share



Midjourneyで同じキャラ・人物を生成する方法は?キャラクターリファレンスについて解説

「Midjourneyで生成したのと同じキャラクターでバリエーションを作りたい!でもどうやってやるの?」と疑問を持っていませんか。
Midjourneyを含む生成AIでは、同じプロンプトで再生成しても、まったく同じに生成されるわけではありません。
しかしMidjourneyでは、「キャラクターリファレンス機能」を使えば、変化の加わったほとんど同じキャラクターを生成できます。
本記事では、キャラクターリファレンス機能の使い方や参照する度合いの操作について、実際の出力結果もあわせて紹介します。
ぜひ参考にして、Midjourneyを使いこなしてください。

監修者
SHIFT AI代表 木内翔大
Midjourneyを使いこなせると、画像生成の幅がぐっと広がります。同じように、もうひとつの画像生成AI「Nano Banana」も気になっている方は多いのではないでしょうか。
「Nano Bananaは難しそうだけど使ってみたい」「Nano Bananaで思い通りの画像を作りたい」という方に向けて、この記事では「Nano Banana Pro大全」を用意しています。
この資料では、Nano Banana Proの基本的な使い方や、本記事では触れられていないプロンプトのコツなどを徹底解説しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってNano Bananaをマスターしてみましょう!
Midjourneyで同じキャラを生成する方法
Midjourneyで同じキャラを生成する方法を、以下3つの環境や方法に分けて解説します。
- Web版
- Discord版
- 共通の機能「Vary」
「Web版」「Discord版」に関して、筆者個人的には、Web版のほうが手軽に操作できるのでおすすめです。
Web版
Web版Midjourneyで同じキャラを生成する手順は以下のとおりです。
- 元になる画像を生成
- 新しく生成したい画像のプロンプトを入力
- プロンプト入力欄に元画像をドラッグ&ドロップ
- 人型のアイコンを選択
- 必要に応じて重み(「––cw」)を入力※のちほど解説します
- 送信
まずは、基準となる画像を生成します。出力された4つから1つ選びましょう(手順1)。
元になる画像は、これから変化させていくので、できるだけ単純なプロンプトで生成するのがおすすめです。
次に、新しく生成したい画像のプロンプトを入力します(手順2)。
元になる画像を部分的に変化させていくので、元画像を生成したプロンプトをコピーして入力し、変化させたい一部を書き換えるようにしましょう。
プロンプトを入力したら、元画像を参照できるように、プロンプト入力欄に元画像をドラッグ&ドロップします(手順3)。
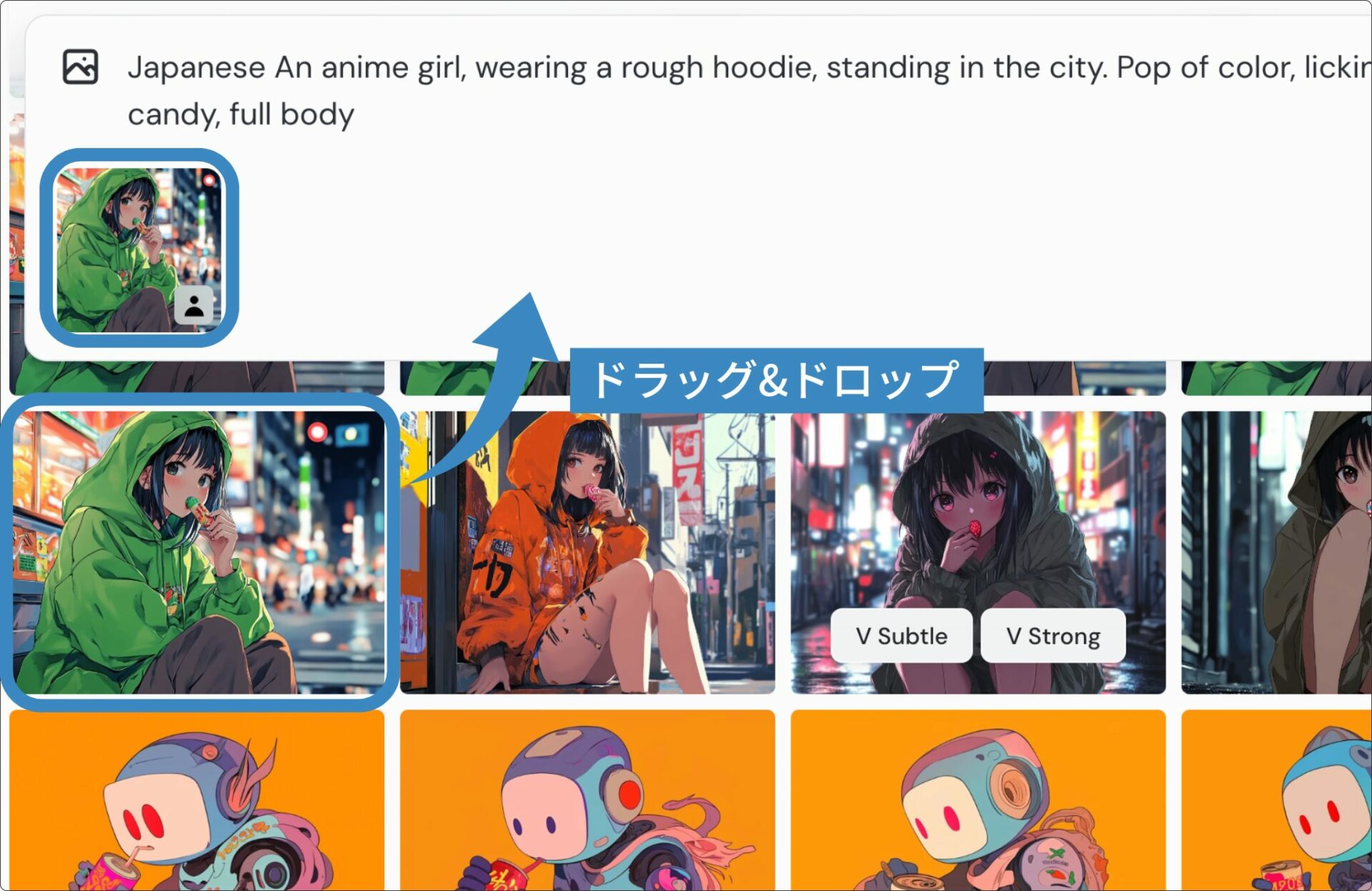
Midjourneyで生成していない画像を参照したい場合は、プロンプト入力欄左上の「画像のアイコン」をクリックし、使いたい画像ファイルをアップロードしてください。
元画像を入れられたら、どのように画像を参照するか指示します(手順4)。指示はプロンプト入力欄に入れた画像の下部にあるアイコンを切り替えれば可能です。
今回はキャラクターを参照してほしいので「人型のアイコン」を選択します(以下画像参照)。
この「人型のアイコン」がキャラクターリファレンスの操作を行う印です。

プロンプトの入力・編集と画像のアップが完了したら、この時点でキャラクターを参照した生成が可能です。
必要に応じて画像を参照する度合い(重み:––cw)※を入力すると、出力内容をより詳細に指示できます(手順5)。
※のちほど解説します
Discord版
Discord版Midjourneyで同じキャラを生成する手順は以下のとおりです。
- 元になる画像の案(グリッド)を生成
- 使いたい画像をグリッドから切り離す
- 画像を選択して「画像のアドレスをコピー」
