share



【2025年版】主要画像生成AIモデル・サービス徹底比較 — Stable DiffusionからNanoBananaまで

執筆者

画像・動画生成AIクリエイター/インフルエンサー
吉口智晃
2023年より画像・動画生成AIクリエイターとして活動し、最新技術やトレンドをキャッチし常に最先端の作品を制作。SNS総フォロワーは6万人。
NVIDIA製GPU(RTX 3060/RTX 4070)搭載の2台のゲーミングPCで画像・動画を制作。これまでAIで生成した画像・動画は100万点以上。SHIFT AIでは特別講師を務める。
制作実績:トヨタ自動車・伊藤園など
画像生成AIは、毎月のように新しいモデルやサービスが公開されています。モデルの数が増えた結果、「どれを選べばよいか分からない」と感じる人も少なくありません。
特に、SNS運用・副業・デザイン業務に画像生成AIを活用したい人にとって、モデル選びは成果物のクオリティと作業効率を大きく左右します。
実務の現場では、同じプロンプトでもモデルを変更するだけで、仕上がりの印象や解像感が大きく変化します。
モデル選択を誤ると、時間をかけても納得できない画像しか得られない状況に陥る可能性があります。
本記事では、2025年時点で実務にも活用しやすい主要な画像生成AIを取り上げ、特徴・得意な画像タイプ・活用シーンを整理します。
記事を読み終える頃には、読者自身の目的(実写/イラスト/文字入りデザイン/動画/スマホ中心の運用など)に合ったモデルを自信を持って選べる状態になることを目指します。
筆者はこれまで、仕事と制作活動を通じて膨大な枚数のAI画像を生成してきました。
自動車ブランドや飲料メーカーなどの案件にも携わり、講師としても各モデルの特性を比較しながら活用方法を検証しています。
SHIFT AIでは、ChatGPTやGeminiなどの生成AIを活用した「AI副業の始め方」や「収入を得るまでのロードマップ」を学べる無料セミナーを開催しています。
また、参加者限定で、「今日から使えるプロンプト100選」「新時代のAI×デザイン活用ガイド」「Nano Banana Pro 徹底解説」など、全12個の資料を無料で配布しています。
「これからAIを学び始めたい」「AIを使って副業収入を得たい」という方は、ぜひ以下のボタンからセミナーに参加してみてください。
目次
主要画像生成AIモデル一覧と特徴まとめ

この章では、代表的な画像生成AIモデルをモデルごとに整理します。
各モデルについて、概要・特徴・おすすめポイント・商用利用まわりの補足・筆者コメントを記載しています。
モデルの名称やライセンスは必ず最新の公式情報を確認し、商用利用やメディア掲載の前に利用規約を精査することを推奨します。
利用目的が明確な場合は、『用途別おすすめ』の章から読み進めても問題ありません。
\ リンクから記事内の詳細に移動します /
| モデル名 | 料金 | おすすめポイント |
|---|---|---|
| SDXL(Stable Diffusion XL) | 無料 | ・オープンソースゆえの自由度と拡張性 ・フォトリアルからイラストまで幅広い用途に対応 ・ローカル運用に適しており、長期的なカスタマイズがしやすい |
| FLUX.1 シリーズ(Black Forest Labs) | 無料(非商用) | ・生成後の即時編集機能により、細部の修正がしやすい ・フォトリアルな質感表現に強く、商品画像や実写系ビジュアルに適する ・用途やマシン性能に応じてモデルを選択できるラインナップ |
| Illustrious‑XL(OnomaAI) | 無料 | ・イラスト制作に特化した表現力 ・線のシャープさと密度の高い描き込みに対応 ・アニメ背景やデジタルアートなど、情報量の多い画面構成に適する |
| NoobAI‑XL(NAI‑XL, v‑pred系) | 無料 | ・アニメ調のキャラクターを安定して生成しやすい ・ポーズ指示や構図指定への追従性が高い ・ストーリーボードやキャラクター案出しに活用しやすい |
| Pony Diffusion v6 XL | 無料 | ・幅広いテイストのキャラクター表現に対応 ・タグと自然文のどちらでも扱いやすい ・キャラの形が崩れにくく、量産用途に向く |
| Midjourney | 有料(サブスク) | ・世界観や雰囲気を重視したビジュアル制作に適する ・高速な試作とバリエーション出しが可能 ・日本語プロンプトでも意図が伝わりやすい |
| Qwen‑Image(qwen) | 無料 | ・文字が多いデザインでも視認性を保ちやすい ・レイアウト全体のバランスが崩れにくい ・実務寄りのグラフィック制作に適する |
| Wan 2.2(wan) | 無料 | ・静止画と動画の両方を同一の世界観で構築できる ・映画的なライティングや空気感を表現しやすい ・動画制作を前提としたワークフローと相性が良い |
| NanoBanana(Gemini 2.5 Flash Image) | 無料 | ・スマートフォンだけで画像生成と編集を完結できる ・Google関連ツールとの連携により、日常的なワークフローに組み込みやすい ・会話型インターフェースで細かな修正依頼が行いやすい |
【無料】SDXL(Stable Diffusion XL)

