share



【忙しい人向け】元OpenAI役員のイリヤ・サツケバー氏が厳選した論文集を全て解説!

イリヤ・サツケバー氏はAI分野で最も影響力のある研究者の一人です。
同氏が選んだ重要論文の理解を通して、AI技術の効率的な学習とキャリアアップが望めます。
AI技術の進歩は日々加速しており、キャリアアップにはAIへの理解が不可欠です。しかし、AI技術を学ぶ時間を確保するのは、なかなか難しいのではないでしょうか。
本記事では、イリヤ氏が厳選した論文の要点と応用状況を解説します。この記事を読めば、AI技術を効率的に学べるでしょう。

監修者
SHIFT AI代表 木内翔大
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
目次
イリヤ・サツケバー(Ilya Sutskever)氏とは?
イリヤ・サツケバー氏は深層学習の第一人者であり、OpenAIの共同創設者兼元チーフサイエンティストです。

イリヤ氏の研究は現代のAI技術の基盤を形成しました。たとえば、同氏が共同開発したAlexNetは画像認識の精度を飛躍的に向上させました。
2024年6月、氏は安全なAI開発を目指す新会社「Safe Superintelligence Inc.」を設立し注目を集めています。
同社はAIの安全性と倫理的利用を確保する新たなアプローチを提案しています。今後のAI技術の発展に大きな影響を与えることが予想され、その動向から目が離せません。
イリヤ・サツケバー氏が厳選した重要論文
イリヤ・サツケバー氏が厳選した論文集は、深層学習・画像処理・自然言語処理などAIの重要分野をカバーしています。同氏執筆の論文も収録されており、氏の研究方向性を示す貴重な資料といえます。
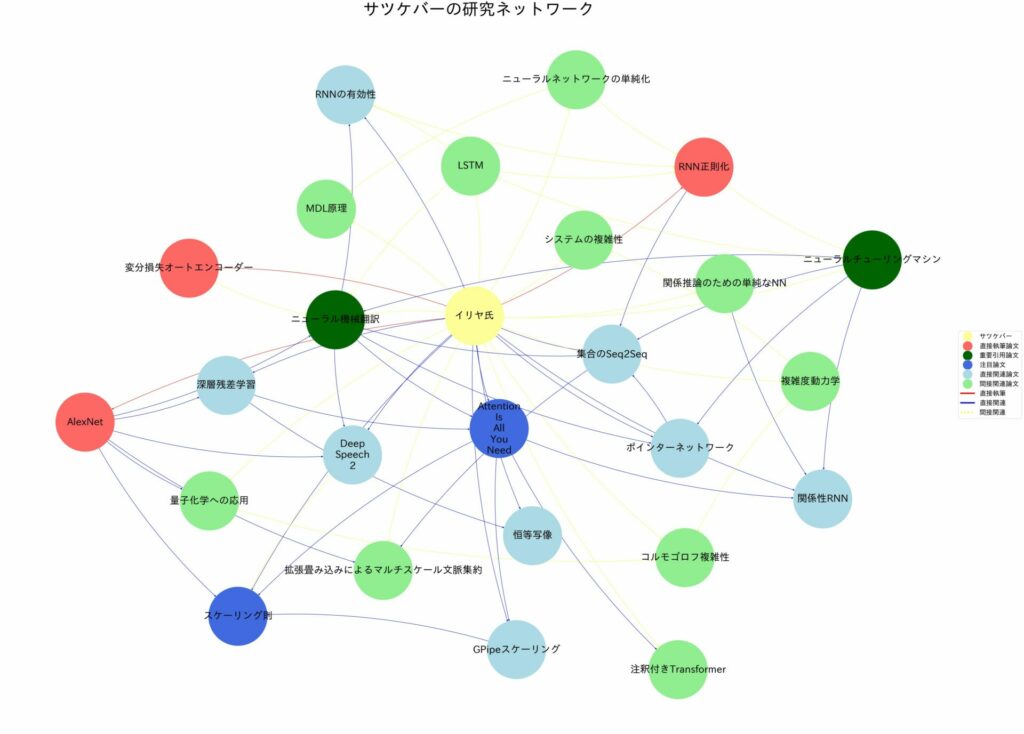
それぞれの論文について詳しくご紹介します。
なお、「論文の内容を解説されても知識がそもそもない」という方は、以下の記事で生成AIの勉強を始めてみましょう。

Keeping Neural Networks Simple by Minimizing the Description Length of the Weights
本研究は、ネットワークの重みの記述長を最小化し、単純化を図っています。ニューラルネットワークは、人間の脳を模倣した機械学習モデルで、多数の計算ユニット(ニューロン)が互いに接続されています。
各接続の「重み」は、学習過程で調整されることでデータから正しい出力を生成します。「記述長」はモデルの複雑さを表す指標です。ニューラルネットワークは、重みをシンプルに保つことで応用力が上がります。
従来のニューラルネットワークは複雑化しやすく、過学習※1の問題がありました。
研究チームは以下の手法を開発しました。
- 重みにガウスノイズ※2を加える
- 情報量と予測誤差のバランスを最適化する
この手法により、少ない訓練データでも高い汎化性能※3を実現しました。
本研究はニューラルネットワークの複雑さと性能のバランスを考える基礎となりました。応用分野は以下の通りです。
- モデル圧縮
- 正則化
- ニューラル構造探索
- 連合学習
- 説明可能AI
とくに、資源制約のある環境での深層学習モデル設計と最適化に貢献しています。
※1 モデルが学習データに過剰に適合し、未知データへの予測性能が低下すること
※2 正規分布に従う統計的雑音。過学習防止に効果あり
※3 未知データに対する予測能力
>この論文を詳しく読みたい方はこちらから
A Tutorial Introduction to the Minimum Description Length Principle
本研究は、MDL原理の基本概念、理論的基礎、実践的応用を包括的に解説しています。
