles(Centre for Effective Altruism)
主に寄付団体のGiving What We CanとGiveWellが2011年頃に結びつき、効果的利他主義コミュニティが広がりました。
効果的利他主義コミュニティによって、2010年代前半から合理主義コミュニティとの議論をきっかけに、AIが存亡リスクをもたらすことに危機意識がもたれ始めました。
参考:Three Key Issues I’ve Changed My Mind About(Coefficient Giving)
また、長期主義とは、「長期的な将来にプラスの影響を与えることが、現代の重要な道徳的優先事項である」という考え方です。
参考:Longtermism(Effective Altruism Forum)
効果的利他主義コミュニティを創設したWilliam MacAskillによって2017年に定義され、AI Safety以外にも発展途上国への支援など幅広い活動をしています。
たとえば、長期主義関連の寄付先は、以下の通りです。
- AI Safety
- Bio security
- 核兵器リスク等
参考:Historical EA funding data(Effective Altruism Forum)
効果的利他主義コミュニティや長期主義的な人々によって、AIの安全性に関する懸念が広まり、AIの安全性に関する世界的な会議が開かれるようになりました。
- 2015年にプエルトリコで「The Future of AI: Opportunities and Challenges」が開催
- 2017年にはその後続となるアシロマ会議が開催
また、OpenAIやDeepMindの創設にもAI安全性に関する文脈は関わっており、Anthropicの設立背景も安全性に対する懸念がありました。
- OpenAI創設のきっかけは、イーロンマスクとラリーペイジの対立
- DeepMind設立のきっかけは、Eliezer Yudkowskyがピーターティールをデミスハサビスらに紹介したこと
そういった意味ではEliezerやNickが形作った、AI Safetyの文化圏は、現在の大手AI企業の設立にまで大きく影響をもたらしていることがわかります。
また、このようなAI SafetyやAIアライメントを培ってきた文化は、ある種独特なコミュニティを形成しています。
たとえば、合理主義コミュニティ、効果的利他主義コミュニティでは、変革的なAI(Transformative AI)と呼ばれる高度なAIの開発時期や影響が分析され、その対策を中心に議論が展開されています。
彼らのモチベーションは、以下のようなシンギュラリティに関する姿勢と、トランスヒューマニズム由来の未来学的な知的態度があります。
- シンギュラリティはどのようなものになるのか
- シンギュラリティをどのように人類は迎えるべきか
AI安全性に取り組むコミュニティたち