- 新しく生成したい画像のプロンプトを入力
- プロンプトのうしろに「––cref [URL]」を入力
- 必要に応じて重み(「––cw」)を入力※のちほど解説します
- 送信
まずは元になる画像を生成します(手順1)。Discord版の場合、画像の案が4枚1組(グリッド)で生成されるので、使用する画像を切り離さなければなりません。
切り離しは、グリッドの下部にある「U1〜U4」を選べばOKです(手順2)。

- U1:左上
- U2:右上
- U3:左下
- U4:右下
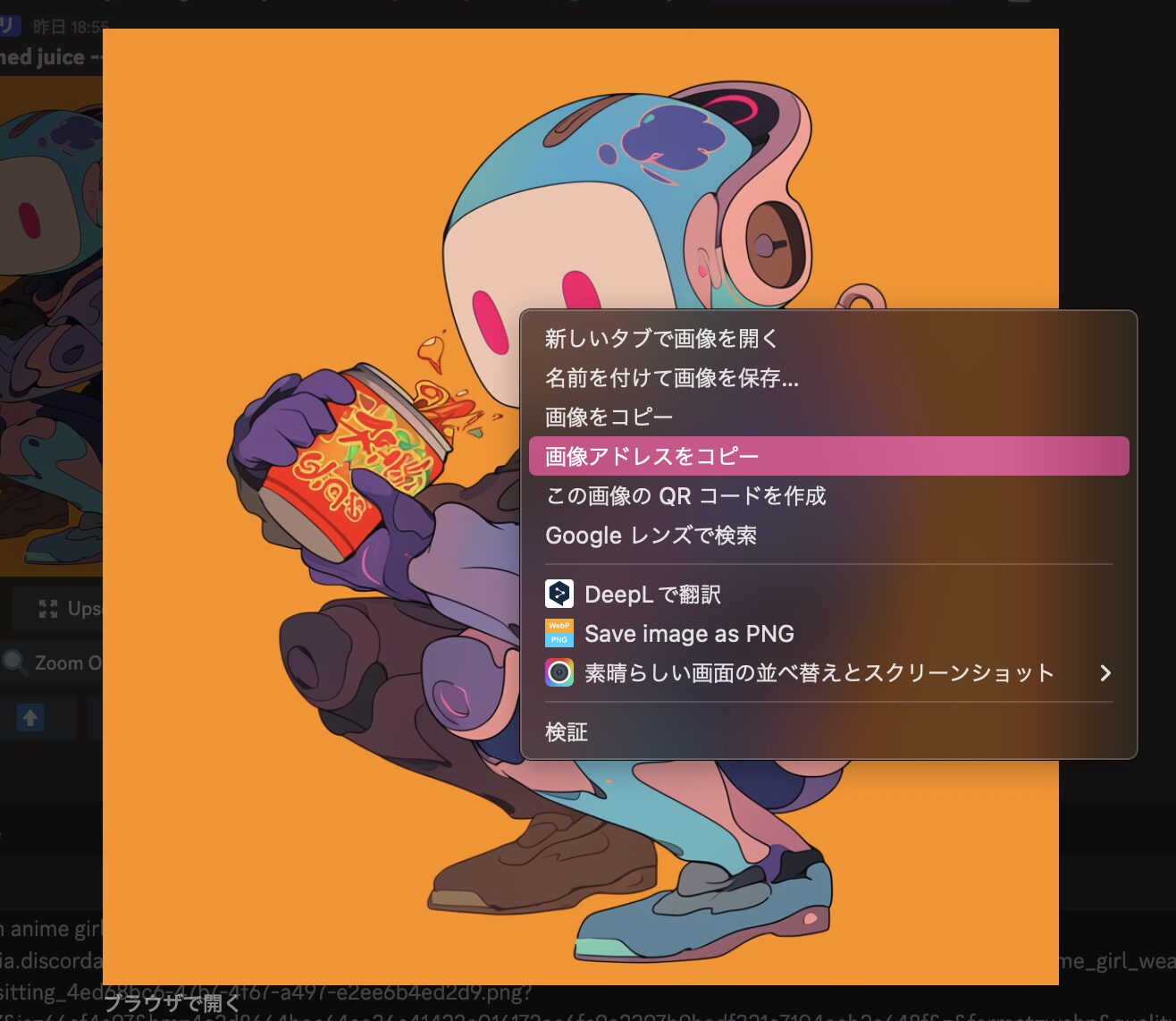
次に、元になる画像のアドレス(URL)をコピーします(手順3)。切り離された画像を拡大して、右クリックすると「画像のアドレスをコピー」が表示されるので、クリックしてください。
次に、新しく生成したい画像のプロンプトを入力します(手順4)。チャットに「/imagine」と入力し、表示された「/imagine」を選択するか、キーボードの「Tabキー」を押しましょう。
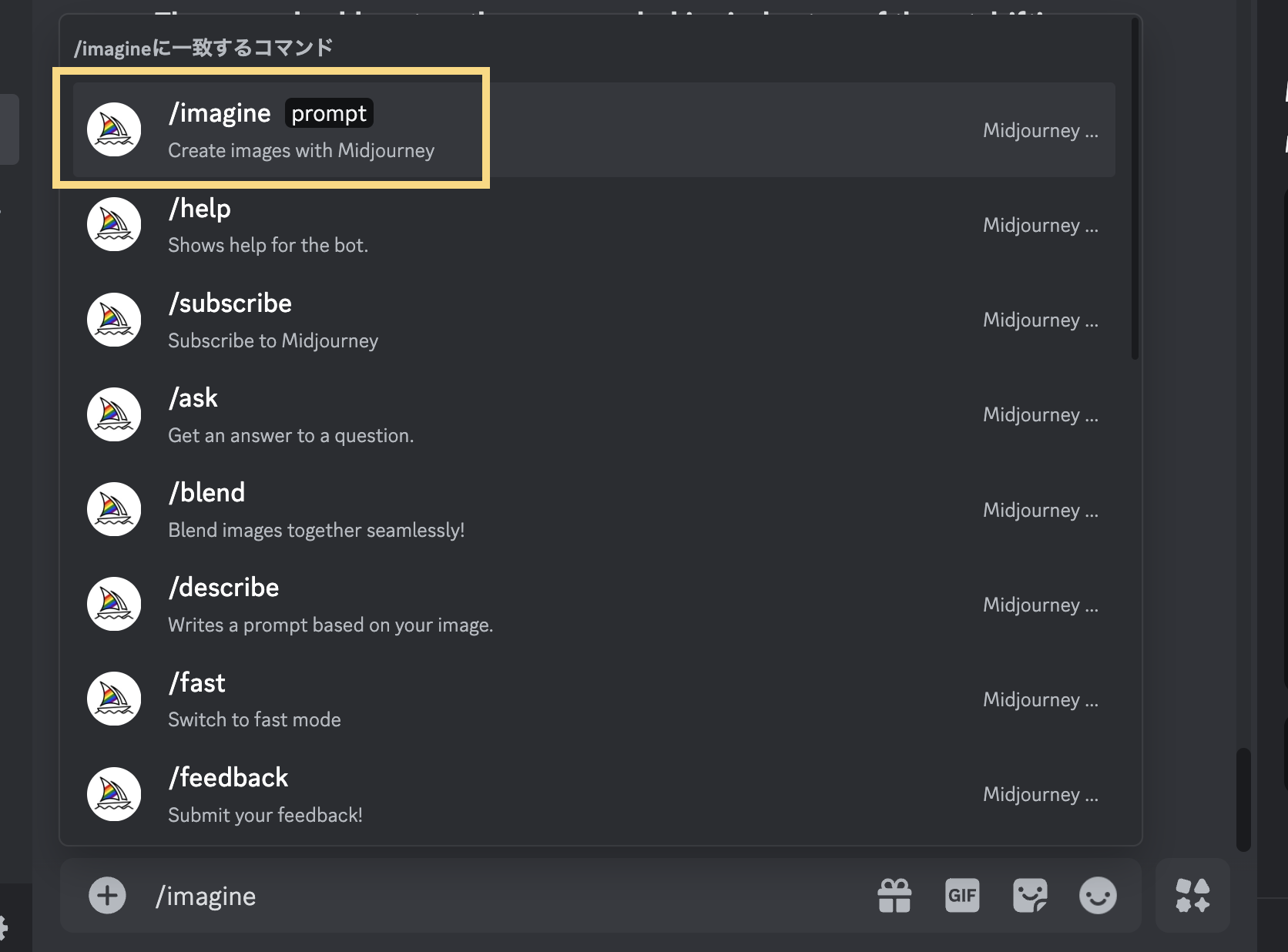
「/imagine」 を選択するとプロンプトの入力欄が出てきますので、新しく生成したい画像のプロンプトを入力してください。
プロンプトを入力したら、プロンプトのうしろに「––cref [URL]」を入力します(手順5)。
この「––cref」がキャラクターリファレンスの操作を指示するパラメーターです。以下の書き方を参考にしてください。
––crefの書き方
Illustration of a friendly artificial intelligence searching the internet _ ––cref _ https://s.mj.run/I3nQBgRebfs
- _ は半角スペース
- 青:プロンプト
- オレンジ:画像のURL、実際はさらに長いです
プロンプトの入力・編集と画像のアップが完了したら、この時点でキャラクターを参照した生成が可能です。
必要に応じて画像を参照する度合い(重み:––cw)※を入力すると、出力内容をより詳細に指示できます(手順6)。
※のちほど解説します
共通の機能「Vary」
Web版とDiscord版で共通の編集機能「Vary」があります。「Vary」は、元の画像からどのくらい変化させて生成するか選ぶ機能です。
「Subtle」と「Strong」の2種類あり、「Subtle」では元の画像から微妙な変化をし、「Strong」では大きな変化や新しいバリエーションが生じます。
Web版では、画像の詳細画面右下「Creation Actions」の中にあります。どちらか一方をクリックすれば生成開始です。
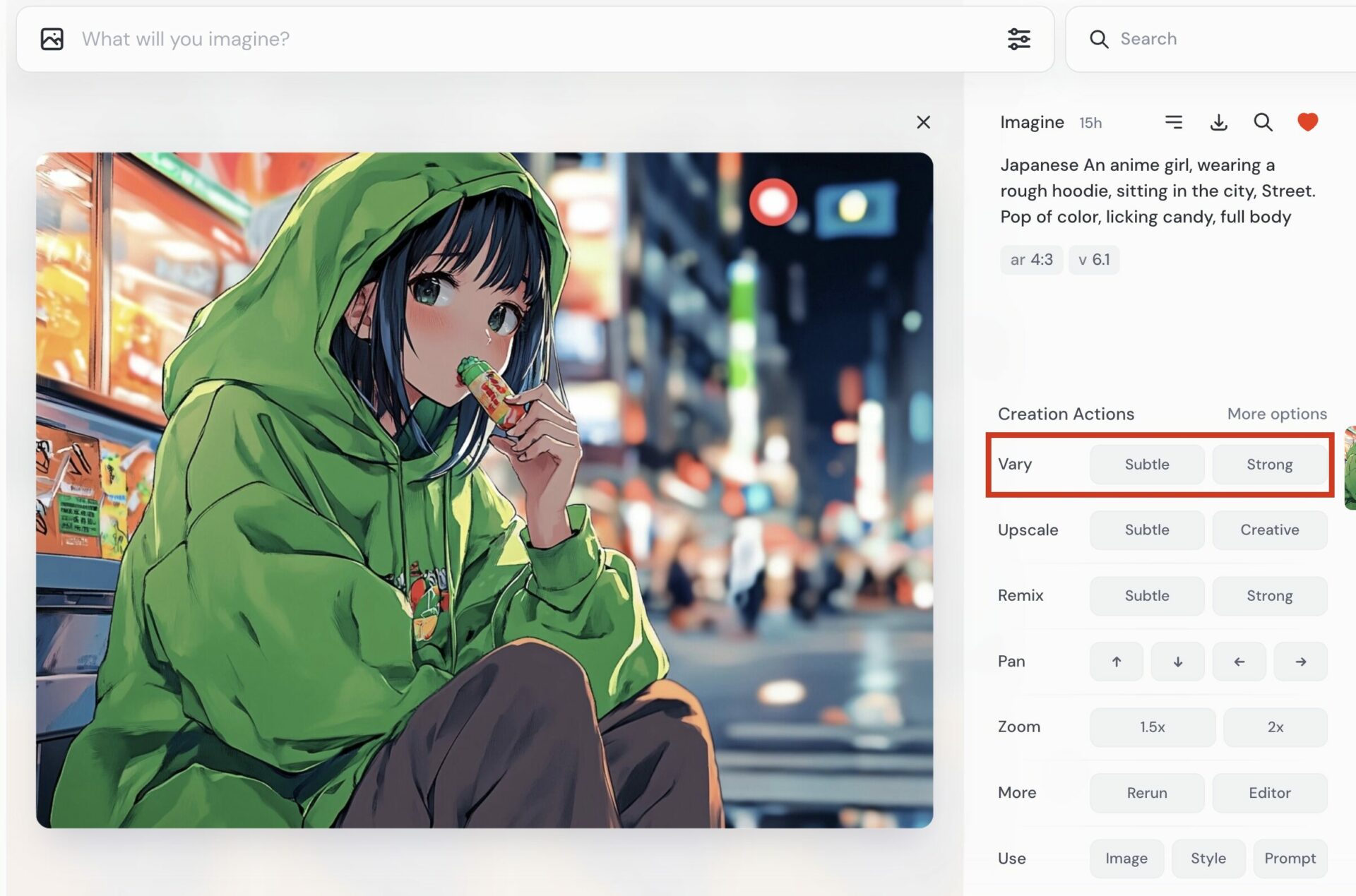
Discord版では、使う画像を切り離したのち、画像の下に表示されます。
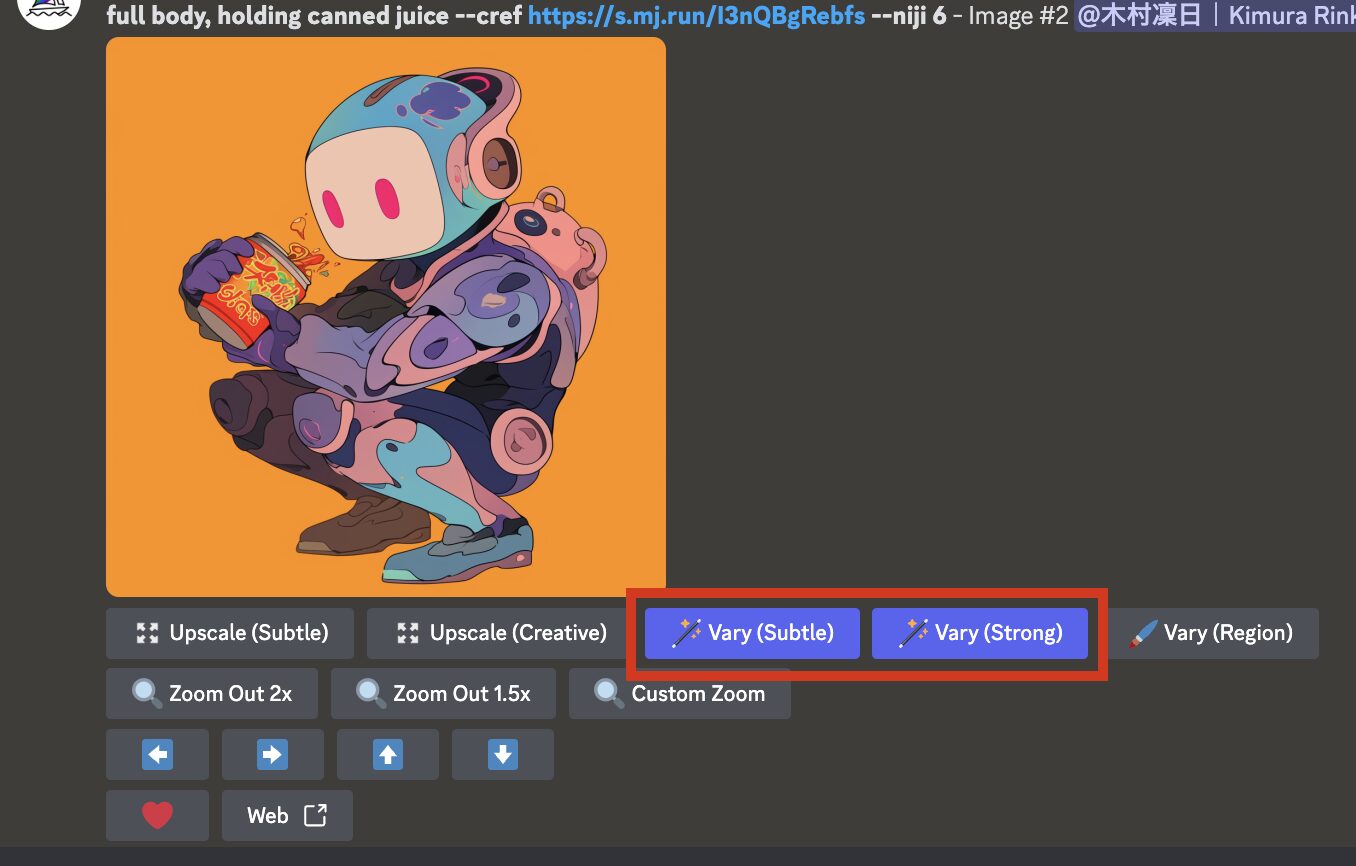
Discord版では、「Subtle」と「Strong」に詳細な設定を加えて出力できます。
結論、「Vary(Subtle)」を選択しつつ、設定を「subtle variation mode」にすると、元画像により近いキャラクターを生成可能です。
Discord版では、チャットで「/setting」を送信すると、使用するモデルや機能を設定できます(以下画像)。
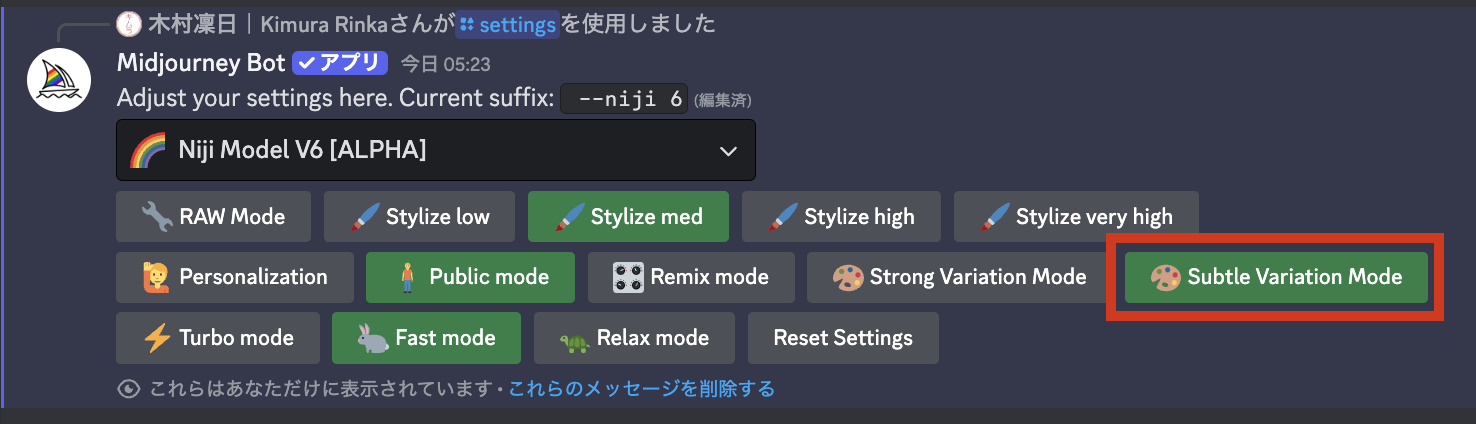
設定の中に「strong variation mode」「subtle variation mode」の2つがあるので、「subtle variation mode」のほうを選択しましょう。
「Vary」の各種類、そして「Mode」の各種類で出力がどのように異なるのか、実例を紹介します。使用する元画像は以下の画像です。
プロンプト