ここで扱われている最小記述長(MDL)原理は、データ圧縮の考えを用いて最適なモデルを選択する方法です。

Minimum Description Length Principle
従来の統計的推論手法では、過学習※1の問題や複数モデルの比較が困難でした。
MDLの特徴は以下の通りです。
- 情報理論と統計学の融合
- データの規則性を圧縮能力と関連付け
- モデルの複雑さとデータ適合度のバランスを取り、過学習を防止
- 一貫性のある推定を提供
- 異なる複雑さをもつモデルの比較を可能に
MDL原理は、パターンマイニング、機械学習、データサイエンスに応用されています。
情報理論と統計学の重要概念として確立されていますが、大規模データへの適用など新たな課題もあります。
※1 モデルが学習データに過剰に適合し、未知データへの予測性能が低下すること
>この論文を詳しく読みたい方はこちらから
Machine Super Intelligence
Shane Legg氏の博士論文「Machine Super Intelligence」は、AGI※1の理論的基盤を築いた先駆的研究です。
本研究は、未知の計算可能環境下でのAIエージェントの最適行動を探求しています。
当時から、知能の本質、測定方法、超知能機械の可能性は重要な課題でした。
Legg氏の主な成果は以下の通りです。
- Solomonoffの帰納推論理論※2と意思決定理論を統合した「AIXI」モデルの提案
- 理論上最適な学習エージェントの設計の示唆
- 計算エージェントの限界や強力な知能の影響に関する考察
2011年にLegg氏と対談したイリヤ氏は、2024年に安全な超知能AI開発を目指す新会社を設立しました。
AGI研究の進展に伴い、ASI※3の実現可能性や影響について、倫理的課題を含む国際的議論が進行中です。
※1 人間のように汎用的な問題解決能力を持つAI
※2 データから最も単純な説明を見つけ出す理論的枠組み
※3 人間の知能を超えるAI
>この論文を詳しく読みたい方はこちらから
The First Law of Complexodynamics
Scott Aaronsonの「The First Law of Complexodynamics(複雑度動力学の第一法則)」は、物理システムの複雑さの時間変化に関する仮説を提案しています。
研究の出発点は以下の疑問でした。
「エントロピー※1が増加し続けるのに、複雑さや興味深さが中間で最大になるのはなぜか」

考察の結果は以下の通りです。
- コルモゴロフ複雑性※の「洗練度」概念を応用
- 計算資源制限付きの新しい複雑さの尺度、「complextropy(コンプレクストロピー)」※2を提案
- 物理系の複雑さの時間的変化(増加、ピーク、減少)を説明
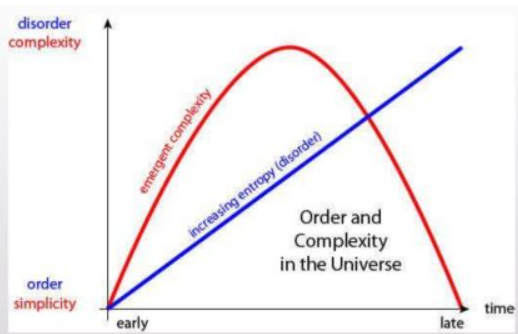
この理論は、複雑系の時間発展を理解する上で興味深いアプローチを提供しています。普遍的には受け入れられていませんが、重要な議論の出発点となっていると評価されています。
※1データの本質的な複雑さを測る理論的な概念
※2 複雑さとエントロピーを組み合わせた造語。システムの複雑さを新たな視点で捉える概念
>この記事を詳しく読みたい方はこちらから
Neural Machine Translation by Jointly Learning to Align and Translate
本研究は、イリヤ氏らが提案したSequence to Sequence学習※1を基礎とし、その限界を克服しています。研究で取り上げているRNNsearchは、双方向RNN※2とアテンションメカニズム※3を用いて、長文翻訳の性能を大幅に向上させました。機械翻訳分野で25,000回以上引用された重要な研究です。
イリヤ氏のモデルは固定長ベクトルを用いた翻訳の基礎を築きましたが、長文に課題がありました。