まずは、オープンソース系モデルの代表であるSDX(Stable Diffusion XL)Lです。ローカル環境での運用に適しており、細かな設定変更や拡張がしやすい点が特徴です。

SDXLは、オープンソースの定番モデルとして多くのクリエイターに利用されています。
ローカル環境で動作させやすく、設定や拡張によって質感や描写を細かく調整できます。
風景・ポートレート・イラストなど、多様なジャンルを高解像度で出力できる点が特徴です。
Refinerモデルを併用すると、輪郭や質感の仕上げをさらに高めることが可能です。
おすすめポイント
- オープンソースゆえの自由度と拡張性
- フォトリアルからイラストまで幅広い用途に対応
- ローカル運用に適しており、長期的なカスタマイズがしやすい
補足(利用規約・ライセンス)
- オープンソース版はライセンス条項がバージョンごとに異なる場合があります。
- 商用利用の可否や再配布条件については、必ず公式リポジトリのライセンス文書を確認してください。
筆者コメント
プロンプトへの反応が素直で、狙った方向に調整しやすいモデルです。
土台となる画像の生成では、現在も第一候補として使用しています。
【無料】FLUX.1 シリーズ(Black Forest Labs)※非商用

次に、リアル寄りの質感表現に強いFLUX.1シリーズです。生成後のテキスト編集機能など、実務での微調整に役立つ機能を備えています。
FLUX.1は、フォトリアルな質感と細部の描写を得意とするモデル群です。生成後にテキストで特定の箇所のみを修正できるため、再生成の回数を抑えつつ画づくりを進められます。
用途に応じて、pro(高品質)・dev(バランス型)・schnell(高速)といったバリエーションから選択できます。
風景・ポートレート・アート作品など、情報量の多い画像で特に力を発揮します。
おすすめポイント
- 生成後の即時編集機能により、細部の修正がしやすい
- フォトリアルな質感表現に強く、商品画像や実写系ビジュアルに適する
- 用途やマシン性能に応じてモデルを選択できるラインナップ
補足(利用規約・ライセンス)
- 公開ウェイトは、非商用ライセンスとして提供されているバージョンが中心です。
- 商用利用や収益化を伴うプロジェクトで利用する場合は、公式のライセンスおよびAPIプランを必ず確認してください。
筆者コメント
部分的な修正をテキストから行えるため、写真系の案件で下地を整える際に非常に重宝しています。
【無料】Illustrious‑XL(OnomaAI)

Illustrious-XLは、SDXLを基盤としたイラスト特化モデルです。キャラクターと背景の両方を描き込みたい場面で活用しやすいモデルです。

Illustrious-XLは、線のキレと細部の描写力に優れたモデルです。
キャラクターと背景を一体感のある構図で描きたい場合に、安定した結果を得やすくなっています。
高解像度(ネイティブ1536ピクセル)での出力に対応し、情報量の多いイラストやアニメシーンでも輪郭が崩れにくい点が特徴です。
おすすめポイント
- イラスト制作に特化した表現力
- 線のシャープさと密度の高い描き込みに対応
- アニメ背景やデジタルアートなど、情報量の多い画面構成に適する
補足(利用規約・ライセンス)
- 利用可能範囲や商用利用の可否は、配布元が提示する利用規約を必ず確認してください。
- 幅広いスタイルに対応したい場合は、LoRAなどの拡張と組み合わせる方法もあります。
筆者コメント
キャラクターと背景をしっかり描き込みたい制作で、最初に候補に挙がるモデルです。
【無料】NoobAI‑XL(NAI‑XL, v‑pred系)