Illustration of a friendly artificial intelligence searching the internet, holding canned juice , Pixar style, with cool colors
この画像を元にして生成した画像を以下の順で紹介します。
以下の順は「より元画像に近い順」です。どのように異なるのか、ぜひ見比べてみてください。
- subtle variation mode・Vary(Subtle)
- subtle variation mode・Vary(Strong)
- strong variation mode・Vary(Subtle)
- strong variation mode・Vary(Strong)




順を追って、描き方がどんどんと変化しているのが見てとれるでしょう。
編集機能「Vary」を使って同じキャラクターを生成したいときは、「Vary(Subtle)」を選択しつつ、設定を「subtle variation mode」にするのがおすすめです。
Midjourneyでは、同じキャラや人物だけでなく、風景やスタイルなどの画像参照もできます。
画像を元にして新たな画像を生成する方法は以下の記事でまとめていますので、ぜひあわせてご覧ください。

Midjourneyでの同じキャラ生成は複数画像でも可能
Midjourneyで行う同じキャラの生成は、複数の画像を用いてもできます。
複数の画像を用いると、よりキャラクターのテイストや描き方が反映された画像の生成が可能です。
複数の画像を用いる方法を3つ解説します。参照に用いるのは以下2つの画像です。
- プロンプトを編集する方法
- ドラッグ&ドロップで行う方法
- 画像を混ぜ合わせる「Blend」も効果的

ドラッグ&ドロップで行う方法
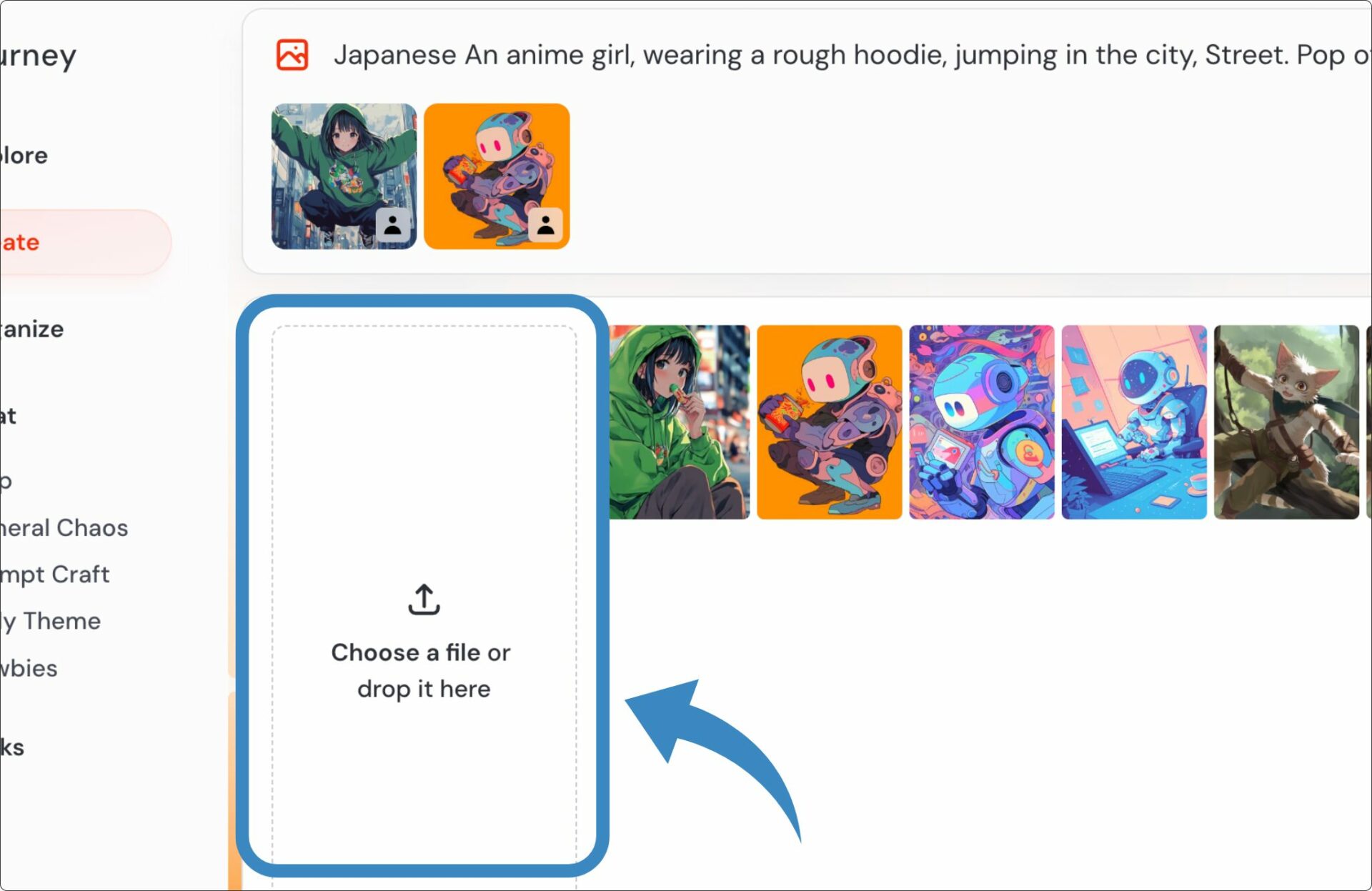
Web版の画像を読み込ませる手順を繰り返せば、複数の画像を入れられます。ドラッグ&ドロップかファイルのアップロードで読み込ませてください。
以下の画像からわかるように、2つの画像が参照されています。

画像を入れたあとは「人型のアイコン」を選択するのを忘れないようにしましょう。
プロンプトを編集する方法
Discord版で、「––cref [URL]」をプロンプトに追記する方法でも複数の画像を入れられます。
複数の画像を参照したいときは「––cref [URL] [URL]」の形です。「––cref」の次に半角スペース、1つ目の「[URL]」の次にも半角スペースを入れましょう。
複数の画像を参照するときの––crefの書き方
Illustration of a friendly artificial intelligence searching the internet _ ––cref _ https://s.mj.run/I3nQBgRebfs _ https://s.mj.run/QM0NJAwXJp0
- _ は半角スペース
- 青:プロンプト
- オレンジ:1つ目の画像のURL
- 赤:2つ目の画像のURL
実際にDiscordのチャットに打ち込むと、以下の画像のようになります。
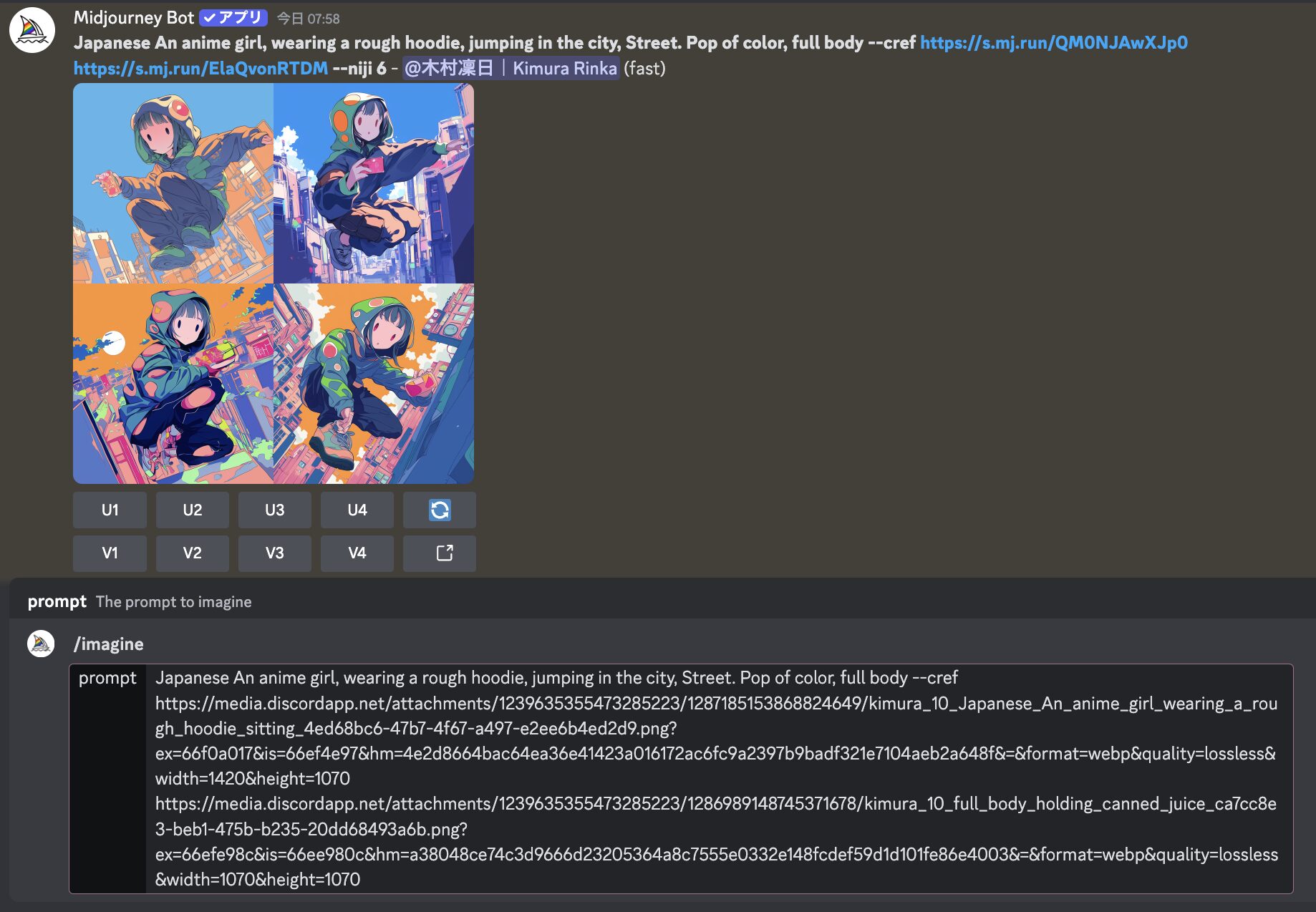
※出力されている画像はプロンプト送信後の結果
画像を混ぜ合わせる「Blend」も効果的
複数の画像を参照したいときは、画像を混ぜ合わせる「Blend」というコマンドも有効です。
Midjourney公式によると、コマンド「Blend」は、プロンプトに複数の画像のURLを入れ込む操作と同様とされています。
参考:Blend(Midjourney)
コマンド「Blend」を使う手順は以下のとおりです。
- チャットに「/blend」を送信
- 使いたい画像をアップロード
この手順を踏むと、以下のようにURLが記載されます。
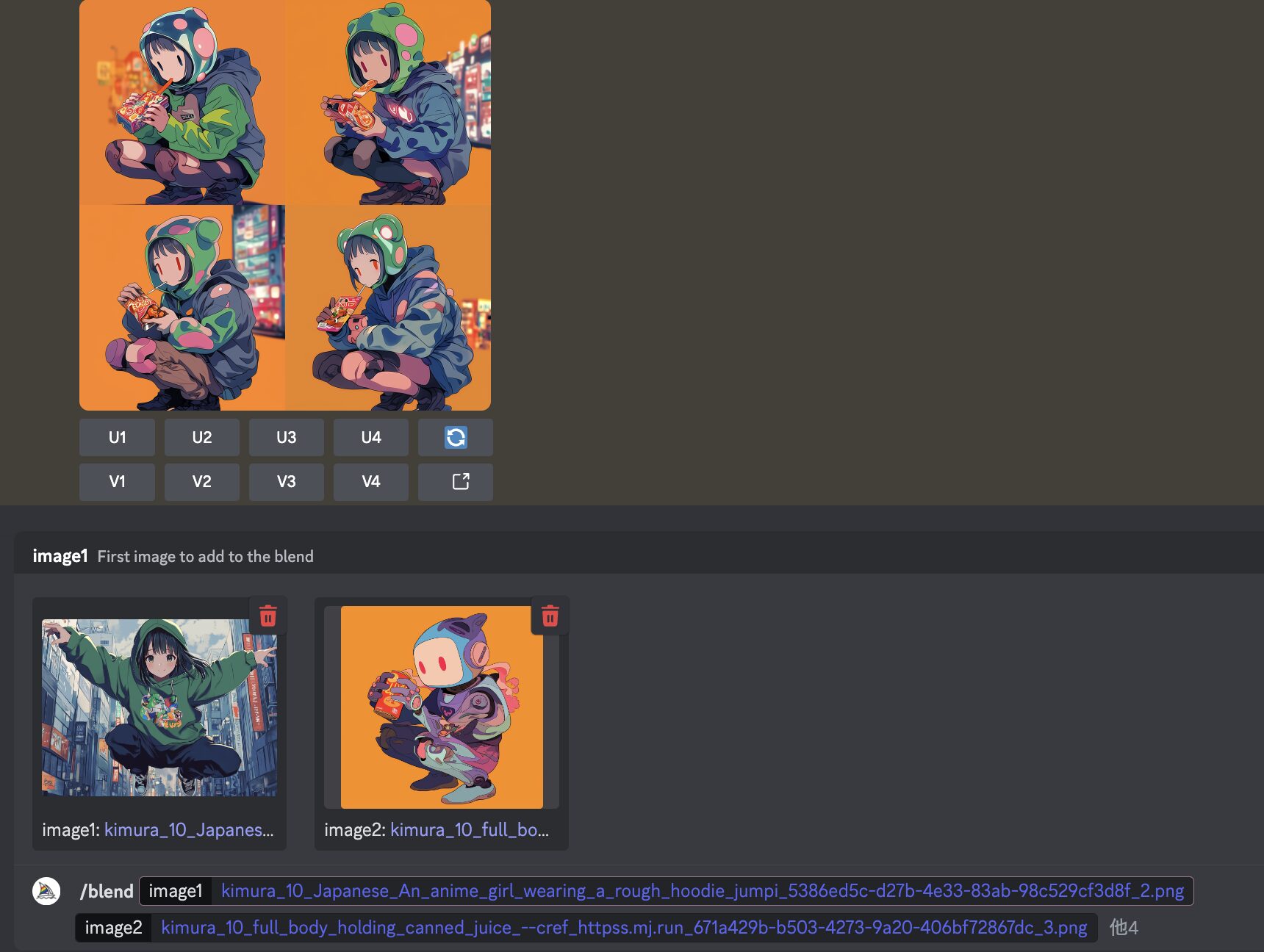
※出力されている画像はプロンプト送信後の結果