RNNsearchの特徴と成果は以下の通りです。
- 双方向RNNとアテンションメカニズムの組み合わせによる問題解決
- 従来モデル以上の性能発揮、特に長文での高品質翻訳の実現
- ソフトアラインメント※4による言語学的に適切な単語対応付けの実現
本研究は、現在のTransformerやBERTなど最新モデルの基礎となっています。アテンションメカニズムは機械翻訳以外の自然言語処理タスクでも重要な要素として活用されています。
※1 入出力が系列データの機械学習モデル
※2 入力を前後両方向から処理し、文脈をより深く理解するRNN(再帰型ニューラルネットワーク)
※3 入力の重要部分に注目し、長文でも効果的に情報を利用する仕組み
※4 入出力の単語間対応を確率的に表現し、自然な翻訳を実現する手法
>この論文を詳しく読みたい方はこちらから
Neural Turing Machine
本研究は、Neural Turing Machine(NTM)による外部メモリの利用と複雑なタスクの効率的学習・実行を探求しています。NTMは、外部メモリを持つニューラルネットワークで、従来モデルを超える学習能力を実現しました。
従来のニューラルネットワークは、データの長期保持や複雑なメモリ操作に課題がありました。
NTMの主な成果は以下の通りです。
- 外部メモリの活用による高度なデータ処理能力の実現
- LSTM※1より迅速かつ正確なタスク学習
- 長いシーケンスでの性能維持(LSTMは20文字超で急速に性能低下)
- 内容ベースと位置ベースのアドレッシング※2による効率的なメモリアクセスの実現
NTMは自然言語処理、アルゴリズム学習、ロボット制御など幅広い分野に応用されてきました。
現在はTransformerなどのより高度なアーキテクチャに置き換わりつつありますが、メモリ拡張型ニューラルネットワークの基礎として評価されています。
※1 長期的な依存関係を学習できるRNNの一種
※2 内容や位置に基づきメモリ内の特定位置にアクセスする方法
>この論文を詳しく読みたい方はこちらから
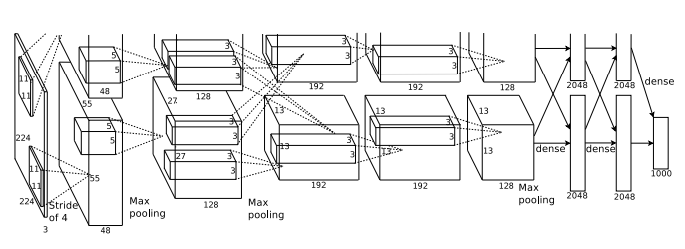
ImageNet Classification with Deep Convolutional Neural Networks
本研究は、120万枚の画像を1000クラスに分類する大規模なCNN※1の開発に関するものです。2012年にイリヤ氏らが発表したAlexNetは、CNNを応用して画像認識精度を大幅に向上させ、コンピュータビジョンに変革をもたらしました。
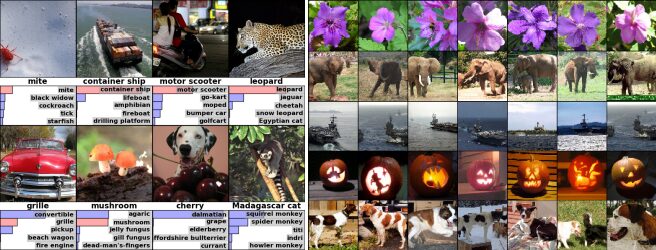
当時、画像認識の精度向上には膨大なデータと強力なモデルが必要でしたが、既存技術には限界がありました。
研究チームの成果は以下の通りです。
- 8層のCNNであるAlexNetの開発
- ReLU※2やドロップアウト※3などの新技術の導入
- GPU※4を活用した学習の高速化
- ImageNetデータセットで従来の最高精度を上回り、ILSVRC-2012コンテストで優勝
Neural Networks
AlexNetの成功は、イリヤ氏のキャリアの重要な転換点となりました。この成果が、Google Brainでの活躍やOpenAIの共同創設へと道を開いたのです。
一方、AlexNetの影響は個人のキャリアにとどまりませんでした。医療診断、自動運転、セキュリティシステムなど、その応用範囲は広がりました。
2024年現在、より高度なモデルに置き換わっていますが、深層学習の基礎を築いた功績は高く評価されています。
※1 画像認識に特化したニューラルネットワーク
※2 学習を高速化する活性化関数
※3 過学習を防ぐ手法
※4 ニューラルネットワークの学習を高速化する演算装置
