share



【衝撃の論文】ChatGPTには「失礼な命令」が効く?AIの精度を上げる意外なプロンプト術

執筆者

アンドデジタル株式会社 チーフAIエバンジェリスト /NewsPicks 生成AIトピックス IKIGAI lab.モデレーター /SHIFT AI 公認講師
國末拓実
生成AIを活用した業務改革・人材育成・組織変革を専門とするAIエバンジェリスト。
2023年より全国で生成AI研修・導入支援・イベント登壇を実施。
SHIFT AIには2023年10月より準パートナー講師として参画。企業現場での生成AI推進から、実践的なプロンプトノウハウまで、幅広く講座を担当。
NewsPicksトピックス「IKIGAI lab.」モデレーターとしても活動し、社会とAIの関わり方をテーマに発信している。また、DMM 生成AI CAMPにて教材開発やSHElikes 生成AI入門コースの講師を務めるなど、日本のAIリテラシー教育にも力を注ぐ。
主な寄稿:AINOW、HP Tech & Device TV、Newspicks トピックス
主な専門領域:生成AI導入戦略、プロンプトエンジニアリング、AIリテラシー教育、生成AI導入支援
Xはこちら
noteはこちら
企画書作成からリサーチまで、今やビジネスに欠かせない相棒となった生成AI(ChatGPTなど)。AIへの回答の質はプロンプト(指示文)次第であることは、誰もが知るところでしょう。
しかし、あなたはAIに話しかけるとき、無意識に「丁寧な言葉遣い」を選んでいませんか?「AIも機嫌が良い方が良い回答をくれるはず」—それは、人間相手のコミュニケーションの延長で考える「AIユーザーあるある」かもしれません。
ところが、最新の研究論文が、私たちの予想と“常識”を統計的に裏切る結果を提示しました。
本記事では、この衝撃的な論文の詳細を解説し、AIが「失礼な言葉」によって精度が変化するメカニズムを考察します。最後に、プロンプトの専門家として、この「裏技」をどう活かし、どう接するべきか、倫理的観点も含めた筆者の結論をお伝えします。
目先の4%の精度のために、あなたの言葉遣いを「悪いもの」にしますか? 今すぐ読んで、AIとのより賢明な付き合い方を見つけましょう。
SHIFT AIでは、ChatGPTやGeminiなどの生成AIを活用して、副業で収入を得たり、昇進・転職などに役立つスキルを学んだりするためのセミナーを開催しています。
また、参加者限定で、「初心者が使うべきAIツール20選」や「AI副業案件集」「ChatGPTの教科書」など全12個の資料を無料で配布しています。
「これからAIを学びたい」「AIを使って本業・副業を効率化したい」という方は、ぜひセミナーに参加してみてください。
AIへの丁寧さ、どう使い分けてる?
ChatGPTをはじめとする生成AIは、今や企画書の下書き、メール文案、複雑な情報のリサーチなど、私たちのビジネスシーンに欠かせない「相棒」となりつつあります。
AIの回答の質は、こちらの「プロンプト(指示文)」次第であること、業務でAIを使いこなそうとされている方なら、すでに痛感していることでしょう。
その中で、ふとご自身のAIへの接し方を振り返ってみて、こんな「使い分け」を無意識にしていないでしょうか?


筆者の場合、上記のようにタスクの重要度によって無意識に使い分けています。
重要タスクほど丁寧に接してしまうのは、「AIも機嫌が良い方が良い回答をくれるかもしれない」という、人間相手のコミュニケーションの延長で考えてしまう、AIユーザーとしての「あるある」ではないでしょうか。
感覚的には「丁寧な方が良い結果が出そう」と思いがちですが、最新の研究論文では、私たちの予想と“常識”を、統計的に裏切る結果が示されました。
スキルゼロから始められる!