コマンド「/blend」で参照できる画像は最大5枚です。
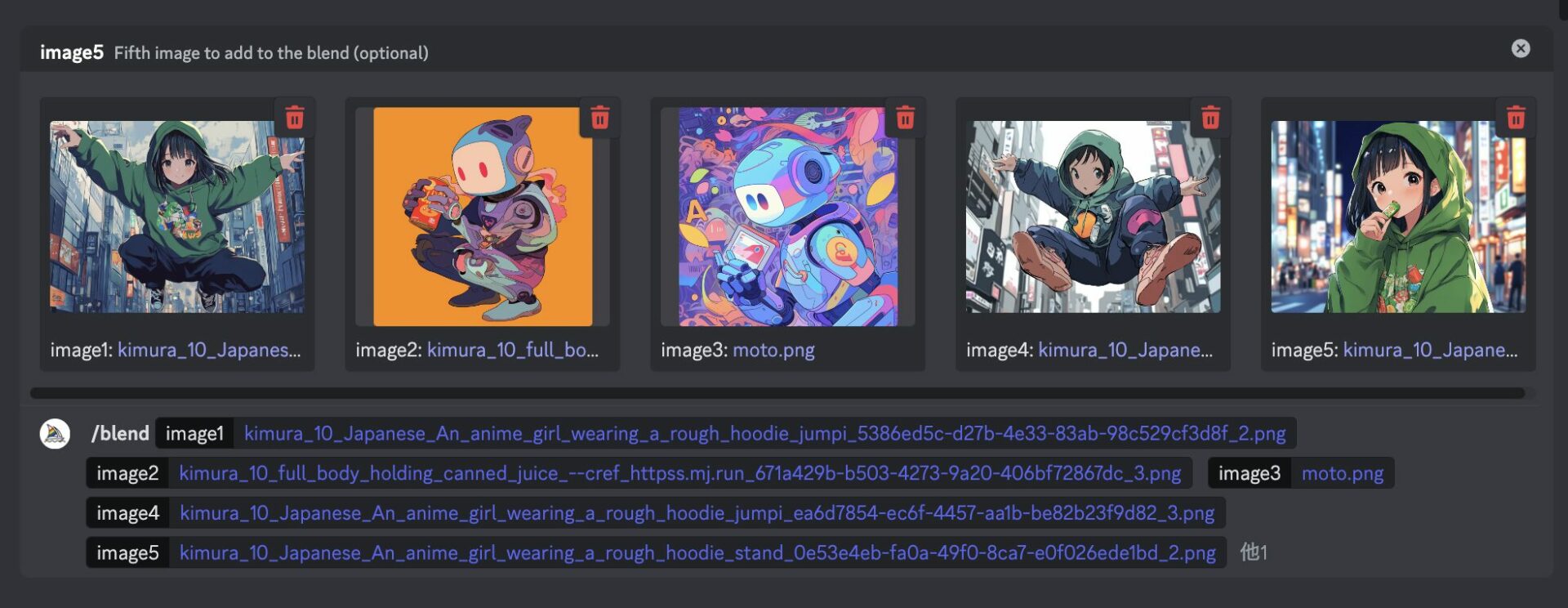
コマンド「/blend」を使って生成される画像は「1:1」の比率で出力されます。
生成後の画像が崩れる可能性があるため、できるだけ出力と同じ比率(1:1)の画像を参照するのがおすすめです。
画像を参照する度合いを調整できる「Character Weight」
画像のキャラクターを参照(キャラクターリファレンス)するとき、画像のどの部分を、どれくらい参照するのか指示できます。
この指示が「Character Weight」で、「––cw ◯」の形でプロンプトのうしろに記載します。
「Character Weight」の範囲は「0〜100」です。数値が低いほどキャラクターの顔にフォーカスし、高いほどキャラクターの全体を参照します。
数値100がデフォルト設定なので、「Character Weight」を明記しない場合、出力結果はキャラクター全体を参照したものです。
では、「––cw ◯」を使うとどのような出力になるのか、大きく以下の2つにわけて、実際の画像を紹介していきます。
- 「Character Weight」を変えた生成結果
- 「Character Weight」に「Style Weight」を掛け合わせた生成結果
以下は、参照する画像のプロンプトと画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, sitting in the city. Pop of color, licking candy, full body
この画像プロンプトにある「sitting in the city」を「standing in the city」と編集し、「––cw」を追記して生成していきます。
編集後のプロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body「Character Weight(cw)」を変えた生成結果
「Character Weight(cw)」だけを追記した生成結果を順に見ていきます。
以下の順は、キャラクター全体の参照からどんどんと顔にフォーカスしていく順です。
- 「––cw 100」(デフォルト)
- 「––cw 50」
- 「––cw 0」
1つ目は「––cw 100」の画像です。この画像はデフォルト設定で生成されたものなので、数値を変えた画像と見比べるときの基準になります。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 100
顔のパーツ自体には少々変化が見られます。しかし、服装や髪の長さ、フードを被った様子、キャンディーの色味は維持されているので、4枚ともキャラクター全体の描き方が反映されていることがわかります。
次は数値を「––cw 50」にした画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 50
顔のパーツ自体には少々変化が見られますが、眉や目の角度・描き方がほとんど変わらないので、「––cw 100」の画像よりキャラクターを反映している印象です。
また、服装や髪の長さ、キャンディーの色味、キャラクターのテイスト自体に変化があります。
このことから、キャラクター全体を参照する「––cw 100」に比べ、「––cw 50」のほうが、キャラクターの顔を参照する度合いが高まっているとわかります。
次は数値を「––cw 0」(キャラクターの顔のみにフォーカス)にした画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 0
顔のパーツや描き方、とくに“憂いのあるような目”が、元画像を強く反映して描かれました。
対して服装や髪の長さ、キャンディーの色味、キャラクターのテイストには、色や様子を含めて大きな変化があります。
生成結果は、元画像のキャラクターの顔を強く反映し、他の要素にはバリエーションが加わった、という印象です。
