share



ChatGPTでプログラミングが超効率的に!?4つの活用法や注意点などを紹介!

プログラミングには複雑なアルゴリズムの実装やエラーの解決など多くの課題がつきもので、頭を悩ませることが多々ありますよね。
そのような課題を効率的に解決する手段として、ChatGPTの活用が注目を集めています。
ChatGPTは高いプログラミング能力と言語能力を持ち合わせており、これを活用することでプログラミングを効率的に進められます。
具体的には、コード生成からデバッグ支援、学習サポートまで、プログラミングのほぼすべての工程で活用可能です。
これにより、経験豊富なエンジニアはもちろん、経験の浅いエンジニアでも、効率的かつ正確なプログラミングを行えるようになります。
本記事ではChatGPTの具体的な活用法や注意点、ChatGPTの各モデル(GPT-4、GPT-4o、GPT-4o mini)の性能比較結果を詳しく紹介します。
本記事を最後まで読むことで、プログラミングにChatGPTを最大限に活用する方法やコツを理解でき、個人だけでなく組織全体の業務効率を飛躍的に向上できます。
以下の記事では、ChatGPTの能力とエンジニアの関係について解説しています。「仕事がなくなるかも」と不安に感じている方はぜひチェックしてみてください。
関連記事:ChatGPTはエンジニアの仕事を奪うのか?生成AIの影響と事例3選を徹底解説

監修者
SHIFT AI代表 木内翔大
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
目次
ChatGPTは本当にプログラミングに活用できるのか?
ChatGPTはプログラミングの効率を大幅に向上させる強力なツールであり、コード生成からデバッグ支援、学習サポートまで、幅広い用途でエンジニアをサポートできます。
ChatGPTのプログラミングへの活用可能性は、その高度な自然言語処理能力と膨大な知識にもとづいています。
プログラミング言語や開発手法に関する豊富な知識を持つChatGPTは、エンジニアと対話しながら、複雑な問題を解決したり、コードを提案したりできます。
例えば、特定の機能を実装するためのコードスニペットを生成したり、エラーメッセージの意味を解説したりするなど、ChatGPTはエンジニアの日常的なタスクを支援してくれます。
ChatGPTでのコード生成の重要なポイントを押さえて、コーディングタスクの効率化やコーディングスキルを向上させたい方は、以下の記事もごらんください。

ChatGPTのプログラミングでの活用法4選
ChatGPTは、プログラミングの様々な場面で活用できる強力なツールです。
ここでは、特に効果的な以下の4つの活用法を詳しく紹介します。
- コード生成
- デバッグ支援
- 学習サポート
- 言語間翻訳
以下の記事では、ChatGPTとVSCodeを連携について解説しています。「作業の手戻りやミスを減らし、より効率的にコーディングを進めたい」という方はぜひあわせてチェックしてみてください。
関連記事:ChatGPTとVSCodeを連携!2つの方法や注意点などを紹介!
コード生成
ChatGPTは、エンジニアの要求に応じて効率的にコードを生成する能力を持っており、開発プロセスを大幅に加速できます。
ChatGPTによるコード生成は、単純な関数から複雑なアルゴリズムまで、幅広い範囲をカバーします。
例えば、「Pythonで二分探索アルゴリズムを実装してください」という要求に対して、ChatGPTは以下のように適切なコードを提案できます。
ChatGPTを使用したコード生成の利点は、迅速性と柔軟性です。
エンジニアは、自然言語で要求を伝えるだけで、基本的なコード構造を得ることができ、コーディングタスクを大幅に効率化することが可能になります。
ただし、後ほど詳しく解説しますが、ChatGPTが生成したコードは必ずしも最適化されているわけではありません。
そのため、生成されたコードを理解し、必要に応じて最適化や修正を加えることが重要です。
また、特定のプロジェクトや環境に合わせてカスタマイズする必要がある場合もあります。
デバッグ支援
ChatGPTは、エンジニアがコードのデバッグを行う際に強力な支援ツールとしても活用可能です。
エラーメッセージの解釈から潜在的な問題箇所の特定まで、デバッグプロセス全体をサポートできます。
ChatGPTを使用したデバッグ支援の主な利点は、エラーの迅速な理解と解決策の提案です。
例えば、「このエラーは何?SyntaxError: invalid syntax」という質問に対して、そのエラーの意味を説明し、考えられる原因と解決策を提案してくれます。
出力例
問題のコードと共に入力することでより効果的に解決策を提示してくれます。
さらに、ChatGPTはコードの論理的な問題を特定するのにも役立ちます。
エンジニアが期待する動作と実際の動作の差異を説明すると、ChatGPTは潜在的な問題箇所を指摘し、修正案を提示できます。
ただし、特定のプロジェクト環境や複雑な依存関係に起因する問題は、ChatGPTだけでは完全に解決できない場合があります。
そのため、ChatGPTの提案を参考にしつつ、エンジニア自身の知識と経験にもとづいて判断を下すことが重要です。
学習サポート
ChatGPTは、プログラミング学習者にとって優れた学習サポートツールとしても活用可能です。
初心者から上級者まで、さまざまなレベルの学習者にあわせた支援を提供できます。
ChatGPTを使用した学習サポートの主な利点は、即時的なフィードバックと説明の提供です。
学習者は、特定のプログラミング概念や技術について質問すると、ChatGPTからわかりやすい説明や具体例を得られます。
例えば、「オブジェクト指向プログラミングとは何ですか?」という質問に対して、ChatGPTは基本的な概念説明から実際のコード例まで、段階的な解説を提供します。
また、学習者のレベルに応じて、説明の深さや複雑さを調整することも可能です。
出力例
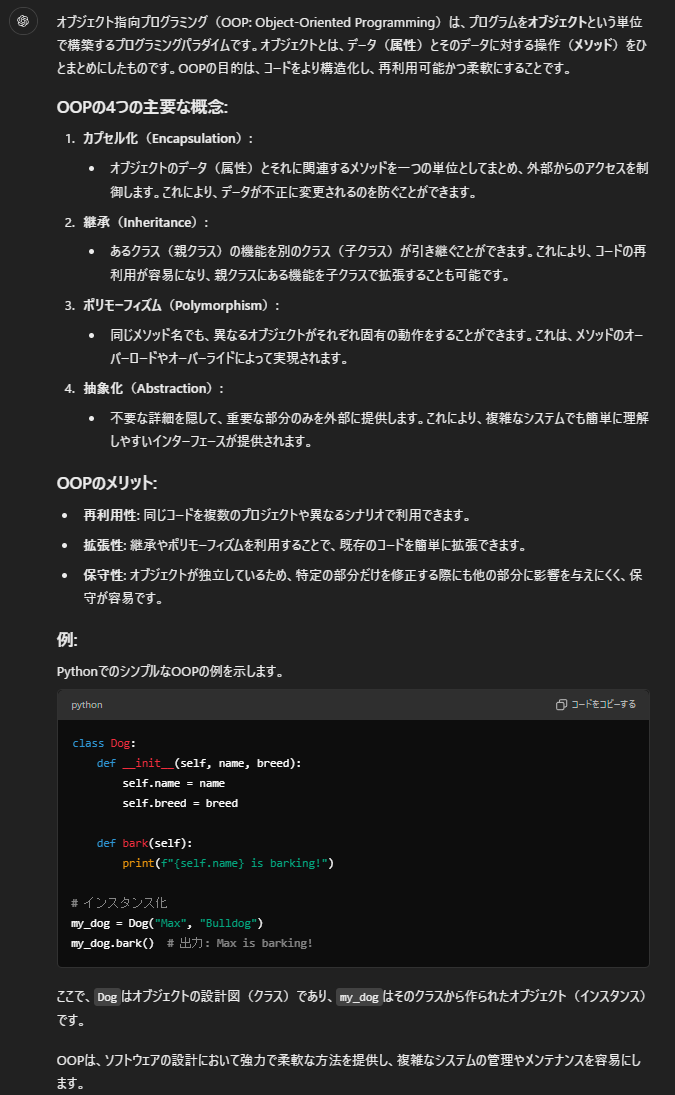
さらに、ChatGPTは練習問題の生成や、コードレビューの提供など、実践的な学習支援も行えます。
学習者は自分のペースで問題に取り組み、解答後にChatGPTからフィードバックを得ることで、理解を深められます。
ただし、ChatGPTによる学習サポートは、人間の教師や経験豊富なエンジニアからの指導を完全に代替することはできません。
実際のプロジェクト経験や、業界の最新トレンドにもとづいた指導は、依然として人間の専門家にしていただく必要があります。
言語間翻訳
ChatGPTは、異なるプログラミング言語間でのコード翻訳でも強力なサポートツールとして機能します。
とくに、既存のコードを新しい言語に移植する際や、複数の言語を使用するプロジェクトでの作業効率を向上させる際に有用です。
ChatGPTによる言語間翻訳の主な利点は、迅速性と柔軟性です。