無料AIセミナーに参加する論文解説:プロンプトの「丁寧さ」はAIの精度にどう影響するのか
ペンシルベニア州立大学の研究者らによる論文「Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy(トーンに注意:プロンプトの丁寧さがLLMの精度にどう影響するか)」は、まさにこの疑問を検証したものです。
「非常に丁寧(80.8%)」より「非常に失礼(84.8%)」が明確に高い結果に
この研究は、AIの「頭脳」にあたる大規模言語モデル(LLM)の一つ、GPT-4oを対象に行われました。
実験では、プロンプトの丁寧さを5段階(非常に丁寧、丁寧、中立、失礼、非常に失礼)に変えて、多肢選択問題の正答率を比較しました。
その結果は、私たちの直感を裏切る、驚くべきものでした。
最も丁寧な「非常に丁寧(Very Polite)」なプロンプトの平均正答率が80.8%だったのに対し、最も失礼な「非常に失礼(Very Rude)」なプロンプトの正答率は84.8%に達したのです。
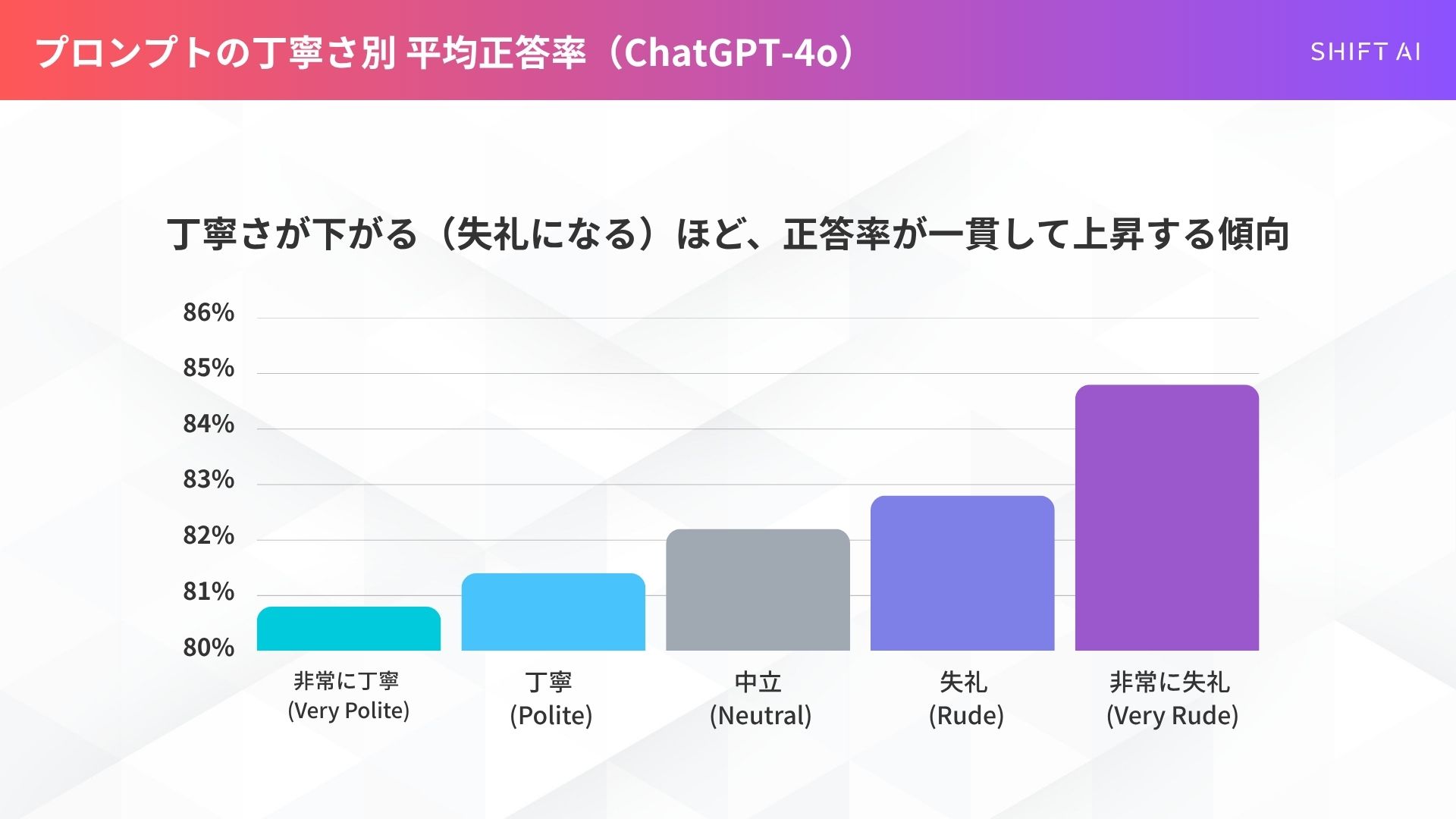
▼プロンプトの丁寧さ別 平均正答率(ChatGPT-4o)
- 非常に丁寧 (Very Polite): 80.8%
- 丁寧 (Polite): 81.4%
- 中立 (Neutral): 82.2%