「Character Weight」に「Style Weight」を掛け合わせた生成結果
「Character Weight」と似たものに「Style Weight(画像のスタイルを参照)」があります。これら2つを掛け合わせると、より細部にこだわった出力結果が得られますので、今回はあわせて実例を紹介します。
以下は、参照する画像のプロンプトと画像です。
参考にする画像のプロンプト
Japanese An anime girl, wearing a rough hoodie, sitting in the city. Pop of color, licking candy, full body同様に「sitting in the city」を「standing in the city」と編集し、「––cw」「––sw」を追記して生成していきます。
編集後のプロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body「Style Weight(画像のスタイルを参照)」の数値の幅は「0〜1000」で「100」がデフォルトです。
数値が高いほど、より画像やキャラクターの構図や描き方が強く反映されます。
ここからは、同一の「––cw」を1グループとし、それぞれ「––sw」を変化させた以下の順で紹介します。
「––sw」の順は、キャラクターの構図や描き方の反映がどんどんと小さくなっていく順です。
| Character Weight | Style Weight |
|---|---|
| ––cw 100(デフォルト) | ––sw 1000 ––sw 500 ––sw 100 ––sw 0 |
| ––cw 50 | ––sw 1000 ––sw 500 ––sw 100 ––sw 0 |
| ––cw 0 | ––sw 1000 ––sw 500 ––sw 100 ––sw 0 |
––cw 100:Character Weight 100(デフォルト)
「Character Weight(cw)」をデフォルトの「––cw 100」にし、「Style Weight(sw)」を変えて追記した生成結果を順に見ていきます。
- 「––sw 1000」
- 「––sw 500」
- 「––sw 100」(デフォルト)
- 「––sw 0」
「––cw 100」に対して「––sw」の数値を小さくしていった結果は、まとめると以下2点になりました。
生成結果まとめ
- 「––cw」の影響で構図はほとんど維持される
- 「––sw」が小さくなるにつれて、背景やキャラクターの描き方に強く影響がある
では実際の画像を見ていきます。
1つ目は、「Style Weight(sw)」のうちもっとも大きい数値「––sw 1000」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 100 ––sw 1000
次は数値を「––sw 500」にした画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 100 ––sw 500
次は、デフォルトである数値「––sw 100」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 100 ––sw 100
次は「Style Weight(sw)」のうちもっとも小さい数値「––sw 0」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 100 ––sw 0
「––sw」の数値が小さくなるにつれて、構図やキャラクターの描き方がやや変わり、背景にも変化が現れてきています。
––cw 50:Character Weight 50
「Character Weight(cw)」を「––cw 50」にし、「Style Weight(sw)」を変えて追記した生成結果を順に見ていきます。
- 「––sw 1000」
- 「––sw 500」