>この論文を詳しく読みたい方はこちらから
Quantifying the Rise and Fall of Complexity in Closed Systems:The Coffee Automaton
本研究は、物理システムの複雑性を数値化する手法を提案しています。コーヒーとクリームの混合をモデル化したセルオートマトン※1が、閉鎖系の複雑性変化を解明する鍵となりました。
従来、閉鎖系のエントロピー増加※2は理解されていましたが、複雑性の時間変化は不明でした。
研究の主な発見は以下の通りです。
- 「見かけの複雑性」※3という新しい指標の導入
- エントロピーの単調増加と複雑性の上昇後低下パターンの観察
- コーヒーとクリームの混合過程における複雑性変化の説明
- 相互作用モデルでの複雑性最大値とシステムサイズの比例関係の確認
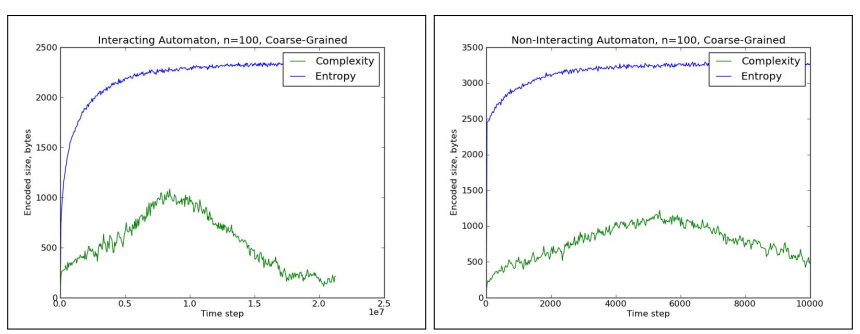
The Coffee Automaton
コーヒーとクリームの混合過程を以下に記載します。
- 初期:分離状態でエントロピーと複雑性が低い
- 中間:混合が進み、エントロピーと複雑性が上昇
- 最終:完全混合でエントロピーは最大、複雑性は低下
この研究は複雑系科学の理論発展に貢献し、より高度な手法開発のきっかけとなりました。
※1 単純なルールで状態が変化する格子状のモデル
※2 システムの乱雑さが時間とともに増える現象
※3 システムの状態を記述するのに必要な情報量
>この論文を詳しく読みたい方はこちらから
The Unreasonable Effectiveness of Recurrent Neural Networks
本研究は、再帰型ニューラルネットワーク(RNN)※1の能力と応用可能性を新たな視点から探求したものです。RNNは、自然言語処理に重要な進展をもたらしました。
当初、RNNの訓練は困難とされていましたが、多くの研究者の努力によりその可能性が広がりました。
研究の主な成果は以下の通りです。
- RNNによる多様なテキスト生成
シェイクスピアの作品風の文章
プログラミングコード
Wikipedia記事風の文章 - RNNの内部メカニズムの可視化によるモデルの学習過程の解明

RNNはその後、自然言語処理・時系列分析・画像キャプション生成・音楽生成など幅広く応用されました。
現在、Transformerモデルに一部置き換えられていますが、エッジコンピューティングや長期的な系列データ処理での効率性が評価されています。
※1 現在の入力と過去の情報を組み合わせて処理を行い、時系列データや言語の長期的な関係性を学習・処理できる
>この論文を詳しく読みたい方はこちらから
Understanding LSTM Networks
本記事は、LSTM(Long Short-Term Memory)の構造と機能を詳細に解説し、その有効性を示すものです。LSTMは、長期記憶機能を持つAI技術で、AIの発展に大きく貢献しました。
従来のRNNは、長期的な情報の保持が困難でした。
LSTMの特徴と成果は以下の通りです。
- ゲート機構※1の導入による長期的な情報保持の実現
- 以下のタスクでの優れた性能
言語モデリング
音声認識
画像キャプション生成
LSTMは、時系列予測や異常検知などで重要な役割を果たすようになりました。
現在、自然言語処理ではTransformerが主流ですが、LSTMは限られたリソースでの応用に適しています。
※1 情報の流れを制御する仕組み。LSTMでは入力、忘却、出力の3種類のゲートを使用
>この記事を詳しく読みたい方はこちらから
Recurrent Neural Network Regularization
本研究は、RNNの正則化手法を提案したものです。イリヤ氏らの研究は、RNNの過学習問題を解決し、自然言語処理タスクの性能を大幅に向上させました。