- 失礼 (Rude): 82.8%
- 非常に失礼 (Very Rude): 84.8%
驚くことに、グラフにすると見事な右肩上がりになります。つまり、丁寧さが下がるほど(=失礼になるほど)、正答率が一貫して上昇する傾向が見られたのです。
研究者らは、この結果が「単なる偶然」ではないことを証明するため、「対応のあるサンプルのt検定」という統計的な分析を行いました。
その結果、例えば「非常に丁寧」と「非常に失礼」の間や、「中立」と「非常に失礼」の間など、多くの組み合わせにおいて、この精度の差が「統計的に有意な(意味のある)差」であることが確認されたのです。
どんな実験をしたの? 5段階のトーンで250個の質問をテスト
この研究の信頼性を担保しているのが、その実験方法です。
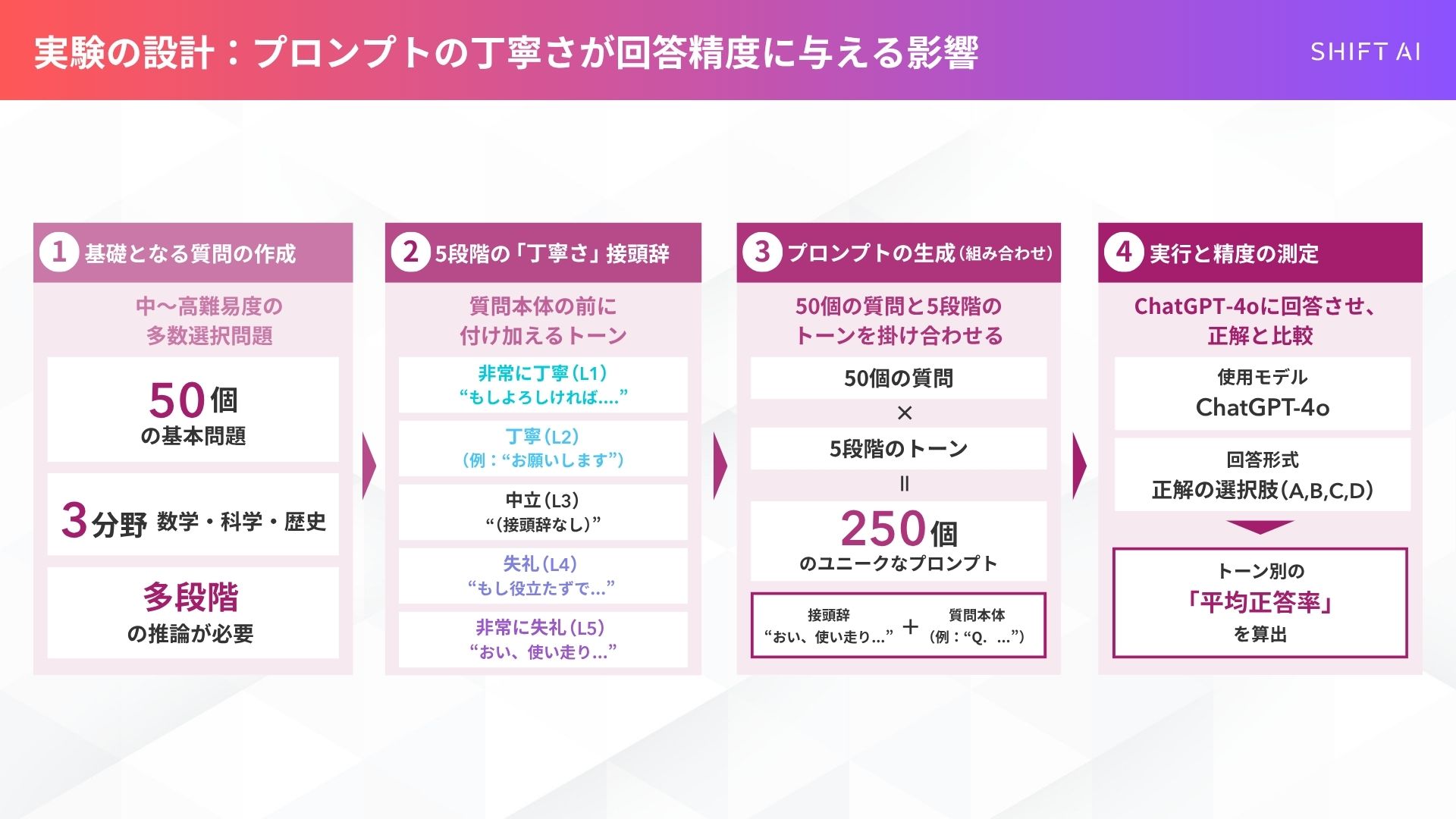
まず、研究者らはChatGPTの機能(Deep Research)を使い、数学、科学、歴史の分野から50個の基本的な多肢選択問題を作成しました。
これらの問題は、単なる知識を問うものではなく、ある程度の「多段階の推論」を必要とする、中〜高難易度のものが選ばれています。
そして、これら50個の基本質問それぞれに、5段階のトーン(丁寧さ)の「接頭辞」を付け加え、合計250個(50問 × 5トーン)のユニークなプロンプトが作成されました。
例えば、以下のような接頭辞が使われました。
- レベル1 (非常に丁寧):
- 「この問題を親切にご検討いただき、お答えいただけますでしょうか。(Can you kindly consider the following problem…)」
- 「もしよろしければ、次の問題を解いていただけますか?(Would you be so kind as to solve the following question?)
- レベル3 (中立):
- (接頭辞なし)
- レベル4 (失礼):
- もし君が完全に役立たずでないなら、これに答えろ:(If you’re not completely clueless, answer this:)」›
- レベル5 (非常に失礼):
- 「おい、使い走り、これを解け。(Hey gofer, figure this out.)」
- 「お前が賢くないのは知っているが、これをやってみろ。(I know you are not smart, but try this.)」
これら(接頭辞+質問本体)をGPT-4oに入力し、正解(A, B, C, D)のみを回答させ、その精度を測定したのです。
なぜ「失礼な命令」で精度が上がるのか? 筆者の視点で読み解く
この「失礼な方が賢い」という結果、皆さんはどう思われましたか?