- 「––sw 100」(デフォルト)
- 「––sw 0」
生成結果まとめ
- 「––cw」の影響で構図は多少維持されるが、顔の描き方はあまり変わらない
- しかし「––sw」の数値が大きくなると、背景や構図、服装に強く影響していく
では実際の画像を見ていきます。
1つ目は、「Style Weight(sw)」のうちもっとも大きい数値「––sw 1000」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 50 ––sw 1000
次は数値を「––sw 500」にした画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 50 ––sw 500
次は、デフォルトである数値「––sw 100」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 50 ––sw 100
次は「Style Weight(sw)」のうちもっとも小さい数値「––sw 0」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 50 ––sw 0
顔の描き方はあまり変わりませんが、背景や構図、服装に強く変化があることがわかります。
––cw 0:Character Weight
「Character Weight(cw)」を最も小さい「––cw 0」にし、「Style Weight(sw)」を変えて追記した生成結果を順に見ていきます。
- 「––sw 1000」
- 「––sw 500」
- 「––sw 100」(デフォルト)
- 「––sw 0」
「––cw 0」に対して「––sw」の数値を小さくしていった結果は、まとめると以下3点になりました。
生成結果まとめ
- 「––cw」の影響で顔の描き方はほとんど変わらない
- 「––sw」が小さくなるにつれて、顔の描き方が統一されていく
- 「––sw」が小さくなるにつれて、背景やキャラクターの描き方に強く影響がある
では実際の画像を見ていきます。
1つ目は、「Style Weight(sw)」のうちもっとも大きい数値「––sw 1000」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 0 ––sw 1000
次は数値を「––sw 500」にした画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 0 ––sw 500
次は、デフォルトである数値「––sw 100」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 0 ––sw 100
次は「Style Weight(sw)」のうちもっとも小さい数値「––sw 0」で生成した画像です。
プロンプト
Japanese An anime girl, wearing a rough hoodie, standing in the city. Pop of color, licking candy, full body ––cw 0 ––sw 0
「––cw 0」「––sw 0」になると、キャラクターの顔がほとんど維持され、背景や服装が大きく変化していることがわかります。
Midjourneyと並行して使ってみていただきたいのが、もうひとつの画像生成AI「Nano Banana」です。
「Nano Bananaは難しそうだけど使ってみたい」「Nano Bananaで思い通りの画像を作りたい」という方に向けて、この記事では「Nano Banana Pro大全」を用意しています。
この資料では、Nano Banana Proの基本的な使い方や、本記事では触れられていないプロンプトのコツなどを徹底解説しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってNano Bananaをマスターしてみましょう!
30秒で簡単受取!