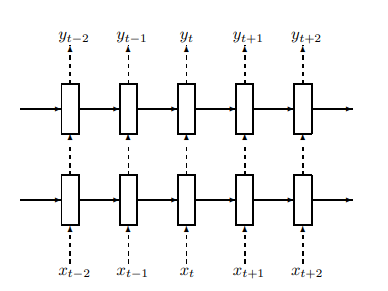
REGULARIZATION
RNNに、過学習を防ぐテクニック(ドロップアウト)を適用する方法を示している。点線の矢印がドロップアウトを適用する場所、実線の矢印が適用しない場所を表している。
RNNは自然言語処理や音声認識で使用されていましたが、過学習が起こりやすい課題がありました。
研究チームの成果は以下の通りです。
1. LSTMにドロップアウト※1を適切に適用
2. 以下のタスクで過学習を大幅に抑制:
| タスク | 結果 |
|---|---|
| 言語モデリング | Penn Treebankデータセット※2でパープレキシティ※3が78.4に改善 |
| 音声認識 | 英仏翻訳タスクでBLEUスコア※4が29.03に向上 |
| 画像キャプション | 単一モデルの性能がアンサンブルモデルと同等(BLEUスコア24.3) |
この研究は深層学習の発展に貢献し、現代のAIモデルにも応用されています。
※1 過学習を防ぐ手法
※2 言語モデリングで使用される標準的な英語テキストデータ
※3 言語モデルの性能評価指標。低いほど性能が高い
※4 機械翻訳の品質評価指標。0-100の範囲で、人間の翻訳に近いほど高スコア
>この論文を詳しく読みたい方はこちらから
Pointer Networks
この研究は、可変長の入出力を扱える深層学習モデルに関するものです。Pointer Networksは、入力シーケンスを指し示すニューラルネットワークを提案しました。
従来のモデルでは扱いが難しかった可変長データに対し、アテンションメカニズム※1を用いて入力データから出力を選択する手法を開発しました。
この手法は、以下の問題で有効性が実証されています。
| 用語 | 説明 |
|---|---|
| 平面凸包問題 | 平面上の点集合から、それらをすべて含む最小の凸多角形を見つける問題 |
| ドロネー三角分割 | 平面上の点集合を頂点とする三角形分割を行う手法 |
| 巡回セールスマン問題 | 複数の都市を1回ずつ訪問し、出発地点に戻る最短経路を見つける問題 |
Pointer Networksは、可変長データ処理の新たな可能性を示すとともに、アテンションの新しい使い方を提案しました。
この研究は自然言語処理や組合せ最適化の分野に重要な進展をもたらしました。現在では、進化したアルゴリズムとの統合や大規模問題への適用が進んでいます。
※1 入力データの重要な部分に注目する仕組み
>この論文を詳しく読みたい方はこちらから
Deep Residual Learning for Image Recognition
この研究は、非常に深いネットワークの学習を可能にする「残差学習」※1を提案しました。ResNet※2は深層ニューラルネットワークの学習を改善し、画像認識の性能を大幅に向上させました。
この研究は22万本以上の論文に引用されています。
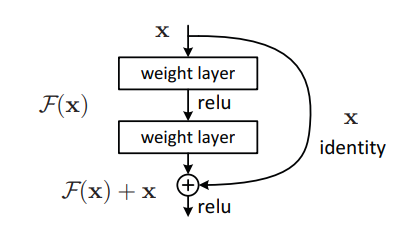
ResNetの基本構造。入力に残差を足し合わせることで、深いネットワークの学習を容易にする仕組みを表している
従来、層を深くすると学習が困難になり性能が低下していました。単純な層の積み重ねでは解決できなかったのです。
著者らの主な成果は以下の通りです。
- 層の入力を出力に直接つなぐショートカット接続の追加
- 152層の深いネットワーク(ResNet)の学習に成功
- 画像認識タスクで当時最高精度を達成
- ILSVRC 2015コンテストで優勝
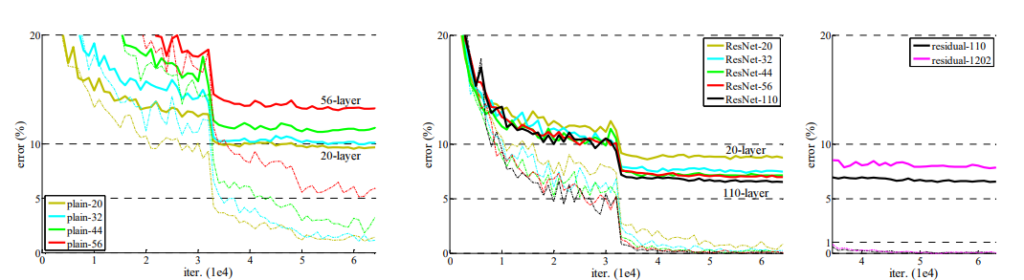
ResNetが通常のネットワークよりも深い層でも効果的に学習でき、100層以上の非常に深いネットワークでも安定して学習できることを示している