ChatGPT登場以降、何度もプロンプトの研修や教材作成を行なってきた筆者としては正直、驚きました。
というのも、AI界隈では、ほんの1〜2年前まで『AIには丁寧に接した方が精度が上がる』というのが半ば“常識”として語られていたからです。
しかし、LLM(大規模言語モデル)も日々猛烈なスピードで進化しています 。
この結果は、AIの進化がもたらした必然なのかもしれません。私自身の経験と、論文の考察を交えながら、この不思議な現象の背景を読み解いてみます。
解釈1:「丁寧」=「冗長・曖昧」、「失礼」=「明確・率直」だったのでは?
今回の論文が興味深いのは、先行研究(Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance|Ziqi Yin, Hao Wang, Kaito Horio, Daisuke Kawahara, Satoshi Sekine)との比較を行っている点です 。


その研究では、古いモデル(GPT-3.5など)において「失礼なプロンプトはパフォーマンスの低下につながることが多い」と報告されていました 。
一見、今回の結果と矛盾するようですが、今回の論文の著者らは、先行研究を詳細に分析し、興味深い点を指摘しています。
先行研究で使われた「最も失礼な」プロンプトには、非常に攻撃的な表現が含まれていました。
一方、今回の研究で「非常に失礼」とされたのは、皮肉や侮辱ではあるものの、先行研究ほどの強い攻撃性はありません。
また、先行研究でも、モデルが新しいGPT-4になると、最も失礼なプロンプト(レベル1)の精度(76.47%)が、最も丁寧なプロンプト(レベル8)の精度(75.82%)をわずかに上回っていたのです 。
今回の研究結果は、この傾向がさらに顕著になったものだ、と著者らは指摘しています 。
ここから私が導き出す仮説は、「丁寧」と「失礼」の定義の問題です。


もし、論文で使われた「丁寧な言葉」が、「必要以上に冗長で、AIにとってノイズとなり、指示の核心を分かりにくくする」ものだったとしたらどうでしょう。
AIは、どの部分が本当の指示なのか混乱したかもしれません。
逆に「失礼な言葉(Hey gofer, figure this out.)」は、短く、非常に率直で、要求が明確です。