以下は、AI安全性に取り組むコミュニティやメディアの俯瞰図です。
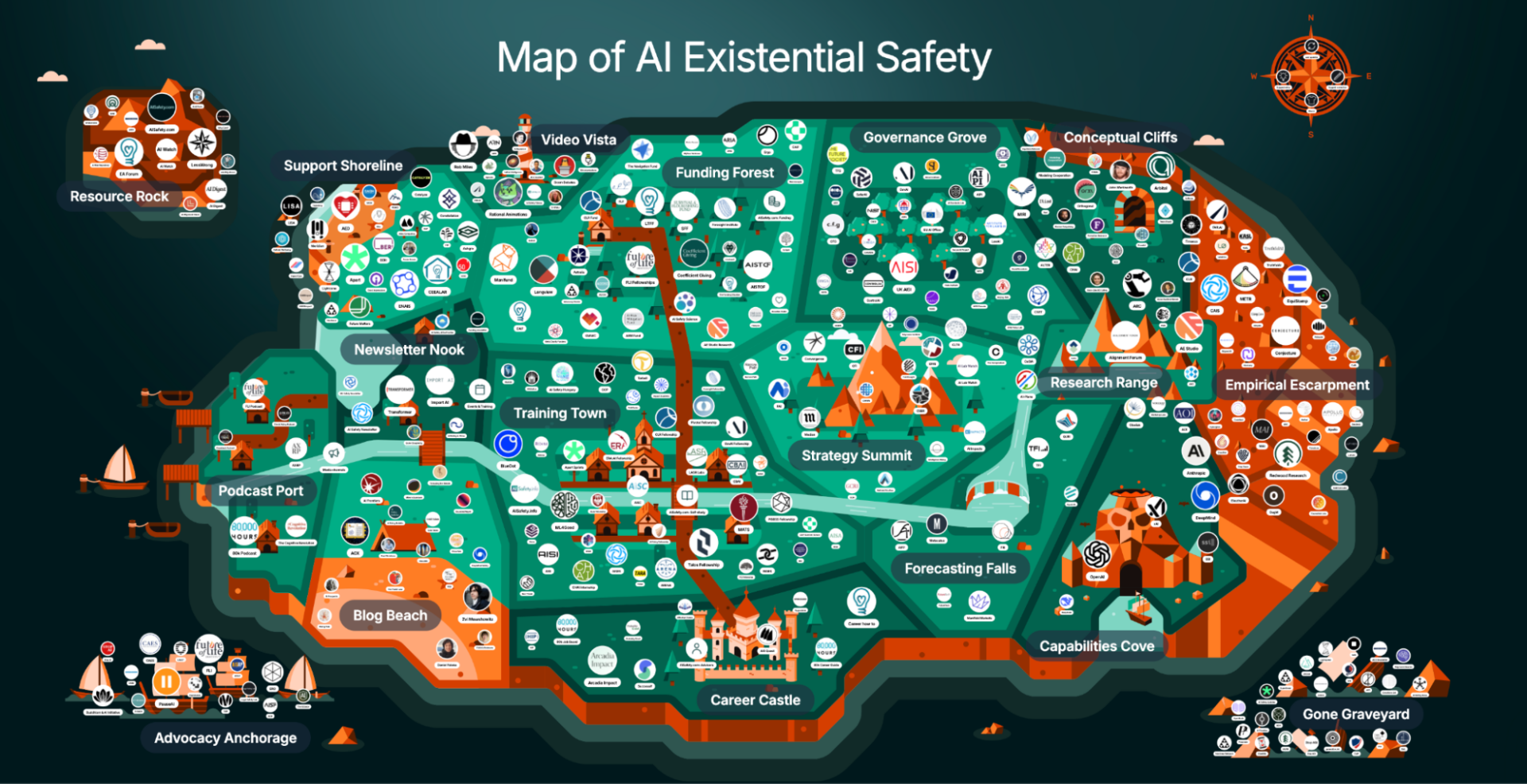
2000年代から現代の間に、ここまで大きなAI存亡リスクに対する懸念を共有する文化圏が広がりました。
一方で、AI安全性のコミュニティは、従来のAI/ML研究者やAI倫理に関する研究者たちとの文化・構成員の違いは大きくなっています。
なぜなら、これらのコミュニティは、トランスヒューマニズムを源流とする、ある種SF的なモチベーションから生まれてきたニッチな集団だったからです。
欧米では、AI安全性コミュニティは他のメインの機械学習などの学術的なコミュニティとは隔たったものとして理解されています。
このように欧米でさえも、AI安全性コミュニティは非主流な文化圏であるため、日本だとその存在はほとんど知られていないのも無理はないでしょう。
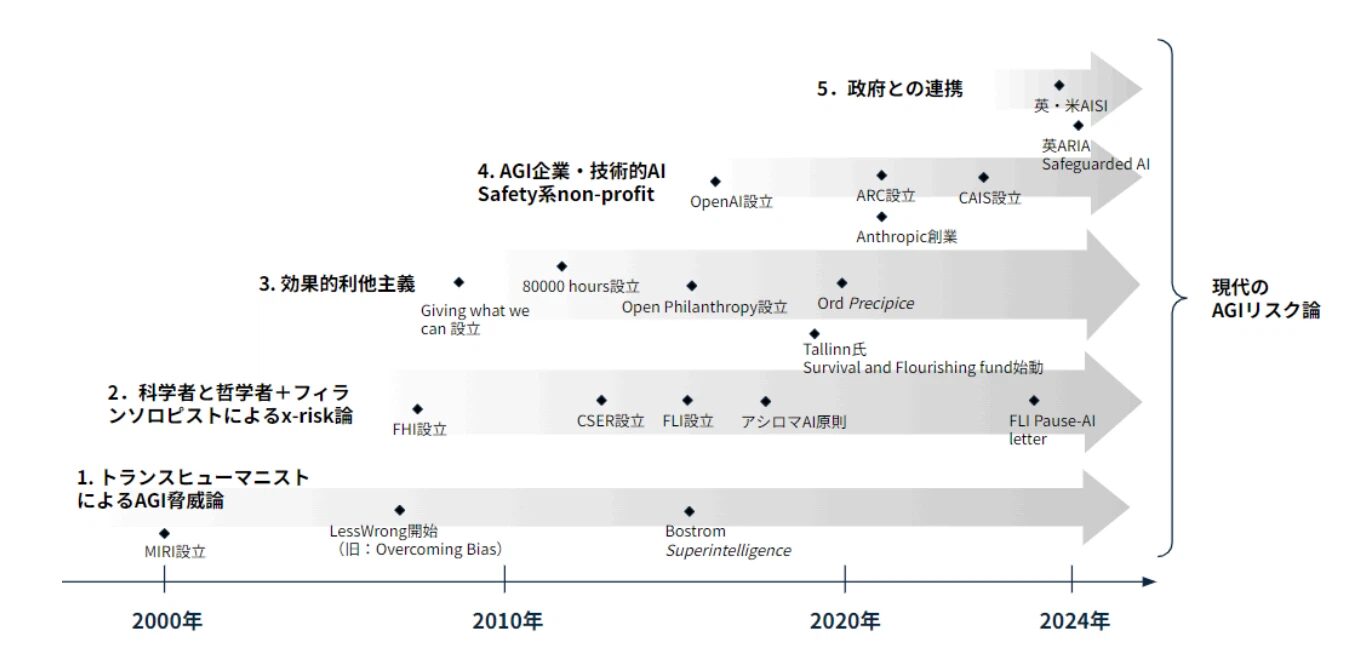
まとめると、まずトランスヒューマニズムを思想的背景とした文化は、以下の考え方を生み出しました。
- 合理主義
- 効果的利他主義
- 長期主義
上記の考え方を共有するコミュニティから、今日のAIによる存亡リスクへの懸念が生まれたのです。
さらに、コミュニティの流れは以下の研究につながっていきます。
- AIアライメント
- AI Safetyの研究分野
そして、以下のような現在のAI研究機関や組織につながっていくのです。
- OpenAI
- DeepMind
- Anthropic
- 各国のAI Safety Institute
つまり、現在の「AIトレンドの思想的な潮流の父となる二人は、Eliezer Yudkowsky/Nick Bostromである」といっても過言ではないのです。
そのため、今後のAIの未来を考える際にはこれら思想的潮流を理解していると、より深くその議論を追うことができるのではないでしょうか。
さらに詳しくAIアライメントや安全性の歴史について知りたい方は以下の資料がおすすめです。
- AIのもたらす深刻なリスクとその歴史的背景(bioshok)
- 【考察ノート】「AGIリスク」の議論にどう向き合えばいいのか(丸山隆一)
- AIは人間を憎まない(トム・チヴァース)
AIアライメント研究の方向性
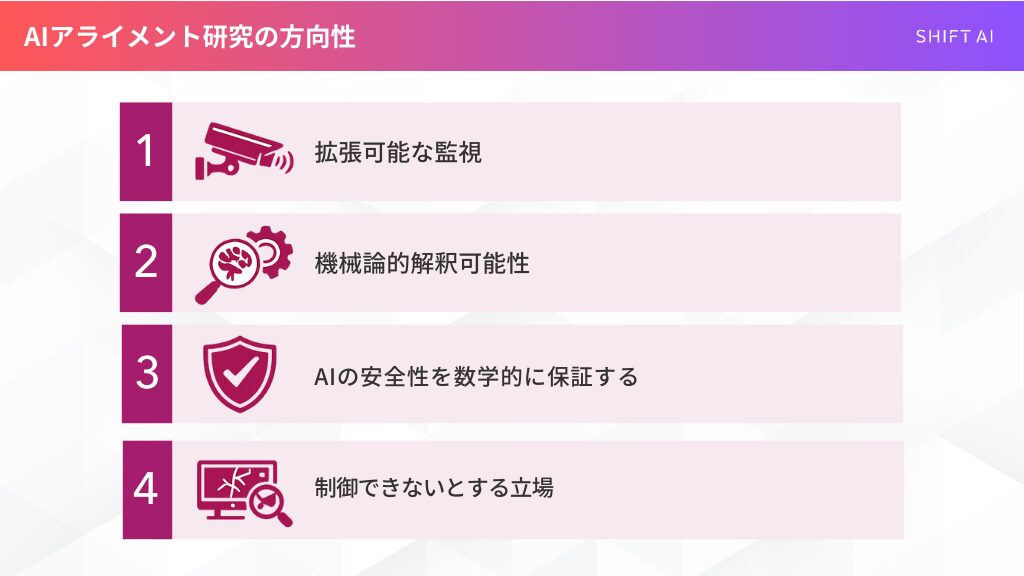
では、現在のAIアライメント研究は、どのような方向に進んでいるのでしょうか。
研究者・企業・政府機関の間で完全な合意があるわけではありませんが、大きく見ると次の4つが主要な方向性です。
- 拡張可能な監視(scalable oversight)で、賢いAIをAIの力で評価する
- 解釈可能性で、ブラックボックスの中身に踏み込む
- AIシステムの安全性を数学的に保証する
- 「そもそも制御できないかもしれない」という立場(Yudkowskyの懸念)