NoobAI-XLは、アニメ調や2.5D表現に強みを持つモデルです。
キャラクターメインのコンテンツを制作する場面で活用しやすいにモデルになっています。

NoobAI-XLは、アニメ調や2.5Dテイストのキャラクターを安定して生成しやすいモデルです。
プロンプトに対する反応が分かりやすく、ポーズや構図の指定も反映されやすい点が特徴です。
アニメ風のキャラクターデザイン、ストーリーボード用のカット、イラスト制作など、二次元表現を中心とした用途と相性が良好です。
おすすめポイント
- アニメ調のキャラクターを安定して生成しやすい
- ポーズ指示や構図指定への追従性が高い
- ストーリーボードやキャラクター案出しに活用しやすい
補足(利用規約・ライセンス)
- 公開ウェイトは、個人利用を前提とした条件で提供される場合があります。
- 収益化を伴うプロジェクトでの利用を検討する場合は、必ず公式の利用規約を確認してください。
筆者コメント
アニメ調のキャラクター制作では、まずNoobAIを試すことが多く、狙ったテイストに到達しやすい印象があります。
【無料】Pony Diffusion v6 XL

Pony Diffusion v6 XLは、アニメからセミリアルまで幅広いキャラクター表現に対応したモデルです。

Pony v6 XLは、アニメ寄りの表現から少しリアル寄りの表現まで対応できるモデルです。
タグベースの入力と自然文の両方に対応しており、目的やワークフローに合わせた使い方が可能です。
キャラクター中心のイラスト、カートゥーン調、動きのあるカットなど、キャラクター表現に重点を置いた制作で力を発揮します。
おすすめポイント
- 幅広いテイストのキャラクター表現に対応
- タグと自然文のどちらでも扱いやすい
- キャラの形が崩れにくく、量産用途に向く
補足(利用規約・ライセンス)
- 一般公開されているモデルには、商用利用に制限がある場合があります。
- 収益化を目的とした利用では、必ず配布元のライセンス条件を確認してください。
筆者コメント
キャラクターの雰囲気をそろえながら枚数を出したいときに、頼りになるモデルです。
【有料】Midjourney

Midjourneyは、芸術性の高いビジュアルと世界観構築を得意とするサブスクリプション型サービスです。
Midjourneyは、アート性と世界観の表現力に特化した画像生成サービスです。
Draft Modeを用いると、構図や雰囲気のバリエーションを短時間で確認できます。
フォトリアルな表現に限らず、抽象的なアートワークやコンセプトアートの制作にも適しています。
日本語プロンプトにも対応しており、英語に不慣れな利用者でも操作しやすい点も特徴です。
おすすめポイント
- 世界観や雰囲気を重視したビジュアル制作に適する
- 高速な試作とバリエーション出しが可能
- 日本語プロンプトでも意図が伝わりやすい
補足(利用規約・ライセンス)
- 利用は有料サブスクリプションが前提です。
- 商用利用の範囲やクレジット表記の要否など、最新の利用規約を必ず確認してください。
筆者コメント
世界観の方向性を決める段階で重宝しているサービスです。雰囲気の強いビジュアルを短時間で複数案確認したい場面に向いています。
【無料】Qwen‑Image(qwen)