エンジニアは、ある言語で書かれたコードを別の言語に翻訳する要求を出すだけで、基本的な翻訳結果を得られます。
これにより、言語間の移行を簡単に実現でき、開発時間を短縮することが可能になります。
例えば、「このPythonコードをJavaに翻訳してください」という要求に対して、ChatGPTは元のコードの機能を維持しつつ、Javaに翻訳してくれます。
出力例
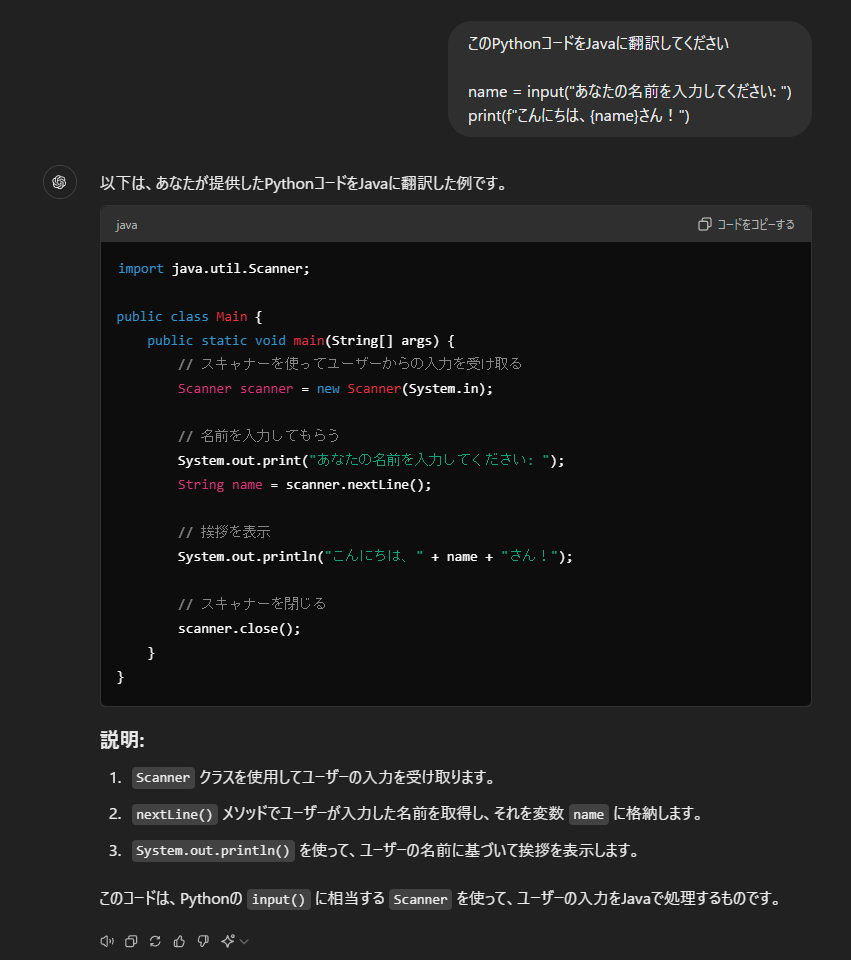
また、言語固有の機能や最適化についても、適切な提案を行えます。
ただし、ChatGPTは完全に最適化された翻訳を提供するわけではありません。
特に、複雑なコードや言語固有の高度な機能を扱う場合は、人間のエンジニアによる確認と調整が必要ということに注意が必要です。
ChatGPTへの指示のコツ4選
ChatGPTをプログラミングに効果的に活用するためには、適切な指示の出し方が重要です。
ここでは、ChatGPTから最適な結果を得るための以下の4つのコツを詳しく紹介します。
- 具体的な指示を出す
- 段階的に質問する
- 期待する出力例を提供
- プロジェクト全体の説明をする
具体的な指示を出す
ChatGPTに対して具体的な指示を出すことは、望む結果を得るための非常に重要なステップです。
曖昧な質問や指示は、不明確または不適切な回答につながる可能性があります。
具体的な指示を出すためには、以下の点に注意することが効果的です。
まず、使用するプログラミング言語やフレームワークを明確に指定します。
例えば、「Pythonを使用して」や「React.jsフレームワークで」などと指定することで、ChatGPTは適切なコンテキストで回答を生成できます。
次に、実装したい機能や解決したい問題を詳細に説明します。
例えば、「ユーザー認証機能を実装したい」という漠然とした指示よりも、
「電子メールとパスワードを使用したユーザー登録、ログイン、ログアウト機能を実装したい」
というように、具体的な要件を示すことが重要です。
また、期待する入力と出力、エラーハンドリングの要件、パフォーマンスの制約など、可能な限り多くの詳細情報を提供することで、より精度の高い回答を得られます。
例えば、「ソート機能を実装してください」という指示よりも、
「整数の配列を受け取り、クイックソートアルゴリズムを使用して昇順にソートする関数をPythonで実装してください。関数名はquick_sortとし、時間計算量はO(n log n)を目指してください」
というように具体的に指示することで、より適切な回答を得られる可能性が高まります。
ChatGPTを用いた要件定義については以下の記事で詳しく解説しています。
関連記事:ChatGPTで要件定義を効率化!4つの事例で手順と詳細なプロンプトも紹介
段階的に質問する
複雑な問題や大規模なプロジェクトに取り組む場合、一度にすべての情報を提供するよりも、段階的に質問することが効果的です。
この方法により、各ステップでより詳細かつ正確な情報を得られ、最終的な結果の質を向上できます。
段階的な質問のアプローチは、以下のように進められます。
まず、問題の概要や基本的な要件について質問します。
次にChatGPTから得られた回答をもとに、より具体的な詳細や実装方法について掘り下げていきます。
例えば、ウェブアプリケーションの開発を行う場合、以下のような段階を踏んでみましょう:
- アプリケーションの基本構造について質問する
- データベース設計に関する助言を求める
- 特定の機能(例:ユーザー認証)の実装方法について詳細を尋ねる
- フロントエンドのデザインパターンについて相談する
- セキュリティ対策やパフォーマンス最適化について質問する
このように段階的に質問することで、ChatGPTが各ステップでより深い洞察を得ることができ、プロジェクト全体の質を向上できます。
期待する出力例を提供
ChatGPTに期待する出力例を提供することは、より正確で適切な回答を得るための効果的な方法です。
出力例を示すことで、ChatGPTは要求をより明確に理解し、それに沿った回答を生成できます。
期待する出力例を提供する際は、以下の点に注意すると良いでしょう。
まず、可能な限り具体的かつ詳細な例を示します。
例えばコードスニペットや関数のシグネチャ、期待する戻り値など具体的な形式や構造を指定することで、ChatGPTはより正確に要求を理解できます。
また、複数の例を提供することも効果的であり、異なるケースや条件下での期待する出力を示すことで、ChatGPTはより包括的に質問を理解して回答を生成できます。
例えば、「文字列を逆順にする関数を実装してください」という質問をする際は、以下のような出力例を共に提供するとよいでしょう:
# 期待する関数のシグネチャ
def reverse_string(input_string: str) -> str:
# 実装をここに記述
# 期待する動作例
assert reverse_string("hello") == "olleh"
assert reverse_string("Python") == "nohtyP"
assert reverse_string("") == ""
assert reverse_string("a") == "a"このように具体的な例を提供することで、ChatGPTはより正確に要求を理解し、期待通りの実装を提案できます。
プロジェクト全体の説明をする
ChatGPTに対してプロジェクト全体の説明を行うことは、より適切かつ一貫性のある助言や提案を得るために重要です。
プロジェクトの背景、目的、全体的な構造を理解することで、ChatGPTはより文脈に沿った回答を提供できます。
プロジェクト全体の説明を行う際は、以下の要素を含めることが効果的です:
- プロジェクトの目的と背景
- 使用する技術スタック(プログラミング言語、フレームワーク、データベースなど)
- 主要な機能や要件
- ターゲットユーザーや使用環境
- 既存のコードベースや統合する必要のある外部システム
- 性能要件やスケーラビリティの考慮事項
例えば、
「オンライン書店のウェブアプリケーションを開発しています。Pythonのフレームワークであるdjangoを使用し、PostgreSQLデータベースを利用します。主な機能として、ユーザー登録、書籍検索、カート機能、決済処理が必要です。また、将来的には1日10万人程度のアクセスに対応できるスケーラビリティが求められます。」
というように、プロジェクトの全体像を説明します。
プロジェクト全体の説明を提供することで、ChatGPTはより適切なアーキテクチャの提案や潜在的な課題の指摘など、プロジェクト全体を考慮した有益な助言を提供できます。
ChatGPTを用いた仕様書作成について気になる方は、ぜひ以下の記事をチェックしてみてください。
関連記事:ChatGPTで仕様書作成が劇的に効率化!5つの手順で生成方法を紹介
GPT-4o、GPT-4o mini、GPT-4のプログラミング能力を比較してみた!