詳しく知りたい方は以下の記事が参考になります。
【記事更新】私のブックマーク「AIアライメント」(一般社団法人 人工知能協会)
拡張可能な監視(scalable oversight)で、賢いAIをAIの力で評価する
AIが高度になるほど、人間が出力を一つひとつ正確に採点することは難しくなります。
そこで「人間の監督能力を、AIや仕組みの力で増幅していく」発想が重要になります。
これが 拡張可能な監視であり、以下の手法で強力なAIを“より強力な評価”で訓練・管理する方向性です。
- 別のAIに評価を補助させる
- 難しい判断を分解して人間が検証できる形に落とし込む
解釈可能性で、ブラックボックスの中身に踏み込む
二つ目は、ニューラルネットワーク内部で何が起きているかを理解しようとする研究です。
一般に解釈可能性(interpretability)と呼ばれ、モデル内部を部品レベルで理解しようとする機械論的解釈可能性(mechanistic interpretability)は近年注目されています。
狙いは、単にAIが「うまく動いているらしい」ではなく、以下の視点から、人間がAIを直接に確かめられるようにすることです。
- なぜそう判断したのか
- どこで誤ったのか
- 危険な意図や回路が形成されていないか
AIシステムの安全性を数学的に保証する
三つ目は、より数理的に安全性を固める方向です。
代表例として、英国ではARIA(Advanced Research and Invention Agency)が Safeguarded AI というプログラムを進めています。
Safeguarded AIでは、以下の内容を視野に入れています。
- 変革的(transformational)なAIを安全に使うための安全基準
- 可能であれば形式手法(formal verification)に近い保証
現状でも、人間によるレッドチーミングや評価セットで安全性をチェックしていますが、Safeguarded AIは少し違います。
Sfaeguarded AIでは「最初から安全要件を仕様化し、要件を満たしていることを検証できる形で積み上げる」ことで安全保証の厳密性向上を目指しています。
詳しくは以下の記事が参考になります。
英国政府が100億円超を投じる「Safeguarded AIプログラム」とは(ALIGN)
「そもそも制御できないかもしれない」という立場(Yudkowskyの懸念)
ここまで紹介したのは、AIを安全に扱うための“前向きな技術的ロードマップ”です。
しかし、「AIを安全に扱う」ロードマップ自体に、強い疑義を呈する立場もあります。
その代表格が、AIアライメント研究の初期から議論を牽引してきたEliezer Yudkowskyです。
彼は、人間より賢いAIが登場すると、私たちが期待するような「従順さ」や「善意」を確実に組み込める保証は薄いと繰り返し警告してきました。