Qwen-Imageは、文字を含む画像生成に強みを持つモデルです。

Qwen-Imageは、文字情報を含むポスターやバナーの生成を得意とするモデルです。
文字の可読性が高く、複雑なレイアウト構成でも崩れにくい点が特徴です。
SNS告知画像やキャンペーンバナーなど、実務でのグラフィックデザインに近い用途と相性が良好です。
おすすめポイント
- 文字が多いデザインでも視認性を保ちやすい
- レイアウト全体のバランスが崩れにくい
- 実務寄りのグラフィック制作に適する
補足(利用規約・ライセンス)
- 無料枠が設定されている場合がありますが、上限枚数や商用利用範囲は必ず公式情報を確認してください。
- 日本語の長文を扱う場合は、文量や指示内容を工夫すると安定しやすくなります。
筆者コメント
文字を含むデザインでは、Qwen-Imageを選ぶと出力の安定感が高く、業務でも活用しやすいと感じています。
【無料】Wan 2.2(wan)

Wan 2.2は、静止画と動画の両方を扱えるモデルです。映像寄りの表現を行いたい場合に選択肢となります。

Wan 2.2は、フォトリアルな人物表現や映画的な雰囲気のシーンを得意とするモデルです。
静止画から動画への展開にも対応しており、モーション表現を含む制作フローを構築しやすくなっています。
映像作品のコンセプト作成や、シネマティックなキービジュアルの生成などに活用しやすいモデルです。
おすすめポイント
- 静止画と動画の両方を同一の世界観で構築できる
- 映画的なライティングや空気感を表現しやすい
- 動画制作を前提としたワークフローと相性が良い
補足(利用規約・ライセンス)
- 高品質な生成には高性能なマシンが必要となる場合があります。
- 商用利用や配信プラットフォームでの利用については、必ず公式ドキュメントを確認してください。
筆者コメント
一枚の静止画から映像的な空気感を出したい場面で、Wan 2.2を利用することが多くあります。
【無料】NanoBanana(Gemini 2.5 Flash Image)

NanoBananaは、スマートフォンから利用しやすい構成のモデルです。
モバイル環境中心のワークフローを想定している利用者に適しています。

NanoBananaは、Geminiアプリなどと連携して利用できる画像生成機能です。
スマートフォンから画像の編集や合成を行えるため、PC環境がない場合でも一定のクオリティを確保できます。
複数の画像を一貫したスタイルに整えたい場面や、外出先でのラフ案作成に適したモデルです。
おすすめポイント
- スマートフォンだけで画像生成と編集を完結できる
- Google関連ツールとの連携により、日常的なワークフローに組み込みやすい
- 会話型インターフェースで細かな修正依頼が行いやすい
補足(利用規約・ライセンス)
- 公開モデルは個人利用を前提とした条件が設定されている場合があります。
- 商用利用やメディア掲載前には、アプリおよびモデルの利用規約を必ず確認してください。
筆者コメント
外出先での作成や簡易的な合成では、NanoBananaを使うことで作業を端末一台に集約できています。
スキルゼロから始められる!
無料AIセミナーに参加する用途別おすすめ
ここまで紹介したモデルを、用途別の視点から整理します。