現在ChatGPTで利用できるモデルは、GPT-4o、GPT-4o mini、GPT-4の3つです。
GPT-4oはOpenAIの最新モデルであり、GPT-4に比べて言語処理能力やマルチモーダル能力が大幅に強化されています。
さらに応答速度も2倍速くなり、コスト効率も向上しています。
GPT-4o miniはGPT-4oの小型版で、性能とコスト効率のバランスに優れたモデルです。
GPT-3.5を代替する目的で開発され、GPT-4oに近い性能を保ちながら、コストや計算資源を大幅に削減しています。
GPT-4は、GPT-4oが登場するまでOpenAIのフラッグシップモデルとして、多くのアプリケーションやAPIで利用されてきました。
ChatGPTでは、プランにより利用できるモデルや制限に違いがあります。
Free、Plus、Team、Enterpriseの4つのプランがあり、Freeプランでも最上位モデルのGPT-4oに制限付きでアクセスできます。
Plus以上の有料プランでは、基本的に3つのモデルすべてにアクセスできるので、環境に合わせて最適なプランを選択してください。
最適なプラン、モデルを選択することで、ChatGPTによる業務効率化の効果が最大限高まります。
ここからは、現在ChatGPTで利用できる3つのモデルのプログラミング能力を、以下の3つの観点から比較します。
- APIの呼び出しコード生成
- コードレビュー、デバッグ
- PythonからJavaへの翻訳
各モデルを比較することで、シチュエーションごとにどのプランでどのモデルを使うのが最適か明確になります。
早速検証を始めていきましょう。
APIの呼び出しコード生成
APIの呼び出しコード生成は、外部サービスやライブラリとの連携において重要なタスクです。
このタスクでの3つのモデルの性能を比較するため、一般的なRESTful APIの呼び出しコードを生成するタスクを実施しました。
プロンプト
Pythonで、`https://api.example.com/resource`に対してPOSTリクエストを送信するコードを生成してください。
リクエストボディは次のJSONデータです:
```json
{
"name": "John",
"email": "john@example.com"
}
```
レスポンスを表示するコードも追加してください。出力結果は以下のとおりです。
GPT-4o
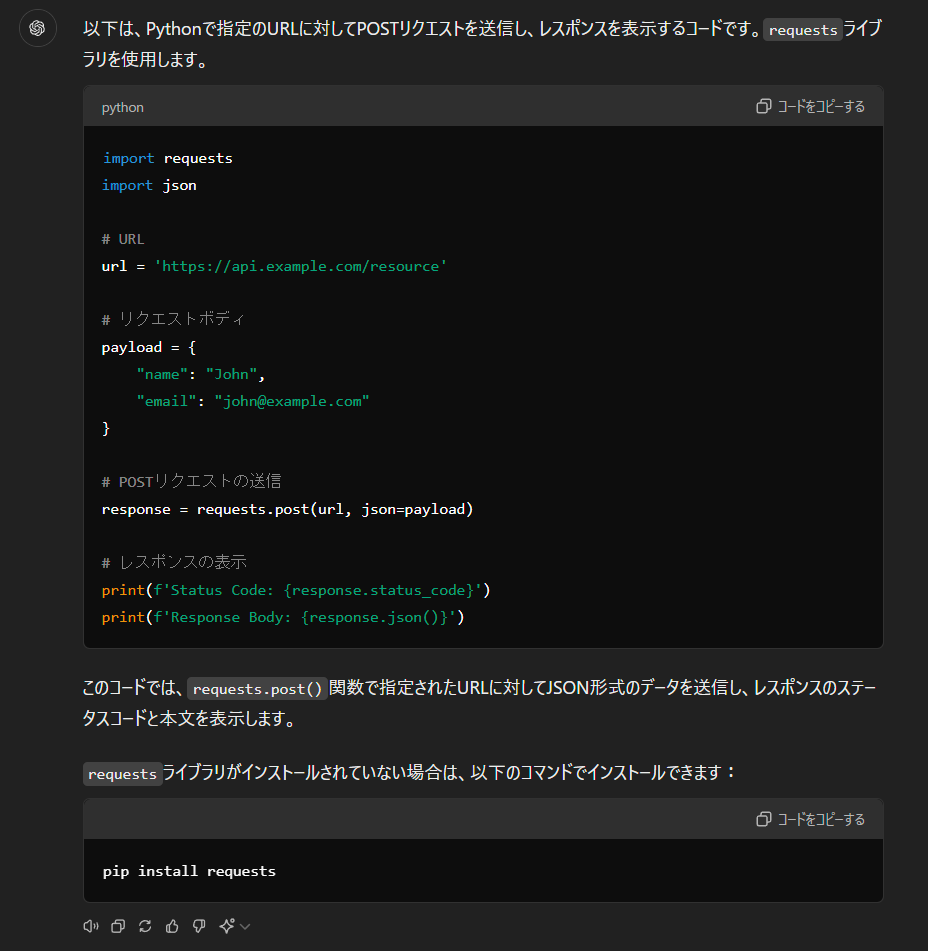
以下は、Pythonで指定のURLに対してPOSTリクエストを送信し、レスポンスを表示するコードです。`requests`ライブラリを使用します。
```python
import requests
import json
# URL
url = 'https://api.example.com/resource'
# リクエストボディ
payload = {
"name": "John",
"email": "john@example.com"
}
# POSTリクエストの送信
response = requests.post(url, json=payload)
# レスポンスの表示
print(f'Status Code: {response.status_code}')
print(f'Response Body: {response.json()}')
```
このコードでは、`requests.post()`関数で指定されたURLに対してJSON形式のデータを送信し、レスポンスのステータスコードと本文を表示します。
`requests`ライブラリがインストールされていない場合は、以下のコマンドでインストールできます:
```
pip install requests
```GPT-4o mini
もちろんです!以下はPythonで`https://api.example.com/resource`に対してPOSTリクエストを送信し、レスポンスを表示するコードです。`requests`ライブラリを使用していますので、もしまだインストールしていない場合は、`pip install requests`でインストールしてください。
```python
import requests
# リクエストURL
url = 'https://api.example.com/resource'
# リクエストボディ
data = {
"name": "John",
"email": "john@example.com"
}
# POSTリクエストの送信
response = requests.post(url, json=data)
# レスポンスの表示
print("ステータスコード:", response.status_code)
print("レスポンスボディ:", response.json())
```
このコードは、指定したURLに対してPOSTリクエストを送信し、レスポンスのステータスコードとボディを表示します。必要に応じて、エラーハンドリングや追加の処理を追加することもできます。GPT-4
Pythonで指定されたAPIエンドポイントにPOSTリクエストを送信し、レスポンスを表示するコードは以下のようになります。この例では`requests`ライブラリを使用しています。もし`requests`ライブラリがインストールされていない場合は、`pip install requests`を実行してください。
```python
import requests
# APIエンドポイントのURL
url = 'https://api.example.com/resource'
# 送信するデータ
data = {
"name": "John",
"email": "john@example.com"
}
# POSTリクエストを送信
response = requests.post(url, json=data)
# レスポンスのステータスコードと内容を表示
print("Status Code:", response.status_code)
print("Response:", response.json())
```
このコードは、指定されたURLに対してJSON形式のデータを含むPOSTリクエストを送信し、レスポンスのステータスコードと内容を表示します。サーバーからのレスポンスがJSON形式で返されることを想定しています。もし異なる形式でレスポンスが返される場合は、適宜`response.text`などを使用して内容を確認してください。3つのモデルの出力を比較すると、どれも基本的には問題なく動作する正しいコードを生成できています。
しかし、GPT-4oのみjsonをインポートしていますが、コード内でjson=payloadと指定しているので、これは不要です。
このように、比較的簡単なコード生成タスクでは3つのモデルに差はほぼ出ないことがわかります。
さらには、逆に高性能なモデルが余計な処理を追加してしまうことがあるので、タスクの難易度に合わせた最適なモデルを選択することも重要です。
コードレビュー、デバッグ
コードレビューとデバッグは、高品質なソフトウェア開発において不可欠なプロセスです。
3つのモデルの性能を評価するため、テキストファイル処理とデータ集計を行うPythonコードのレビューとデバッグタスクを実施しました。
プロンプト
以下のコードをレビューして、問題点があれば指摘して修正して
```python
import os
def read_file(file_path):
try:
with open(file_path, 'r') as file:
lines = file.readlines()
return lines
except FileNotFoundError:
print(f"Error: The file at {file_path} was not found.")