ResNetは画像認識、物体検出、画像生成など幅広く応用され、Transformerなど重要モデルの開発にも影響を与えています。
※1 層の入力を出力に直接つなぎ、深い層での学習を可能にする手法
※2 Residual Networkの略。残差学習を用いた深層ニューラルネットワーク
>この論文を詳しく読みたい方はこちらから
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS
この研究は、セマンティックセグメンテーション※1の課題に取り組んでいます。「コンテキストモジュール」と呼ばれる新しいネットワーク構造の開発により、画像の細部と全体を同時に理解する能力が向上したのです。

従来、高解像度を保ちながら広範囲の文脈情報を取り込むことは困難でした。
研究チームが開発した「コンテキストモジュール」の特徴は以下の通りです。
- 拡張畳み込み※2を活用し、解像度を落とさず多スケールの情報を集約
- 既存システムに組み込み可能
- 複数のデータセットで高い性能を実現
この技術は以下の分野で応用されています。
- 都市景観解析
- 医療画像診断
- 自動運転
被引用数は1万回を超え、DeepLabシリーズなど多くのモデルに影響を与えました。現在も、Transformerなどの新技術と組み合わせた研究が進められています。
※1 画像の各ピクセルにクラスラベルを割り当てる手法
※2 フィルタ内の要素間の間隔を拡大し、受容野を効率的に広げる手法
>この論文を読みたい方はこちらから
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
この研究では、深層学習を活用した高精度の音声認識システムを開発しています。音声認識技術「Deep Speech 2」が人間の能力を上回る精度を実現し、音声認識システムの進化を加速させました。
従来の音声認識システムは複雑な構造を持ち、処理効率が課題でした。
Deep Speech 2は、単一の深層ニューラルネットワークによる処理の効率化でこの問題を解決しました。大量のデータとGPU※1の活用でこれが可能になったのです。
主な成果は以下の通りです。
| タスク | 結果 |
|---|---|
| 英語音声認識 | 4つのテストのうち3つで人間を上回る性能を発揮 |
| 中国語音声認識 | 短い音声クエリの認識エラー率がシステム3.7%、人間4.0% |
| 騒音や異なるアクセント | 対応できる |
Deep Speech 2は、スマートスピーカーや自動字幕生成など幅広い分野で応用されました。現在一部の性能で新技術に追い抜かれていますが、音声認識技術の基礎を築いた重要な研究として評価されています。
※1 Graphics Processing Unit。画像処理に特化した演算装置で、深層学習の複雑な計算を高速化できる
>この論文を読みたい方はこちらから
ORDER MATTERS: SEQUENCE TO SEQUENCE FOR SETS
この論文は、sequence-to-sequence (seq2seq)※1モデルを、集合データに拡張する手法に関するものです。順序のない集合データを効果的に処理する新しい機械学習手法を提案し、従来モデルを上回る性能を実現しました。
当時、seq2seqモデルは自然言語処理など多くのタスクで成功を収めていました。しかし、集合のように順序構造を持たないデータを扱うことは困難でした。
研究チームは「Read-Process-and-Write」アーキテクチャと出力順序最適化アルゴリズムを開発しました。
実験では、以下のタスクで有効性を実証しています。
- 言語モデリング
- 構文解析
- 数字のソート