以下、各詳細を含めた一覧です。
| 用途やシーン | おすすめモデル | 説明 |
|---|---|---|
| 文字入りポスター/バナー | Qwen-Image | 文字の可読性とレイアウトの安定性に優れており、広告用画像や告知バナーの制作に適しています。 |
| 実写/商品/質感重視 | ・FLUX.1 ・Midjourney | ・FLUX.1は質感表現と細部描写に強みがあり、商品画像や実写寄りのビジュアルを制作しやすいモデルです。 ・Midjourneyは世界観づくりに強く、ブランドイメージを重視したビジュアル制作と相性が良好です。 |
| アニメ/キャラクター | ・Pony ・Illustrious ・NoobAI | それぞれキャラクター表現に強みを持ちます。 安定したキャラクター量産や、アニメシーンの作成を行う場合に候補となります。 |
| 動画/モーショングラフィックス | Wan 2.2 | 静止画と動画を一貫した質感で生成しやすく、映像プロジェクトのコンセプトづくりに向いています。 |
| スマートフォン中心で使いたい場合 | NanoBanana | スマートフォンのみでの合成・編集を前提にしているため、モバイル中心の制作スタイルに適します。 |
| 予算を抑えて始めたい場合 | ・SDXL ・Illustrious ・Qwen-Imageの無料枠 | SDXLやIllustriousをローカルで運用し、Qwen-Imageの無料枠を組み合わせることで、コストを抑えつつ高品質な出力を得られます。 |
| 日本語プロンプト中心で使いたい場合 | ・Midjourney ・NanoBanana | 日本語プロンプトに対応しており、日本語のみでワークフローを完結させたい利用者に適しています。 |
筆者の制作フロー
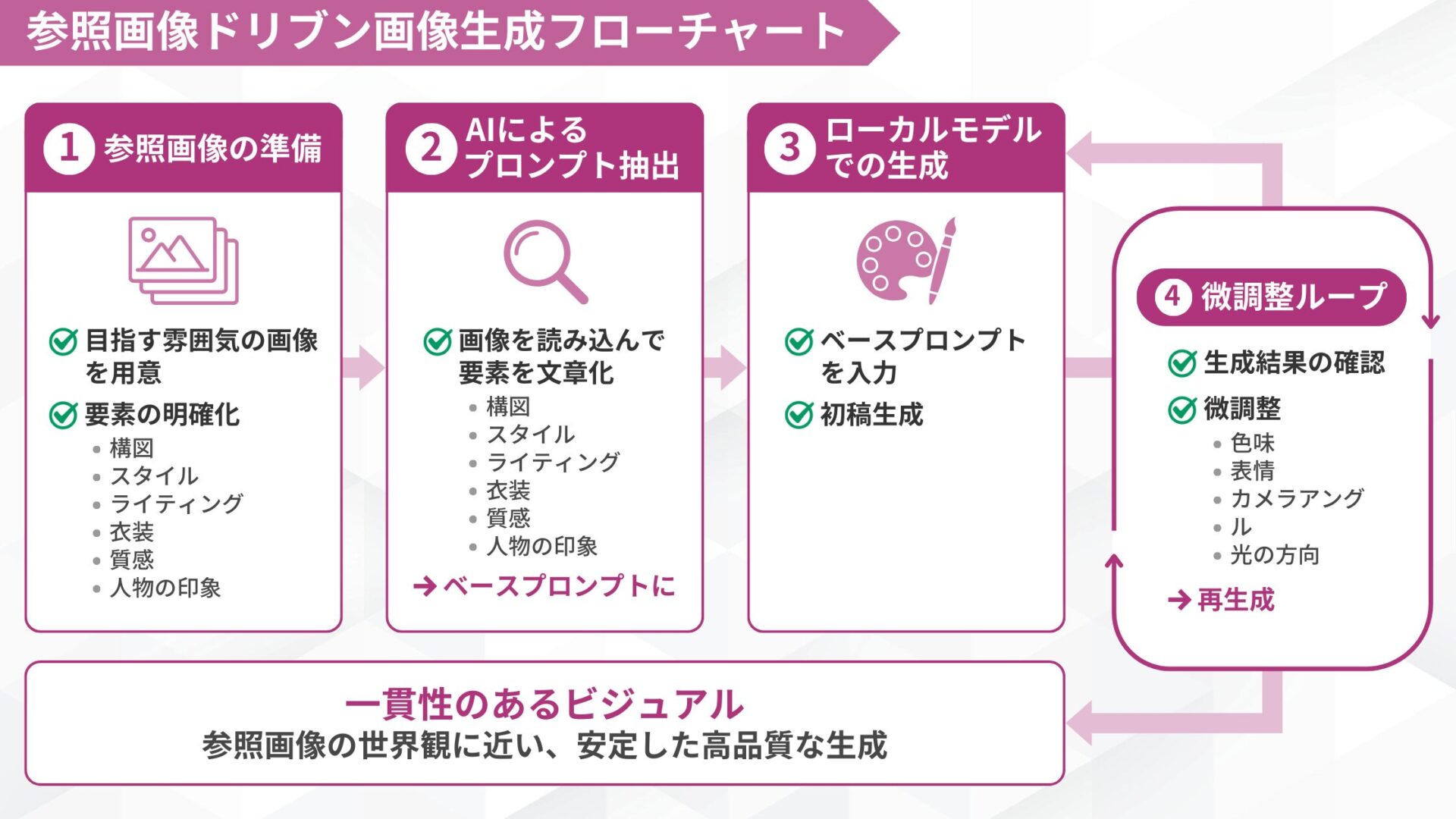
ここからは、筆者が日常的に採用している制作フローを紹介します。モデルごとの特性を踏まえたうえで、再現性を高めるための手順を整理しています。
- 目指したい雰囲気に近い画像を一枚から数枚用意
- 参照画像をもとにプロンプトの要素を抽出
- 抽出したプロンプトをローカルモデルに入力して生成結果を確認
まず、目指したい雰囲気に近い画像を一枚から数枚用意し、以下のような基準としたい要素を明確にしておきます。
- 構図
- スタイル
- ライティング
- 衣装
- 質感
- 人物の印象
次に、参照画像をChatGPTやGrokの機能に読み込ませ、プロンプトに入れ込む要素を文章として抽出します。この工程で得られたテキストが、ベースプロンプトとして機能します。
最後に、抽出したプロンプトを、用途に応じて「SDXL」「Illustrious」「Pony」「NoobAI」などのローカルモデルに入力し、生成結果を確認します。
その後、以下要素を少しずつ調整します。
- 色味
- 表情
- カメラアングル
- 光の方向