無料で今すぐもらうMidjourneyでは画像の部分的な編集も可能
2024年9月現在、Midjourneyの編集機能を使えば、画像を部分的に描き替えられます。
描き替えの方法を、以下の環境別に解説します。
- Web版
- Discord版
部分的な描き替えをすれば、編集前の画像の全体像を維持しつつ、一部分だけに変化を加えられます。
Web版
Web版で部分的な描き替えを行う手順は以下のとおりです。
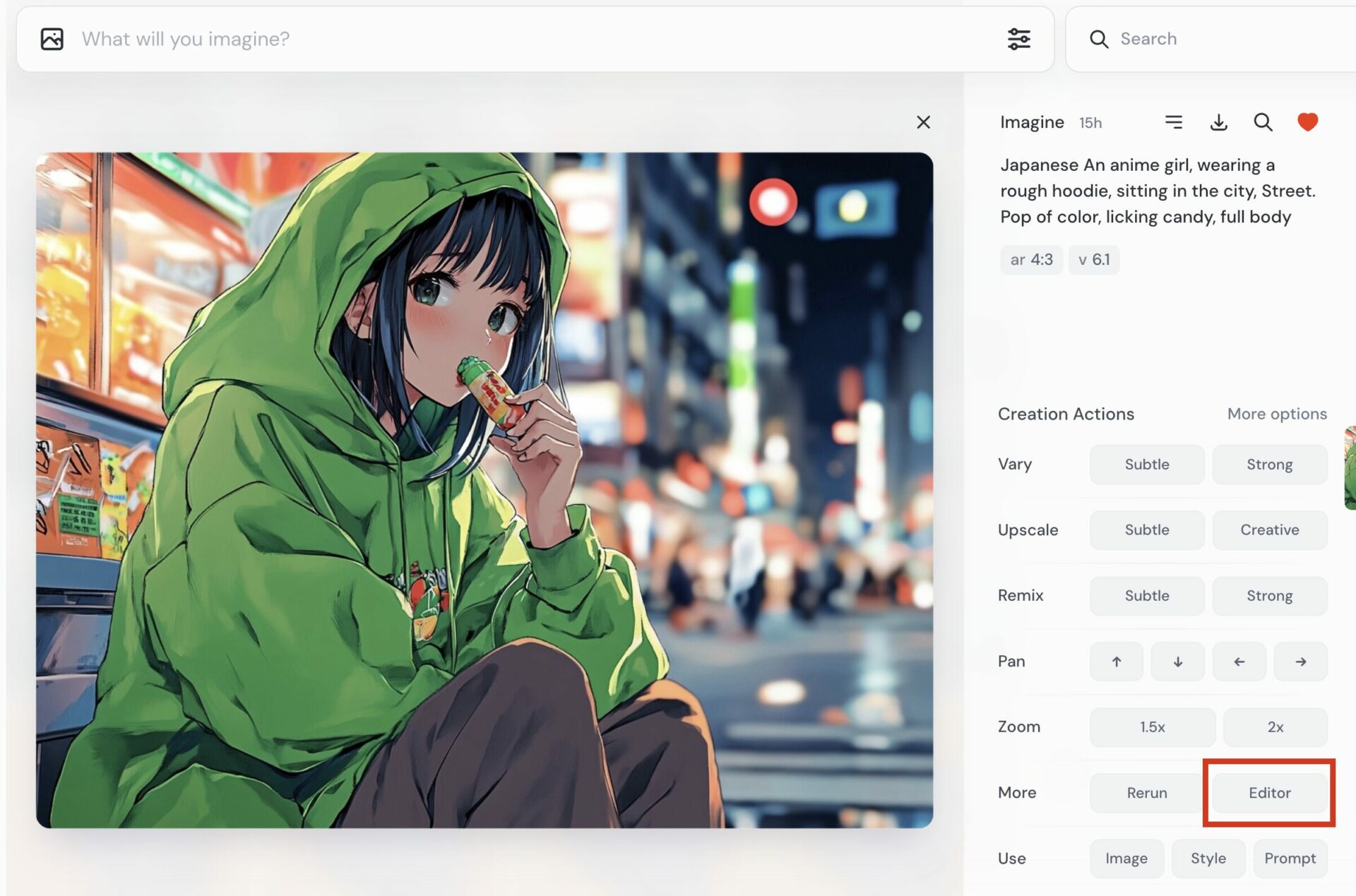
- 画像の詳細画面を開く
- 「Creation Actions」の「Editer」を選択
- 描き替えたい部分を選択
- 描き替えたい部分のプロンプトを編集
- 送信
まずは画像の詳細画面を開きましょう(手順1)。開くと以下のような画面になるので、「Creation Actions」の「Editer」を選択してください(手順2)。
「Editer」を選択すると、以下の画面になります。
「Erace」で描き替えたい部分を消しましょう(手順3)。今回は髪の色を変えたいので、キャラクターの髪の部分を消しています。
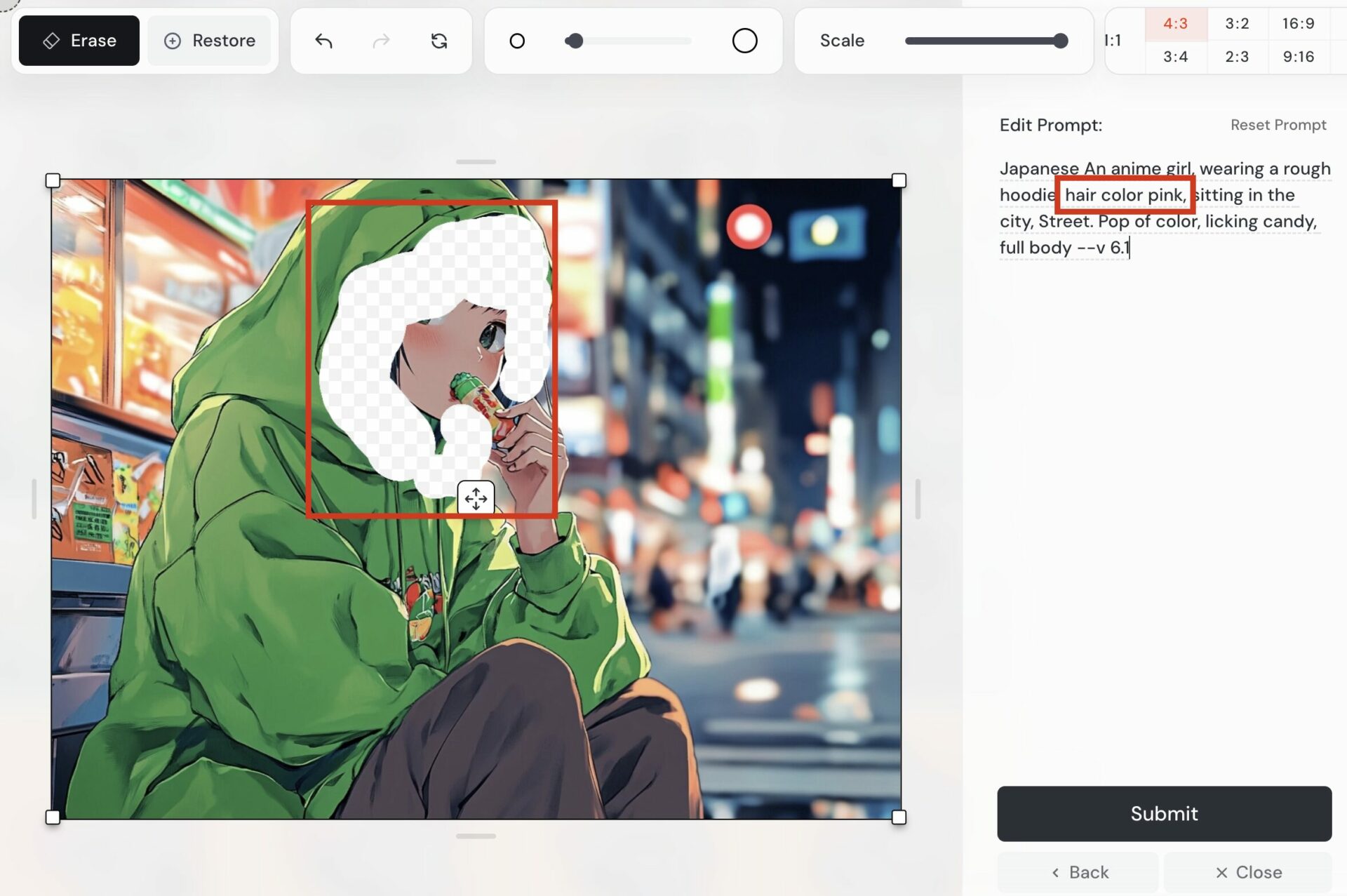
次に、描き替えたい内容にプロンプトを編集します(手順4)。今回は髪の色をピンクにしたいので「hair color pink」を追記しました。
編集後のプロンプト
Japanese An anime girl, wearing a rough hoodie, hair color pink, sitting in the city. Pop of color, licking candy, full bodyプロンプトを編集して送信し、出力されたのが以下の画像です。どの画像も、髪以外の描き方は変わらず、黒髪がピンク色に変わっています。

Discord版
Discord版で部分的な描き替えを行う手順は以下のとおりです。
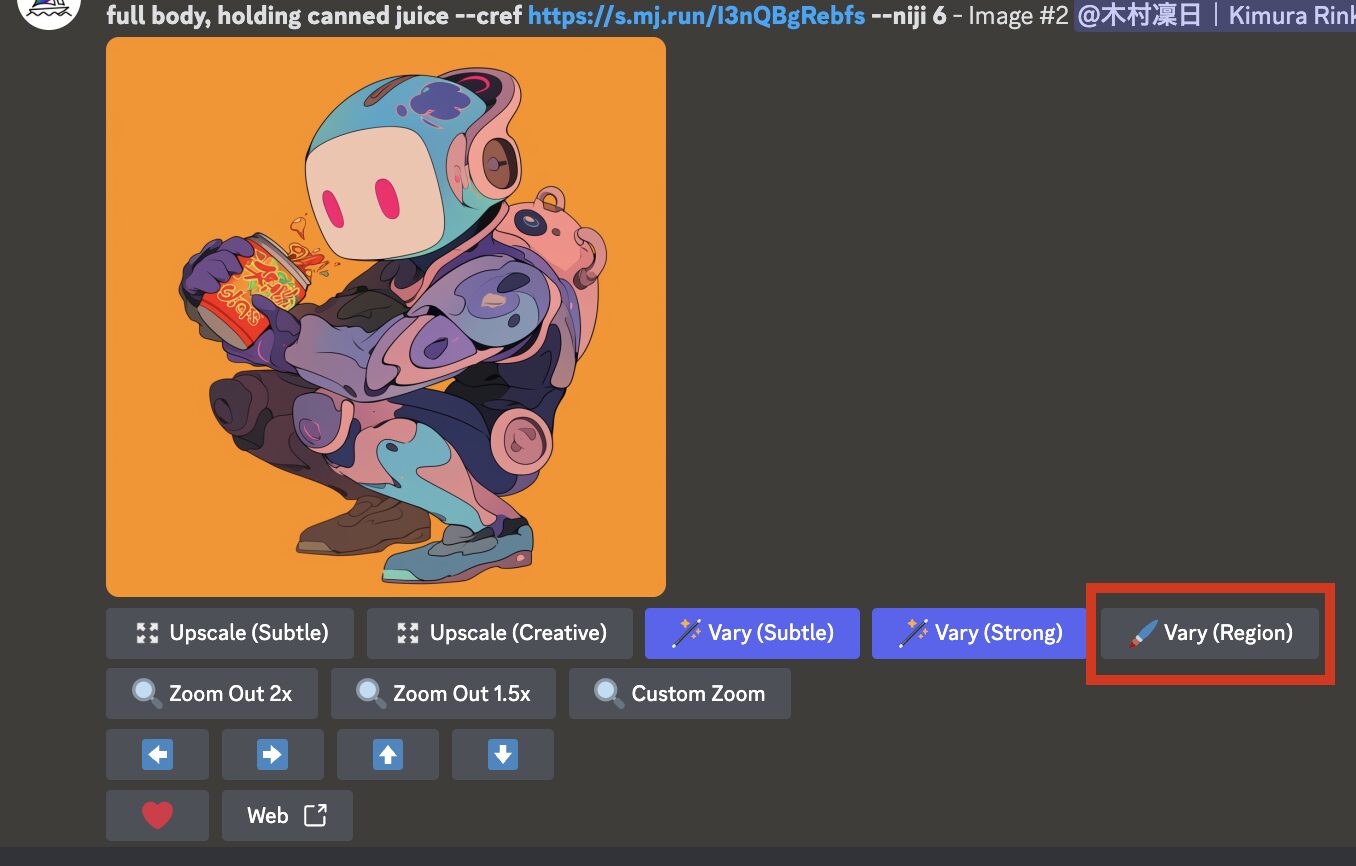
- 使用したい画像の下「Vary(Region)」を選択
- 描き替えたい部分を選択
- 描き替えたい部分のプロンプトを編集
- 送信
画像の案(グリッド)から画像を切り離すと、以下のように画像に行える操作が表示されますので、「Vary(Region)」を選択してください(手順1)。
「Vary(Region)」を選択すると、以下の編集画面になります。ドラッグで編集したい範囲を選択しましょう(手順2)。