return []
except Exception as e:
print(f"Error: An unexpected error occurred: {e}")
return []
def process_data(lines):
word_count = {}
for line in lines:
words = line.split()
for word in words:
word = word.lower().strip('.,!?')
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
return word_count
def save_results(word_count, output_file):
try:
with open(output_file, 'w') as file:
for word, count in sorted(word_count.items(), key=lambda item: item[1], reverse=True):
file.write(f"{word}: {count}\n")
print(f"Results saved to {output_file}")
except IOError as e:
print(f"Error: Could not write to file {output_file}: {e}")
def main():
file_path = "input.txt"
output_file = "output.txt"
if not os.path.exists(file_path):
print(f"Error: {file_path} does not exist.")
return
lines = read_file(file_path)
if lines:
word_count = process_data(lines)
save_results(word_count, output_file)
if __name__ == "__main__":
main()
```出力結果は以下のとおりです。
GPT-4o
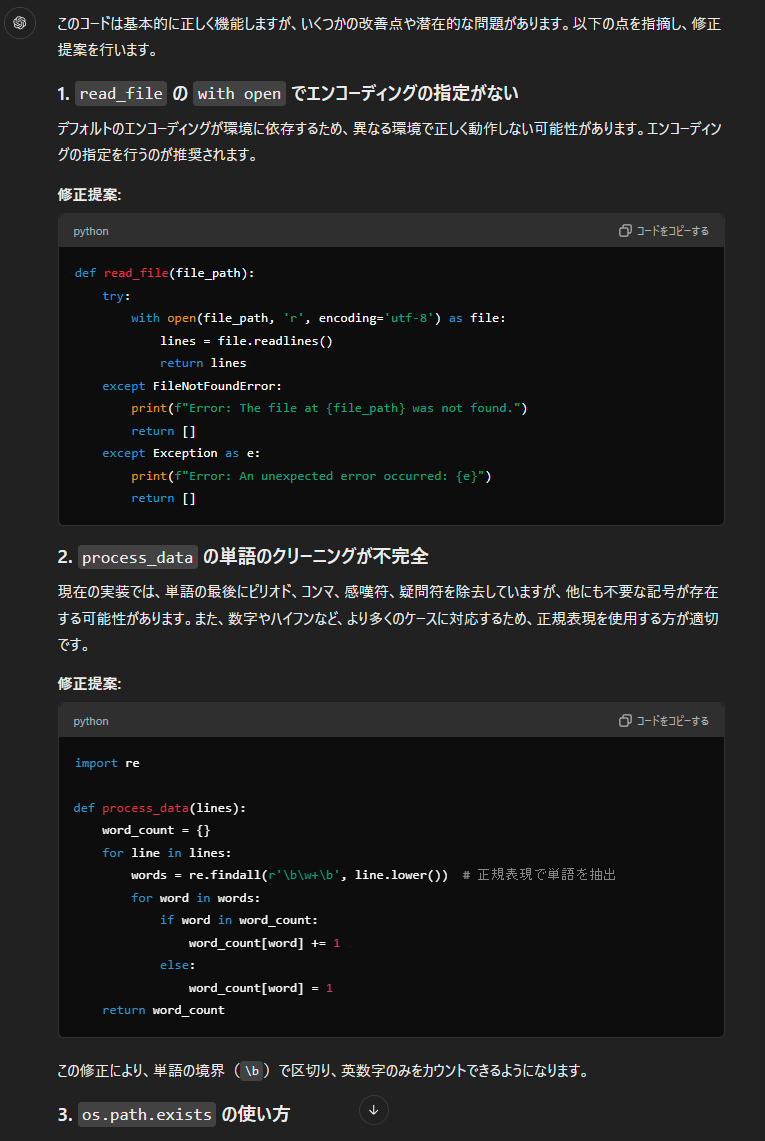
このコードは基本的に正しく機能しますが、いくつかの改善点や潜在的な問題があります。以下の点を指摘し、修正提案を行います。
### 1. `read_file` の `with open` でエンコーディングの指定がない
デフォルトのエンコーディングが環境に依存するため、異なる環境で正しく動作しない可能性があります。エンコーディングの指定を行うのが推奨されます。
#### 修正提案:
```python
def read_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
return lines
except FileNotFoundError:
print(f"Error: The file at {file_path} was not found.")
return []
except Exception as e:
print(f"Error: An unexpected error occurred: {e}")
return []
```
### 2. `process_data` の単語のクリーニングが不完全
現在の実装では、単語の最後にピリオド、コンマ、感嘆符、疑問符を除去していますが、他にも不要な記号が存在する可能性があります。また、数字やハイフンなど、より多くのケースに対応するため、正規表現を使用する方が適切です。
#### 修正提案:
```python
import re
def process_data(lines):
word_count = {}
for line in lines:
words = re.findall(r'\b\w+\b', line.lower()) # 正規表現で単語を抽出
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
return word_count
```
この修正により、単語の境界(`\b`)で区切り、英数字のみをカウントできるようになります。
### 3. `os.path.exists` の使い方
`main` 関数内でファイルが存在するかをチェックしていますが、既に `read_file` 関数内で `FileNotFoundError` の例外処理をしているため、二重にチェックする必要はありません。
#### 修正提案:
`main` 関数内の `os.path.exists` チェックは削除しても良いです。
```python
def main():
file_path = "input.txt"
output_file = "output.txt"
lines = read_file(file_path)
if lines:
word_count = process_data(lines)
save_results(word_count, output_file)
```
### 4. `save_results` のエンコーディングも明示する
読み込み時と同様に、書き込み時にもエンコーディングを指定するのが望ましいです。
#### 修正提案:
```python
def save_results(word_count, output_file):
try:
with open(output_file, 'w', encoding='utf-8') as file:
for word, count in sorted(word_count.items(), key=lambda item: item[1], reverse=True):
file.write(f"{word}: {count}\n")
print(f"Results saved to {output_file}")
except IOError as e:
print(f"Error: Could not write to file {output_file}: {e}")
```
### 最終コード:
```python
import os
import re
def read_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
return lines
except FileNotFoundError:
print(f"Error: The file at {file_path} was not found.")