この「参照画像 → プロンプト抽出 → ローカル生成 → 微調整」というループを繰り返します。
このフローにより、参照画像の世界観に近い一貫性のあるビジュアルを安定して作成できます。
まとめ 用途別に最適な画像生成AIを使おう!
2025年時点の画像生成AIは、モデルごとに明確な得意分野を持っています。
| 用途やシーン | おすすめモデル | 説明 |
|---|---|---|
| 文字入りポスター/バナー | Qwen-Image | 文字の可読性とレイアウトの安定性に優れており、広告用画像や告知バナーの制作に適しています。 |
| 実写/商品/質感重視 | ・FLUX.1 ・Midjourney | ・FLUX.1は質感表現と細部描写に強みがあり、商品画像や実写寄りのビジュアルを制作しやすいモデルです。 ・Midjourneyは世界観づくりに強く、ブランドイメージを重視したビジュアル制作と相性が良好です。 |
| アニメ/キャラクター | ・Pony ・Illustrious ・NoobAI | それぞれキャラクター表現に強みを持ちます。 安定したキャラクター量産や、アニメシーンの作成を行う場合に候補となります。 |
| 動画/モーショングラフィックス | Wan 2.2 | 静止画と動画を一貫した質感で生成しやすく、映像プロジェクトのコンセプトづくりに向いています。 |
| スマートフォン中心で使いたい場合 | NanoBanana | スマートフォンのみでの合成・編集を前提にしているため、モバイル中心の制作スタイルに適します。 |
| 予算を抑えて始めたい場合 | ・SDXL ・Illustrious ・Qwen-Imageの無料枠 | SDXLやIllustriousをローカルで運用し、Qwen-Imageの無料枠を組み合わせることで、コストを抑えつつ高品質な出力を得られます。 |
| 日本語プロンプト中心で使いたい場合 | ・Midjourney ・NanoBanana | 日本語プロンプトに対応しており、日本語のみでワークフローを完結させたい利用者に適しています。 |
自分が作りたいコンテンツの用途と、求めるクオリティ・ワークフローを整理したうえで、本記事のモデル一覧と用途別の整理を参照しながら最適なツールを選択していただければ、画像生成AIをより戦略的に活用できるはずです。
SHIFT AIでは、ChatGPTやGeminiなどの生成AIを活用して、副業で収入を得たり、昇進・転職などに役立つスキルを学んだりするためのセミナーを開催しています。
また、参加者限定で、「初心者が使うべきAIツール20選」や「AI副業案件集」「ChatGPTの教科書」など全12個の資料を無料で配布しています。
「これからAIを学び始めたい」「AIを使って副業収入を得たい」「AIで業務を効率化したい」という方は、ぜひ以下のボタンからセミナーに参加してみてください。
スキルゼロから始められる!
無料AIセミナーに参加する











スキルゼロから始められる!
無料AIセミナーに参加する