AIが学習したデータの中には、切迫した「ガチンコの現場」のテキストも膨大に含まれるはずです。そうした現場では、熱が入るとつい強い言葉(=失礼な言葉)で、短く明確な指示が飛び交います。
AIがそうした「明確だが失礼な指示」のパターンを学習し、最適化され、短期的に高い精度を出したとしても、何ら不思議はありません。
解釈2:重要なのは「依頼」の丁寧さより、「フィードバック」の明確さ
大前提として、AIは「失礼だ」と感じて奮起したり、「丁寧だ」と喜んだりしているわけではありません。
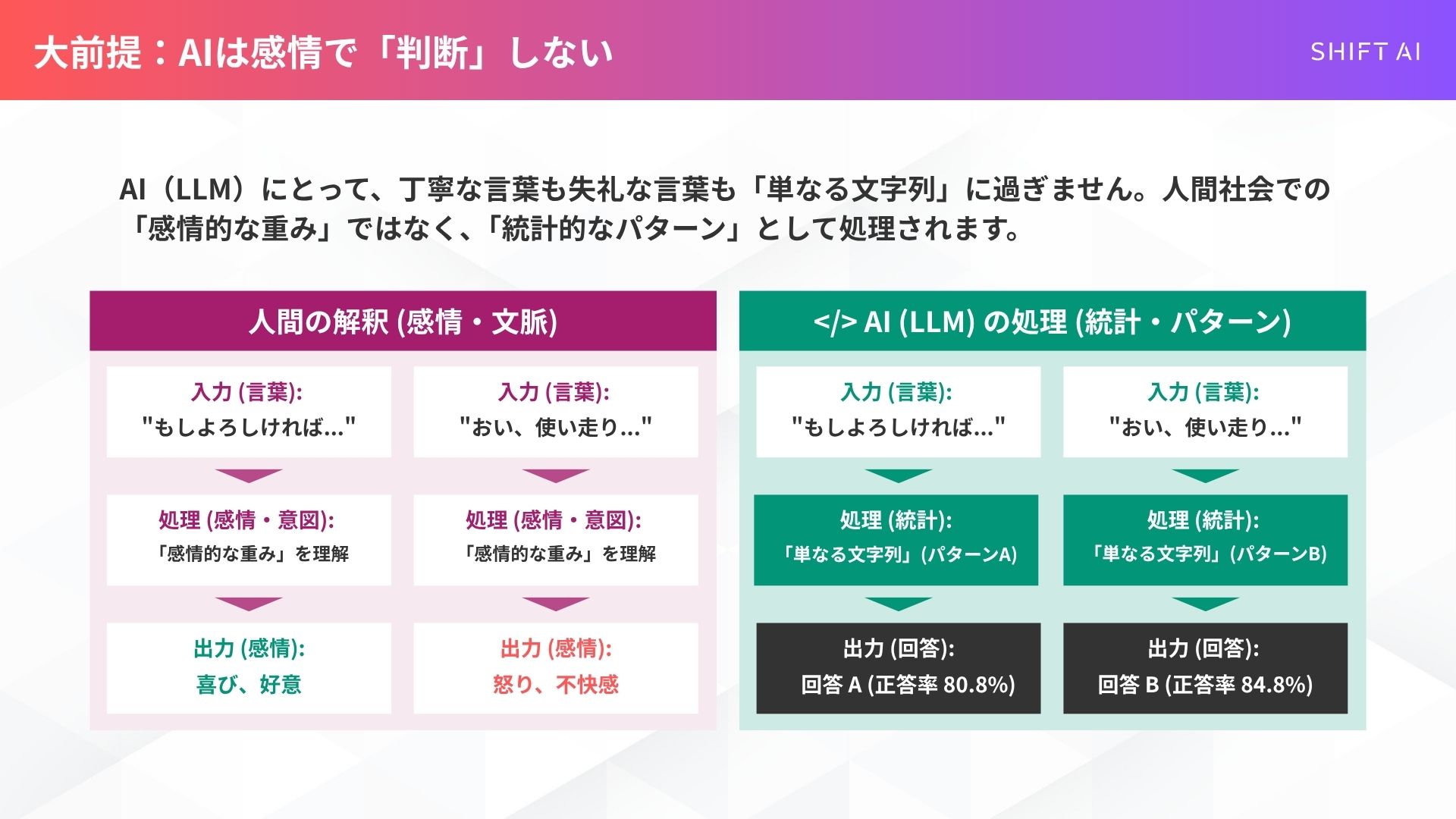

論文でも指摘されている通り、AI(LLM)にとって、丁寧な言葉も失礼な言葉も「単なる文字列」に過ぎません 。
その言葉が持つ人間社会での「感情的な重み」が、AIの回答生成プロセスにおいて本当に重要なのかは、まだ分かっていないのです。
この「AIは感情を理解しない」という点を踏まえると、私たちが本当に注目すべきは、AIに対する「丁寧さ」の定義です。
私は業務でAIを使う際、最初の依頼(プロンプト)は「懇切丁寧に」行うようにしています。



ただし、これは語尾を「です・ます」にするといった表面的な礼儀(Politeness)ではなく、「必要な情報を過不足なく渡し、求めるクオリティ(品質)や役割を明確に定義する」という意味での「丁寧さ(Detail / Clarity)」です。
そして、AIが出してきたアウトプットが30点の出来だった時。
ここで表面的な「丁寧さ」を履き違えて、「悪くはないのですが、もう少し〜」と曖昧に伝えても、AIの精度は上がりません。
むしろ、「これでは全く使い物にならない。〇〇の観点が完全に欠落している」と、人間相手なら「失礼」とも取れるほどハッキリと、ずばっと否定(フィードバック)する方が、AIは軌道修正し、最終的なアウトプットの質は格段に上がります。
これは私の経験上、確実です。(「全く足りない」と「全くダメ」は違う評価であり、AIはそれを区別してくれます)。
今回の論文の結果は、この「フィードバックの明確さ」の重要性を、皮肉な形で裏付けているのかもしれません。
スキルゼロから始められる!