return []
except Exception as e:
print(f"Error: An unexpected error occurred: {e}")
return []
def process_data(lines):
word_count = {}
for line in lines:
words = re.findall(r'\b\w+\b', line.lower()) # 正規表現で単語を抽出
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
return word_count
def save_results(word_count, output_file):
try:
with open(output_file, 'w', encoding='utf-8') as file:
for word, count in sorted(word_count.items(), key=lambda item: item[1], reverse=True):
file.write(f"{word}: {count}\n")
print(f"Results saved to {output_file}")
except IOError as e:
print(f"Error: Could not write to file {output_file}: {e}")
def main():
file_path = "input.txt"
output_file = "output.txt"
lines = read_file(file_path)
if lines:
word_count = process_data(lines)
save_results(word_count, output_file)
if __name__ == "__main__":
main()
```
この修正版は、エンコーディングの明示と、正規表現による単語処理の強化を行い、全体の安定性と堅牢性が向上しています。GPT-4o mini
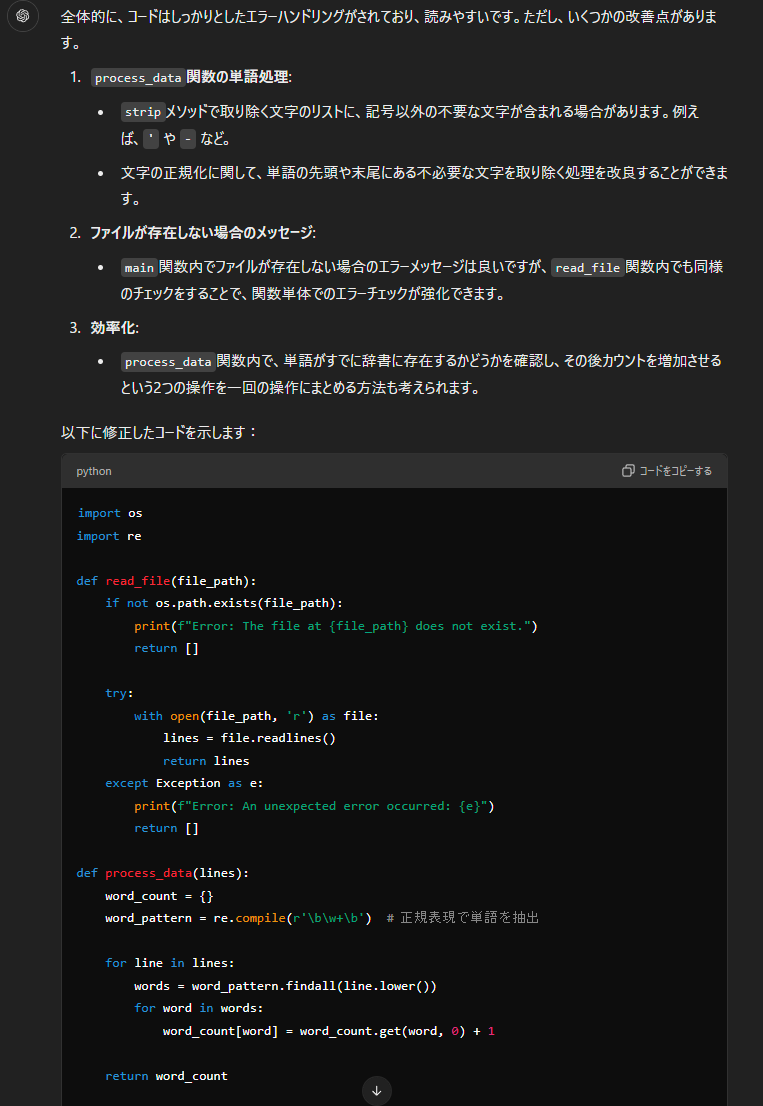
全体的に、コードはしっかりとしたエラーハンドリングがされており、読みやすいです。ただし、いくつかの改善点があります。
1. **`process_data`関数の単語処理**:
- `strip`メソッドで取り除く文字のリストに、記号以外の不要な文字が含まれる場合があります。例えば、`'` や `-` など。
- 文字の正規化に関して、単語の先頭や末尾にある不必要な文字を取り除く処理を改良することができます。
2. **ファイルが存在しない場合のメッセージ**:
- `main`関数内でファイルが存在しない場合のエラーメッセージは良いですが、`read_file`関数内でも同様のチェックをすることで、関数単体でのエラーチェックが強化できます。
3. **効率化**:
- `process_data`関数内で、単語がすでに辞書に存在するかどうかを確認し、その後カウントを増加させるという2つの操作を一回の操作にまとめる方法も考えられます。
以下に修正したコードを示します:
```python
import os
import re
def read_file(file_path):
if not os.path.exists(file_path):
print(f"Error: The file at {file_path} does not exist.")
return []
try:
with open(file_path, 'r') as file:
lines = file.readlines()
return lines
except Exception as e:
print(f"Error: An unexpected error occurred: {e}")
return []
def process_data(lines):
word_count = {}
word_pattern = re.compile(r'\b\w+\b') # 正規表現で単語を抽出
for line in lines:
words = word_pattern.findall(line.lower())
for word in words:
word_count[word] = word_count.get(word, 0) + 1
return word_count
def save_results(word_count, output_file):
try:
with open(output_file, 'w') as file:
for word, count in sorted(word_count.items(), key=lambda item: item[1], reverse=True):
file.write(f"{word}: {count}\n")
print(f"Results saved to {output_file}")
except IOError as e:
print(f"Error: Could not write to file {output_file}: {e}")
def main():
file_path = "input.txt"
output_file = "output.txt"
lines = read_file(file_path)
if lines:
word_count = process_data(lines)
save_results(word_count, output_file)
if __name__ == "__main__":
main()
```
### 主な修正点
1. **ファイルの存在チェックを`read_file`内に移動**:
- ファイルが存在しない場合のエラーチェックを`read_file`関数に組み込みました。これにより、ファイル読み込みが失敗する原因が分かりやすくなります。
2. **正規表現を使った単語抽出**:
- 単語抽出に`re`モジュールを使い、単語の取り扱いをより正確にしました。
3. **`word_count.get`メソッドを使用**:
- 単語のカウントを更新する際に、`get`メソッドを使うことでコードを簡潔にしました。
これで、コードの効率と可読性が向上し、エラー処理も強化されています。GPT-4
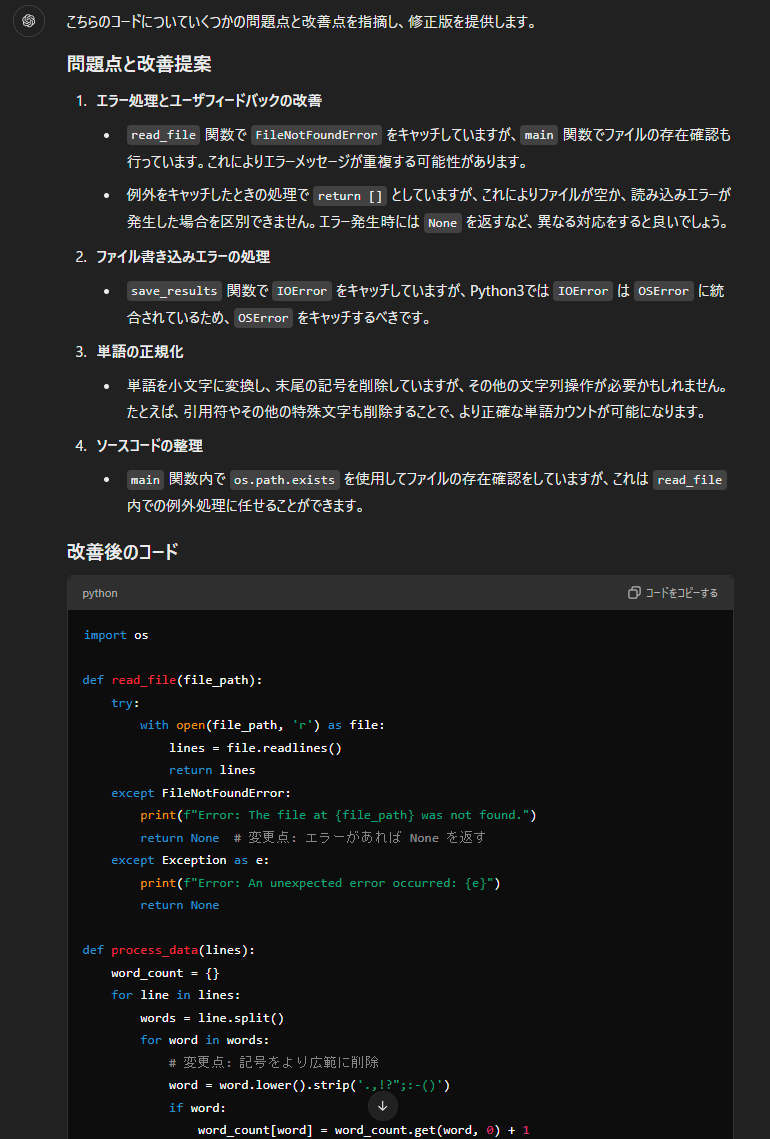
こちらのコードについていくつかの問題点と改善点を指摘し、修正版を提供します。
### 問題点と改善提案
1. **エラー処理とユーザフィードバックの改善**
- `read_file` 関数で `FileNotFoundError` をキャッチしていますが、`main` 関数でファイルの存在確認も行っています。これによりエラーメッセージが重複する可能性があります。
- 例外をキャッチしたときの処理で `return []` としていますが、これによりファイルが空か、読み込みエラーが発生した場合を区別できません。エラー発生時には `None` を返すなど、異なる対応をすると良いでしょう。
2. **ファイル書き込みエラーの処理**
- `save_results` 関数で `IOError` をキャッチしていますが、Python3では `IOError` は `OSError` に統合されているため、`OSError` をキャッチするべきです。
3. **単語の正規化**
- 単語を小文字に変換し、末尾の記号を削除していますが、その他の文字列操作が必要かもしれません。たとえば、引用符やその他の特殊文字も削除することで、より正確な単語カウントが可能になります。
4. **ソースコードの整理**
- `main` 関数内で `os.path.exists` を使用してファイルの存在確認をしていますが、これは `read_file` 内での例外処理に任せることができます。
### 改善後のコード
```python
import os
def read_file(file_path):
try:
with open(file_path, 'r') as file:
lines = file.readlines()
return lines
except FileNotFoundError:
print(f"Error: The file at {file_path} was not found.")