現在では、より高度なモデルが主流となっていますが、集合データ処理に関する着想は今なお重要な意味を持っています。
※1 入力系列から出力系列へのマッピングを学習するモデル。機械翻訳などに用いられた
>この論文を読みたい方はこちらから
Identity Mappings in Deep Residual Networks
この研究は、ResNetの残差ブロックにアイデンティティマッピング※1を導入し、より深いネットワークの学習を可能にしています。深層残差ネットワーク(ResNet)※2の性能を大幅に向上させる手法が提案されたのです。
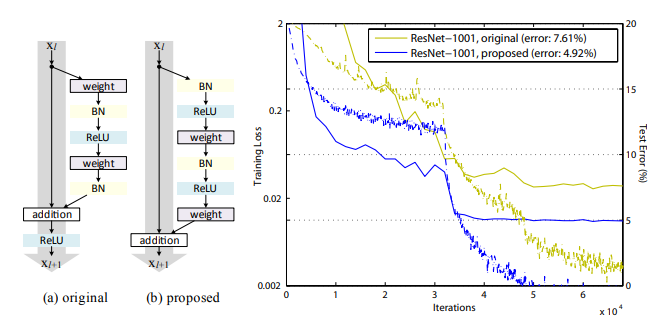
従来のResNetでは非常に深いネットワークの最適化が難しいという課題がありました。
残差ユニットの設計を改良し、情報の流れをスムーズにすることで、この問題を解決できたのです。
主な成果は以下の通りです。
- 1000層を超える非常に深いネットワークの学習が可能に
- 画像認識精度が大幅に向上
| タスク | 結果 |
|---|---|
CIFAR-10データセット | エラー率4.62%(ResNet-1001) |
CIFAR-100データセット | エラー率22.71%(ResNet-1001) |
ImageNetデータセット | Top-1エラー率20.1%、Top-5エラー率4.8%(ResNet-200) |
この技術は主に画像認識分野で広く使用され、医療分野などでも応用されるようになりました。非常に深いネットワークの安定した学習を実現し、DenseNetなど多くの後続研究の基礎となりました。
※1 入力をそのまま出力に渡す仕組み
※2 残差学習を用いた深層ニューラルネットワーク
>この論文を読みたい方はこちらから
Neural Message Passing for Quantum Chemistry
この研究は、分子の量子化学的特性を予測する新しい機械学習手法を提案しています。著者らは Message Passing Neural Networks (MPNNs) と呼ばれるグラフニューラルネットワークモデルを開発し、分子構造から直接特性を学習させました。MPNNsは従来手法を大きく上回る精度で量子化学計算を近似したのです。
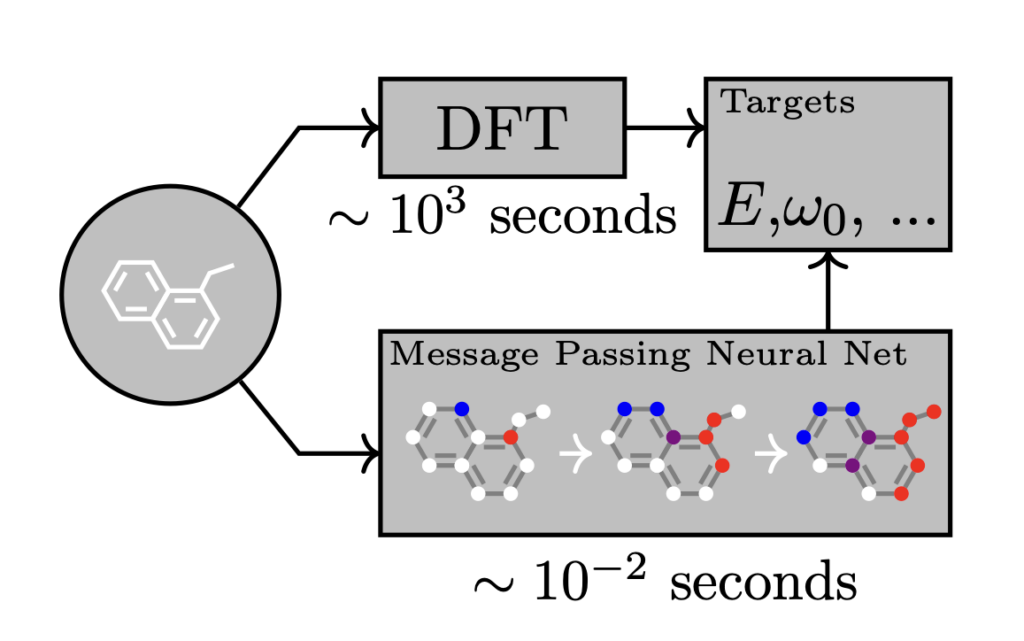
従来の手法では、分子の対称性を考慮した特徴量設計が課題でした。
MPNNsはこの問題を解決し、分子の構造をより適切に表現できるようになりました。
研究の主な成果は以下の通りです。
- 13種類の分子特性すべてで最先端の性能を示す
- そのうち11種で化学的精度を達成
- 空間情報を追加せずに、5種の特性で化学的精度を達成
技術は量子化学、創薬、材料科学など幅広い分野で応用されています。後続のグラフニューラルネットワーク研究を促進し、分子グラフ表現学習の分野で高く評価されています。
※1 点(ノード)と線(エッジ)で表現されるデータ構造。分子では原子がノード、結合がエッジに対応します
※2 量子力学の原理に基づいて分子の性質や反応を計算する方法
>この論文を読みたい方はこちらから
Attention Is All You Need
「Attention Is All You Need」は、2017年に発表された論文で、従来のRNNやCNN※1を用いない、注意機構のみに基づく新しい系列変換モデルを提案しています。このいわゆるTransformerは自然言語処理に革命をもたらし、AI技術全体の発展に多大な影響を与えた画期的なモデルです。
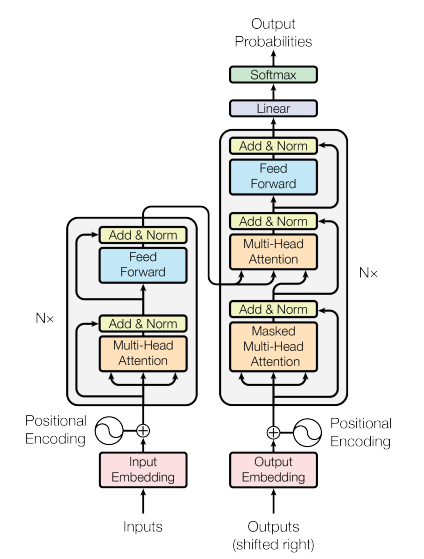
従来の逐次処理の制約を克服するため、自己注意機構を中心とした並列処理可能なアーキテクチャを開発しました。位置エンコーディングやフィードフォワードネットワークも組み合わせ、効率的な処理を実現しています。