今回はロボットが持っている物を変えたいので、物の範囲を選びました。
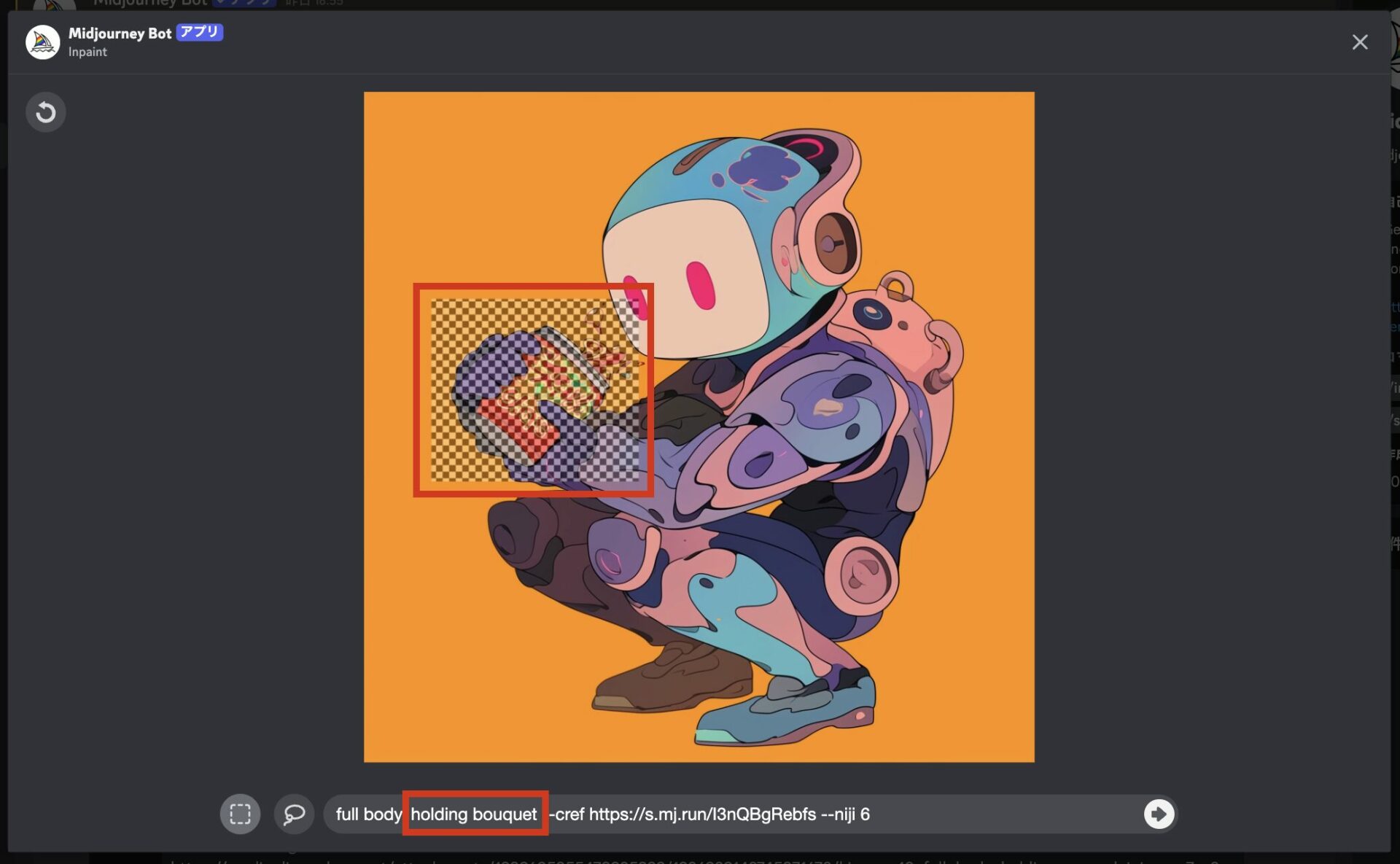
次に、描き替えたい内容にプロンプトを編集します(手順3)。今回は花束を持たせたいので「holding bouquet」と編集しました。
編集後のプロンプト
full body, holding bouquet --cref https://s.mj.run/I3nQBgRebfs --niji 6プロンプトを編集して送信し、出力されたのが以下の画像です。どの画像も、全体の描き方は変わらず、持っている物だけ花束に変わっています。

キャラクターリファレンスで多様なキャラ生成ができる!
キャラクターリファレンスの機能を使えば、お気に入りのキャラクターの構図やポーズ、表情などを変え、多様なキャラクター生成ができます。
使用するモードやプロンプト・パラメーターの組み合わせによって変化の仕方はさまざまです。
ぜひこの記事を参考にして、お気に入りのキャラクターでキャラクターリファレンスを試してみてください。キャラクターリファレンスの機能をスムーズに使えるようになったら、副業にも結びつくなど可能性の幅が広がります。
Midjourneyを使いこなして、画像生成の幅がぐっと広がったら、もうひとつの画像生成AI「Nano Banana」もぜひお試しください。
「Nano Bananaは難しそうだけど使ってみたい」「Nano Bananaで思い通りの画像を作りたい」という方に向けて、この記事では「Nano Banana Pro大全」を用意しています。
この資料では、Nano Banana Proの基本的な使い方や、本記事では触れられていないプロンプトのコツなどを徹底解説しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってNano Bananaをマスターしてみましょう!
30秒で簡単受取!
無料で今すぐもらう目次


執筆者

木村凛日
SHIFT AI TIMESのディレクター長・SEOライター。採用・デザイン・教育も担当です。
AIを活用したリサーチ・分析・画像や動画生成・アプリ構築を日々行っています。
200名以上のWebライターの育成経験あり。
他メディアではデータ分析・リライト・ライター育成も担当。ゼロからスタートなメディアの運営にも携わっています。
パンダが好きです。











30秒で簡単受取!
無料で今すぐもらう