return None # 変更点: エラーがあれば None を返す
except Exception as e:
print(f"Error: An unexpected error occurred: {e}")
return None
def process_data(lines):
word_count = {}
for line in lines:
words = line.split()
for word in words:
# 変更点: 記号をより広範に削除
word = word.lower().strip('.,!?";:-()')
if word:
word_count[word] = word_count.get(word, 0) + 1
return word_count
def save_results(word_count, output_file):
try:
with open(output_file, 'w') as file:
for word, count in sorted(word_count.items(), key=lambda item: item[1], reverse=True):
file.write(f"{word}: {count}\n")
print(f"Results saved to {output_file}")
except OSError as e: # 変更点: IOError を OSError に変更
print(f"Error: Could not write to file {output_file}: {e}")
def main():
file_path = "input.txt"
output_file = "output.txt"
lines = read_file(file_path)
if lines is None:
return # 変更点: エラーがあれば処理を終了
if lines:
word_count = process_data(lines)
save_results(word_count, output_file)
if __name__ == "__main__":
main()
```
この修正により、エラー処理が改善され、コードの冗長性が低減されます。また、より多くの文字を削除して単語を正規化することで、単語カウントの精度が向上します。これらのレビュー、デバッグ結果をGPT-4oに順位をつけてもらうとこのような結果になりました。
これらの3つのモデル(GPT-4o、GPT-4o mini、GPT-4)のコードレビュー結果を比較し、順位付けしました。
評価基準
正確性:コードの問題点を的確に指摘し、改善方法を提案できているか。
改善の質:提案された修正が合理的で、コードのパフォーマンスや可読性を向上させるか。
効率性:改善提案が過剰ではなく、必要な箇所に対して適切に行われているか。
順位と解説
1位: GPT-4
理由:
正確なエンコーディングの指摘: ファイルの読み書き時にエンコーディングの指定がないことを的確に指摘し、修正提案でencoding='utf-8'を追加している点が優れています。
正規表現の利用: process_dataで単語処理を強化するために正規表現を導入しており、クリーニングの質を向上させています。
冗長なファイル存在チェックの改善: main関数内の冗長なファイル存在チェックを削除し、効率的なエラーハンドリングを提案しています。
OSErrorの正しい使用: Python 3で統合されたOSErrorを使用しており、最新のベストプラクティスを反映しています。
2位: GPT-4o
理由:
適切な改善提案: 正規表現を使用して単語のクリーニングを効率化し、word_count.getを利用して簡潔にカウント処理を行う方法を提案しています。
エラーハンドリングの強化: read_file内でファイルの存在確認を行うなど、関数単位でのエラーチェックを強化しています。
改善点の的確さ: 効率性とコードの冗長性を考慮した修正が行われており、全体的にバランスの取れた改善がなされています。
3位: GPT-4o mini
理由:
冗長な改善: read_file関数内でNoneを返す方法は合理的ですが、他のモデルと比べてより多くの冗長なチェックが追加されており、改善としては過剰な部分があります。
OSErrorの指摘: IOErrorからOSErrorへの変更を正しく指摘していますが、それ以外の改善提案が他のモデルに比べてやや単純で、コード全体の質向上に関わるポイントが少なかったです。
総合順位:
GPT-4
GPT-4o
GPT-4o mini
GPT-4は最も正確で深い改善提案を行い、他のモデルに比べて全体的なコードの品質向上に貢献しています。この結果から、コードレビューやデバッグにはGPT-4oやGPT-4といった高性能なモデルを使用することで、より良い結果を得られることがわかります。
ChatGPTを用いたコードレビューについては以下の記事でも詳しく解説しています。
関連記事:ChatGPTでコードレビューを効率化!導入方法とメリット、注意点を解説!