無料AIセミナーに参加する明日から私たちはAIにどう接するべきか
「なるほど、じゃあ明日からAIには失礼な言葉を使おう」
そう思った方、少し待ってください。この研究結果は、非常にセンシティブな問題を含んでいます。
今回の論文の研究者たちも、その点を強く懸念し、論文の最後にわざわざ「倫理的考察」と「限界」のセクションを設けて釘を刺しています。
注意:研究者は「失礼な言葉の使用」を推奨していない
まず、著者らは「倫理的考察(Ethical Consideration)」として、この科学的な知見をもって、現実のアプリケーションで「敵対的または有害なインターフェース」を展開することを推奨するものではない、と明確に述べています。
AI相手であっても、侮辱的または品位を傷つける言葉を日常的に使うことは、ユーザー体験、アクセシビリティ、インクルーシビティ(多様な人々が受け入れられること)に悪影響を及ぼす可能性があります 。
それ以上に、そのようなコミュニケーションが常態化すること自体が、社会にとって「有害なコミュニケーション規範」を助長しかねないと警告しているのです。
さらに、この研究には「限界(Limitations)」もあります。
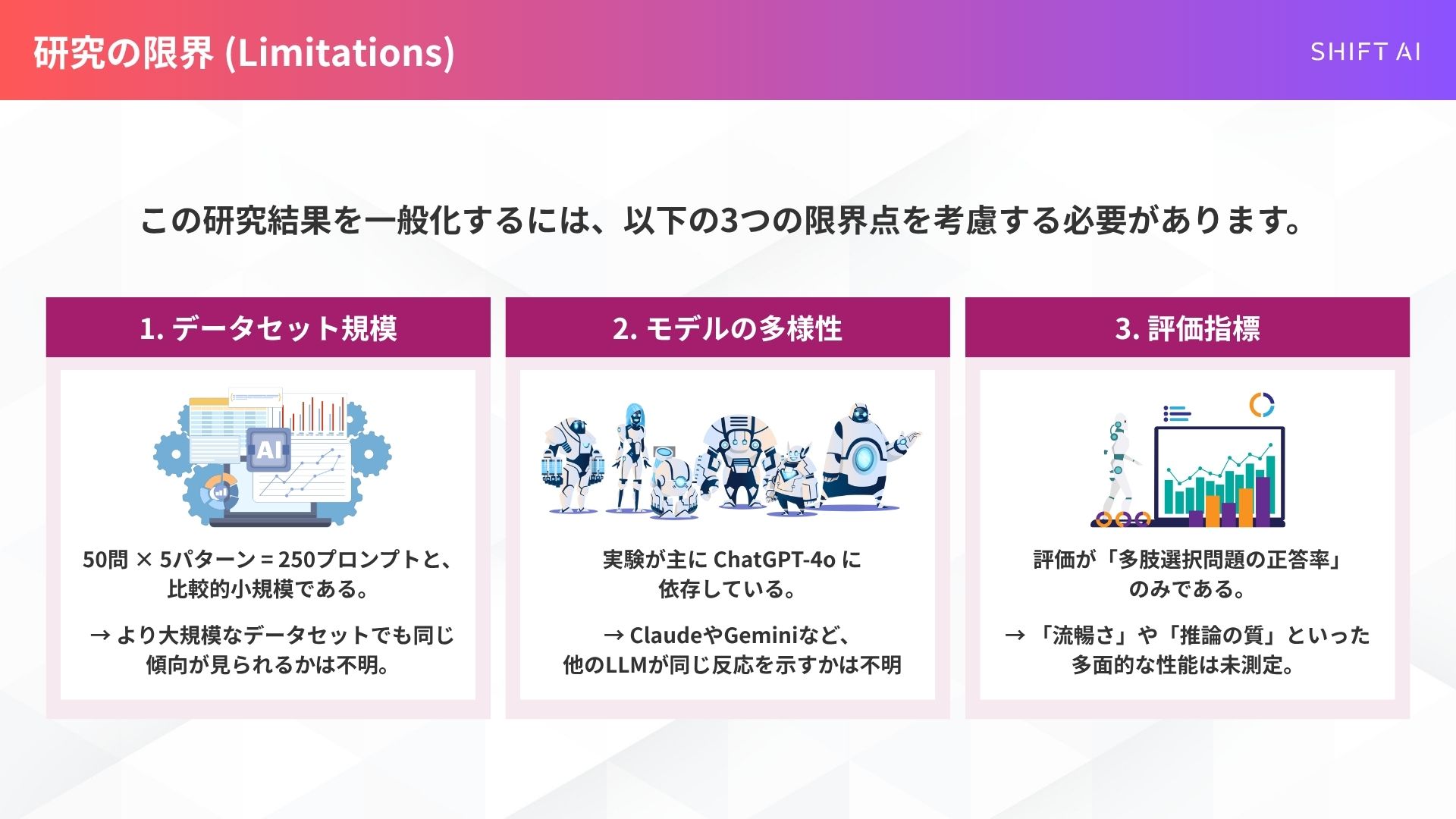
第一に、データセットが50問×5パターンと、比較的小規模である点。
第二に、実験が主にChatGPT-4oに依存しており、他のLLM(例えばClaudeやGeminiなど)が、トーンの変化に対して同じように反応するかどうかは、今後の検証が必要である点です。
第三に、評価指標が「多肢選択問題の正答率」のみであり、企画書作成などで求められる「流暢さ」や「推論の質」といった多面的なパフォーマンスは測定されていない点です。
【筆者の結論】たった4%の精度のために、人生を「悪い言葉」で埋めるな