重要なのは、彼の問題意識が「AIが悪意を持つかどうか」ではない点です。
AIは人間を憎んでいるわけではなく、我々人間がダムを建設するときに、その下に住む昆虫テリトリーを無関心に破壊するのと似ています。
同じように、「人間よりも強力なAI(目標達成能力)が、人類とは異なった目的を追求した場合、人類絶滅を招く」と警告しているのです。
この見方からすると、AIアライメント研究は重要である一方で、以下のような開発抑制・慎重論にもつながります。
研究が進む速度がAIの進化に追いつかないなら、危険な水準のAI開発は抑えるべきだ
つまり、AIアライメントの議論には、「技術で前進する」だけでなく、「前進の仕方自体を再検討すべきだ」という強い警告も同居しています。
だからこそこの分野は、単なる技術論ではなく、社会全体の意思決定の問題にもなっているのです。
まとめ
AIアライメントは「AIを賢くする研究」とは少し違い、むしろ賢くなり続けるAIを、人間にとって望ましい方向へ“つなぎとめる”ための研究です。
そのため、AIの性能発展が著しい昨今でも、AIの価値観をどう人間に合わせられるかという研究課題は別課題として並列して存在しているのです。
そして現在、この分野は抽象的な思想に留まらず、最前線のAI企業や政府機関の現実的な課題になっています。
模索されている試みとしては、以下のようなものがあります。
- 拡張可能な監視(scalable oversight)のように「賢いAIを賢い方法で評価する」試み
- 解釈可能性によってブラックボックスの内部理解を進めようとする試み
- 数理的に安全を保証する試み
ただし重要なのは、研究が毎年進歩していることと、それが“十分な速度で”進むことは別問題だという点です。
もし汎用人工知能(AGI)の到来が近いタイミングで起きるなら、私たちは同時に、以下の2つの競争に置かれます。
- 性能が上がるスピード
- 安全性を固めるスピード
さらにEliezer Yudkowskyのように、制御の見通しが立たないまま能力だけが先行すること自体を最大の危険とみなす論者もいます。
AIの進化だけでなく、AIアライメントにも目を向けることは今後の社会を見通すうえで、極めて重要なファクターになります。
SHIFT AIでは、ChatGPTやGeminiなどの生成AIを活用して、副業で収入を得たり、昇進・転職などに役立つスキルを学んだりするためのセミナーを開催しています。
また、参加者限定で、「今日から使えるプロンプト100選」「新時代のAI×デザイン活用ガイド」「Nano Banana Pro 徹底解説」など、全12個の資料を無料で配布しています。
「これからAIを学び始めたい」「AIを使って副業収入を得たい」「AIで業務を効率化したい」という方は、ぜひ以下のボタンからセミナーに参加してみてください。
スキルゼロから始められる!
無料AIセミナーに参加する











スキルゼロから始められる!
無料AIセミナーに参加する