PythonからJavaへの翻訳
プログラミング言語の言語間翻訳は、多くのプロジェクトで発生する可能性があるタスクです。
ChatGPTは、既存のコードを新しい言語に移植する際や、複数の言語を使用するプロジェクトでの作業効率を向上させる際に有用です。
3つのモデルの翻訳性能を評価するため、Pythonで書かれた「フィボナッチ数列を再帰とメモ化を使用して効率的に計算するプログラム」をJavaに翻訳します。
プロンプト
次のPythonコードをJavaに翻訳してください。Javaの標準ライブラリや適切なクラスを使用し、Pythonの再帰やメモ化ロジックをJavaに置き換えてください。また、Javaのコーディングスタイルに従い、クラス名や変数名を適切に変更してください。
class Fibonacci:
def __init__(self):
self.memo = {}
def fib(self, n):
if n in self.memo:
return self.memo[n]
if n <= 1:
return n
self.memo[n] = self.fib(n - 1) + self.fib(n - 2)
return self.memo[n]
fib_calculator = Fibonacci()
print(fib_calculator.fib(10)) # 出力: 55出力結果は以下のとおりです。
GPT-4o
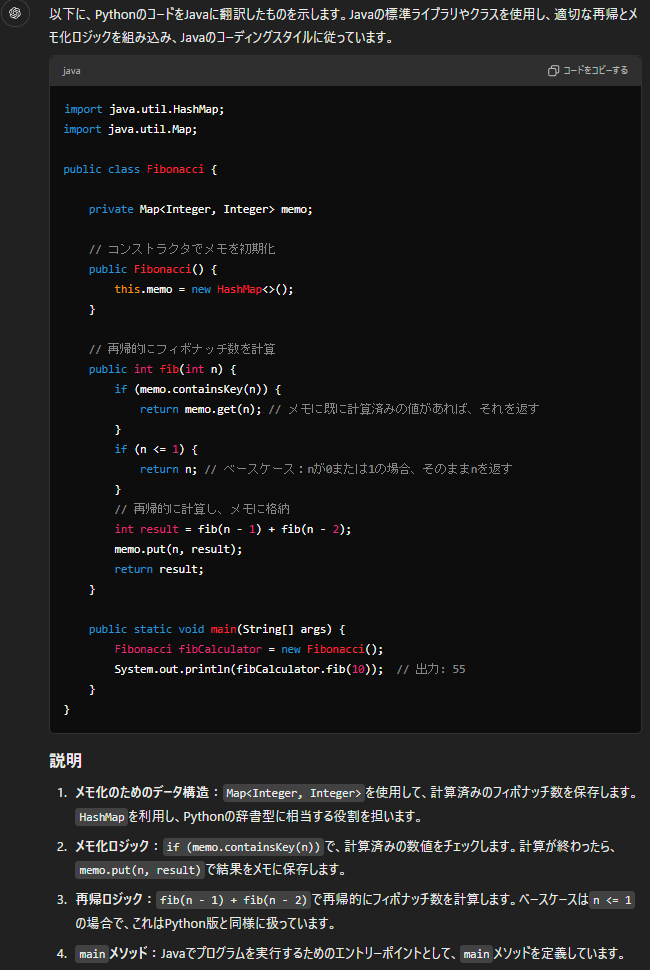
以下に、PythonのコードをJavaに翻訳したものを示します。Javaの標準ライブラリやクラスを使用し、適切な再帰とメモ化ロジックを組み込み、Javaのコーディングスタイルに従っています。
```java
import java.util.HashMap;
import java.util.Map;
public class Fibonacci {
private Map<Integer, Integer> memo;
// コンストラクタでメモを初期化
public Fibonacci() {
this.memo = new HashMap<>();
}
// 再帰的にフィボナッチ数を計算
public int fib(int n) {
if (memo.containsKey(n)) {
return memo.get(n); // メモに既に計算済みの値があれば、それを返す
}
if (n <= 1) {
return n; // ベースケース:nが0または1の場合、そのままnを返す
}
// 再帰的に計算し、メモに格納
int result = fib(n - 1) + fib(n - 2);
memo.put(n, result);
return result;
}
public static void main(String[] args) {
Fibonacci fibCalculator = new Fibonacci();
System.out.println(fibCalculator.fib(10)); // 出力: 55
}
}
```
### 説明
1. **メモ化のためのデータ構造**:`Map<Integer, Integer>`を使用して、計算済みのフィボナッチ数を保存します。`HashMap`を利用し、Pythonの辞書型に相当する役割を担います。
2. **メモ化ロジック**:`if (memo.containsKey(n))`で、計算済みの数値をチェックします。計算が終わったら、`memo.put(n, result)`で結果をメモに保存します。
3. **再帰ロジック**:`fib(n - 1) + fib(n - 2)`で再帰的にフィボナッチ数を計算します。ベースケースは`n <= 1`の場合で、これはPython版と同様に扱っています。
4. **`main`メソッド**:Javaでプログラムを実行するためのエントリーポイントとして、`main`メソッドを定義しています。GPT-4o mini
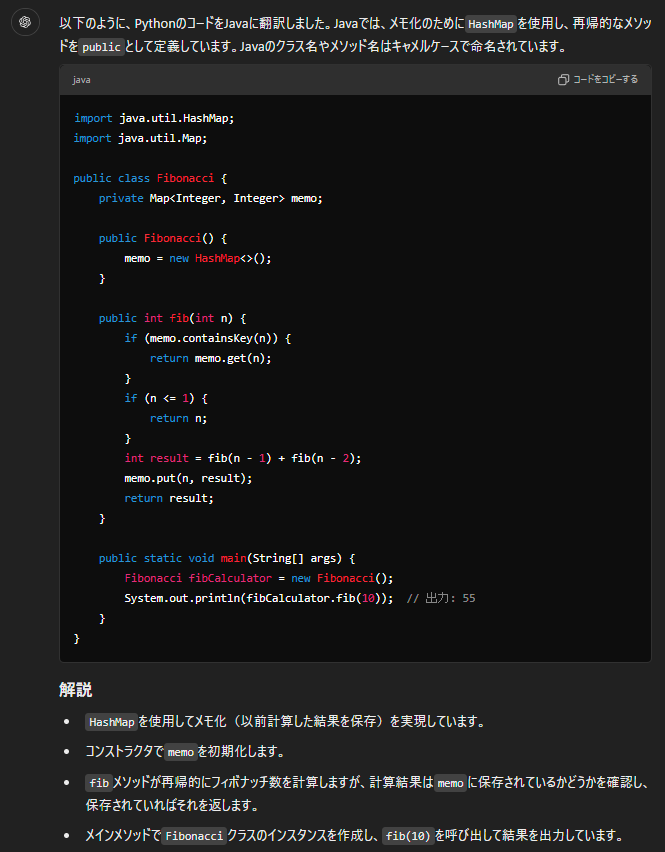
以下のように、PythonのコードをJavaに翻訳しました。Javaでは、メモ化のために`HashMap`を使用し、再帰的なメソッドを`public`として定義しています。Javaのクラス名やメソッド名はキャメルケースで命名されています。
```java
import java.util.HashMap;
import java.util.Map;
public class Fibonacci {
private Map<Integer, Integer> memo;
public Fibonacci() {
memo = new HashMap<>();
}
public int fib(int n) {
if (memo.containsKey(n)) {
return memo.get(n);
}
if (n <= 1) {
return n;
}
int result = fib(n - 1) + fib(n - 2);
memo.put(n, result);
return result;
}
public static void main(String[] args) {
Fibonacci fibCalculator = new Fibonacci();
System.out.println(fibCalculator.fib(10)); // 出力: 55
}
}
```
### 解説
- `HashMap`を使用してメモ化(以前計算した結果を保存)を実現しています。
- コンストラクタで`memo`を初期化します。
- `fib`メソッドが再帰的にフィボナッチ数を計算しますが、計算結果は`memo`に保存されているかどうかを確認し、保存されていればそれを返します。
- メインメソッドで`Fibonacci`クラスのインスタンスを作成し、`fib(10)`を呼び出して結果を出力しています。GPT-4
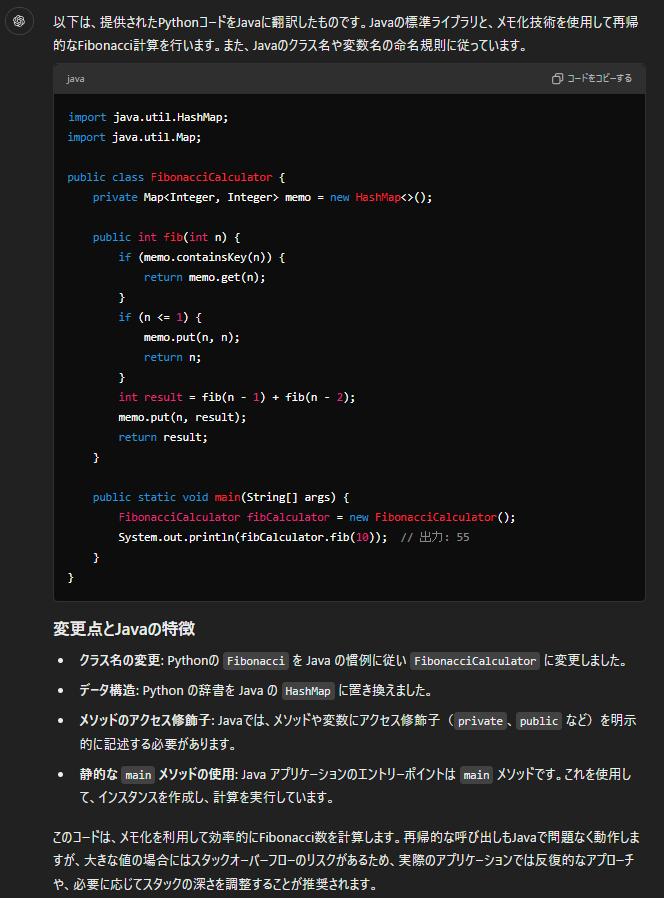
以下は、提供されたPythonコードをJavaに翻訳したものです。Javaの標準ライブラリと、メモ化技術を使用して再帰的なFibonacci計算を行います。また、Javaのクラス名や変数名の命名規則に従っています。
```java
import java.util.HashMap;
import java.util.Map;
public class FibonacciCalculator {
private Map<Integer, Integer> memo = new HashMap<>();
public int fib(int n) {
if (memo.containsKey(n)) {
return memo.get(n);
}
if (n <= 1) {
memo.put(n, n);
return n;
}
int result = fib(n - 1) + fib(n - 2);
memo.put(n, result);
return result;
}
public static void main(String[] args) {
FibonacciCalculator fibCalculator = new FibonacciCalculator();
System.out.println(fibCalculator.fib(10)); // 出力: 55
}
}
```
### 変更点とJavaの特徴
- **クラス名の変更**: Pythonの `Fibonacci` を Java の慣例に従い `FibonacciCalculator` に変更しました。
- **データ構造**: Python の辞書を Java の `HashMap` に置き換えました。