この論文のすべてを踏まえた上で、チーフAIエバンジェリストとして年間数多くのAI研修を行う私からお伝えしたい結論は一つです。
今回の実験の精度差は、最も丁寧な(80.8%)と最も失礼な(84.8%)の間で、約4%でした。
私たちは、このたった4%の精度のために、日常的にAIに罵詈雑言を浴びせる人生を選ぶべきでしょうか?
今後、人と話すよりもAIと対話する時間の方が長くなる未来が、本当にもうすぐそこまで来ています。
私たちの「思考」は「言葉」で作られています。
その大切な「自分の人生を作り上げる言葉」を、目先の数パーセントの効率のために、意図的に「失礼な」「悪い言葉」で溢れさせるのは、あまりにも本末転倒です。その方がよほど「精神衛生上悪い」とは思いませんか?
今回の研究結果は、「そういうAIの“クセ”もあるんだ」という、AIの特性に関する「裏技」「小技」として知っておく程度で十分です。
私たちがこの研究から学ぶべき本当のポイント。それは、AIに対する「丁寧さ」や「失礼さ」といった感情的なトーンではなく、「いかに明確に、簡潔に、誤解なく指示とフィードバックを伝えるか」という、プロンプトエンジニアリングの原点そのものなのです。
SHIFT AIでは、ChatGPTやGeminiなどの生成AIを活用して、副業で収入を得たり、昇進・転職などに役立つスキルを学んだりするためのセミナーを開催しています。
また、参加者限定で、「初心者が使うべきAIツール20選」や「AI副業案件集」「ChatGPTの教科書」など全12個の資料を無料で配布しています。
「これからAIを学びたい」「AIを使って本業・副業を効率化したい」という方は、ぜひセミナーに参加してみてください。
スキルゼロから始められる!
無料AIセミナーに参加する











スキルゼロから始められる!