- **メソッドのアクセス修飾子**: Javaでは、メソッドや変数にアクセス修飾子(`private`、`public` など)を明示的に記述する必要があります。
- **静的な `main` メソッドの使用**: Java アプリケーションのエントリーポイントは `main` メソッドです。これを使用して、インスタンスを作成し、計算を実行しています。
このコードは、メモ化を利用して効率的にFibonacci数を計算します。再帰的な呼び出しもJavaで問題なく動作しますが、大きな値の場合にはスタックオーバーフローのリスクがあるため、実際のアプリケーションでは反復的なアプローチや、必要に応じてスタックの深さを調整することが推奨されます。こちらも結果の評価をGPT-4oに行ってもらいました。
### 結果の順位付け
1. **GPT-4**
- **理由**: このバージョンの出力は非常に明確で、Javaの標準的なコーディングスタイルをしっかりと守りつつ、Pythonのロジックを正確に翻訳しています。
- **命名規則**や**クラス設計**はJavaの慣例に従っており、`Fibonacci`クラスの作成や`HashMap`の使用も適切です。
- **コードの説明**が非常に詳細であり、メモ化のロジックや再帰処理に対する解説もわかりやすく、Javaにおける各操作の目的が明確にされています。
- 翻訳の精度、効率性、Javaらしい記述が最も優れていたため、1位に選びました。
2. **GPT-4o**
- **理由**: このバージョンの翻訳も適切であり、再帰やメモ化ロジックを正確にJavaに移植しています。
- **メモ化**の実装や**クラスの作り方**も問題ありませんが、コード全体に関する説明がややシンプルで、他のバージョンに比べて詳細な解説が不足していました。
- それでも、コーディングスタイルや効率性は問題なく、正確に動作するコードであるため2位に選びました。
3. **GPT-4o mini**
- **理由**: このバージョンも正しくPythonのコードをJavaに翻訳していますが、いくつかの点で他の2つのバージョンよりも劣ります。
- **クラス名の命名**が`FibonacciCalculator`となっており、Javaの慣例としては少し過剰な命名規則に感じられました。他のバージョンが`Fibonacci`という簡潔なクラス名を採用しているのに対し、ここでは冗長になっています。
- **説明や解説の詳細さ**も他の2つに比べて簡潔すぎて、コードの意図が完全に理解されているか不安が残る部分がありました。
### 総評
- **GPT-4**は最も適切で詳細な翻訳と説明を提供しており、非常にJavaらしいコードに仕上げています。
- **GPT-4o**も同様に正確ですが、説明が少し足りない点で2位となりました。
- **GPT-4o mini**は動作には問題ないものの、命名や説明の点で他のバージョンにやや劣っていました。このように、GPT-4が最も高い評価を得ており、僅差でGPT-4oが2位です。
この結果から、コード翻訳タスクにおいては、シンプルなコードであってもGPT-4oやGPT-4といった高性能なモデルを使用することが重要だとわかります。
ChatGPTをプログラミングに活用する際の3つの注意点
ChatGPTはプログラミングにおいて強力なツールですが、その使用には注意が必要です。
ここでは、ChatGPTをプログラミングに活用する際に特に重要な以下の3つの注意点について詳しく説明します。
- 出力結果の検証
- 無断転載や著作権の問題
- セキュリティとプライバシーの考慮
出力結果の検証
ChatGPTが生成するコードは、必ずしも正確で最適なものとは限らないため、人間のエンジニアによる検証が必須です。
まず、生成されたコードがエラーなく動作するか、特にエッジケース(空の配列や特殊な入力)でも正しく動作するかを確認します。
さらに、コードのパフォーマンスも重要ですので、効率的なアルゴリズムが使われているか、リソース消費が多くないかを評価しましょう。
加えて、生成されたコードのスタイルや命名規則がプロジェクトや組織の基準に合致しているかを確認します。
ChatGPTは一般的な推奨手法に基づいて出力を生成しますが、特定のフレームワークやライブラリの制約には必ずしも対応していない場合があります。
そのため、ChatGPTによって出力された回答はプロジェクトに応じた調整が必要です。
また、技術的な説明や最新情報の正確性を確認し、信頼できる情報と照らし合わせることも重要です。
無断転載や著作権の問題
AIが生成するコードには、著作権や無断転載に関する問題が潜在的に含まれています。
ChatGPTが学習データにもとづいて生成するため、既存のオープンソースプロジェクトや著作権で保護されたコードに類似した部分が意図せず再現される可能性があります。
そのため、生成されたコードが有名なライブラリやアルゴリズムと酷似していないかを確認する必要があります。
また、ChatGPTが提供する情報やアイデアを使用する際には、適切に引用や帰属を行うことが推奨されます。
特に商用利用を考えている場合、OpenAIの利用規約を確認し、必要に応じて法的なアドバイスを求めることで、著作権やライセンスに関する問題を避けられます。
セキュリティとプライバシーの考慮
ChatGPTに対して送信するデータには機密性を重視する必要があります。
機密情報や個人情報、企業の重要なデータを含むコードをChatGPTに送信することは避けるべきです。
また、ChatGPTが生成するコードにもセキュリティ上の脆弱性が含まれている可能性があるため、特にユーザー入力の処理やデータベースクエリの構築には注意が必要です。
SQLインジェクションやクロスサイトスクリプティング(XSS)など、一般的なセキュリティ脆弱性に対する防御が実装されているかを確認しましょう。
さらに、暗号化や認証処理についても業界標準のガイドラインに従っているかを評価することが求められます。
プライバシーに関するリスクを回避するため、AIを活用する際にはデータの取り扱い方やセキュリティ監査を定期的に実施することが推奨されています。
ChatGPTの使い方をもっと知りたい方は、以下の記事で活用事例を参考になさってください。

ChatGPTでプログラミングをもっと効率的に!
ChatGPTを活用することで、コード生成からデバッグ、学習サポートまで、幅広い分野でプログラミングの効率を大幅に向上できます。
特に、基本的なコードの生成やエラー解決のサポートを受けることで、初期の開発プロセスが加速し、タスクの進行がスムーズになります。
また、技術的なアドバイスを通じて、チーム全体のスキル向上にも貢献できるため、より高度な問題解決に時間を割くことが可能になります。
こうした効率化により、プロジェクトの進行速度が向上し、納期の短縮やコスト削減にもつながるでしょう。
ただし、ChatGPTの活用には注意が必要です。
出力されたコードの正確性や適用性をしっかりと検証すること、著作権への配慮を忘れないこと、そしてセキュリティやプライバシーのリスクを常に考慮することが重要です。
最終的な判断は人間のエンジニアに委ねられるため、ChatGPTをツールとして適切に活用することが求められます。
このように、ChatGPTを効果的に活用して自身やチームのスキルを高め続けることで、個人だけでなく組織全体の業務効率を飛躍的に向上できます。
なお、ChatGPTを活用する以外にも業務効率化を進める方法はたくさんあり、それらをうまく組み合わせることで、さらなる業務効率化を目指せます。
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
30秒で簡単受取!
無料で今すぐもらう













30秒で簡単受取!
無料で今すぐもらう