主な成果は以下の通りです。
- 英独・英仏翻訳タスクで従来モデルを上回る性能を達成
- 学習時間の大幅な短縮
- 英語構文解析タスクでも高い汎用性を示す
TransformerはBERT※2やGPT※3などの大規模言語モデルの基盤となり、自然言語処理を超えて幅広く応用が進んでいます。その活用範囲は機械翻訳、テキスト生成、質問応答にとどまりません。音声認識・合成、画像処理、創薬など多岐にわたる分野でも大きな成果を上げつつあります。

学術界では被引用数が10万回を超え、産業界でも広く採用されています。Transformerは、自然言語処理の標準的アーキテクチャとして確固たる地位を築いているのです。
※1 畳み込みニューラルネットワーク(Convolutional Neural Network)の略称。主に画像認識タスクに用いられる深層学習モデル
※2 言語理解を目的とする大規模言語モデル
※3 言語生成を目的とする大規模言語モデル
>Attention Is All You Needを読みたい方はこちらから
A simple neural network module for relational reasoning
この研究は、既存の深層学習システムにRNを組み込むことで、関係推論タスク※1の性能を大幅に向上させました。Relation Network(RN)は、物事の関係性を推論する能力を持つ、シンプルで効果的なAIモジュールです。
従来の深層学習モデルは関係性の理解が苦手でしたが、RNはこの課題に取り組み、高い性能を示しました。
主な成果は以下の通りです。
| タスク | 結果 |
|---|---|
| 視覚的質問応答タスクCLEVR | 95.5%の全体精度を達成(人間の92.6%を上回る) |
| テキストベースの質問応答タスクbAbI | 20タスク中18タスクで95%以上の精度 |
| 複雑な物理システムの推論 | 接続推論タスク:テストセットの93%で正しく分類 カウンティングタスク:テストシーンの95%で正解 |
RNは、少ないデータでの学習(少数ショット学習)や社会問題解決のための研究にも応用されています。
※1 複数の事物や概念の間の関係性を理解し、そこから新たな知見を導き出す能力
>この論文を読みたい方はこちらから
VARIATIONAL LOSSY AUTOENCODER
この研究は、Variational Autoencoder (VAE)※1とオートレグレッシブモデル※2を組み合わせた、新しいデータ圧縮技術を提案しています。
イリヤ氏も開発に携わったこの新技術、Variational Lossy Autoencoder (VLAE)は、データの重要な特徴を効果的に抽出し、生成モデルの性能を大幅に向上させる手法です。

(a)から(c)にかけて、受容野が大きくなるにつれて、潜在コードがより大局的な構造を捉え、詳細な形状情報が少なくなっている。
従来のVAEには、データの全情報を保持できないにもかかわらず、不要な細部までエンコードしてしまう課題がありました。
VLAEはこの問題に対処するため、データの大まかな構造のみを保持し、細部の情報を意図的に捨てることで、効率的なデータ圧縮を実現しました。
主な成果は以下の通りです。
- 画像データの生成性能を大幅に向上
| タスク | 結果 |
|---|---|
| 静的二値化MNIST | 79.03 bits/dim(当時の最高性能)※3 |
| OMNIGLOT | 微調整後89.83 bits/dim(当時の最高性能と同等) |
| CIFAR10 | 2.95 bits/dim(変分学習モデル中最高性能) |
2. 効率的な情報圧縮を実現
| タスク | 結果 |
|---|---|
| 静的二値化MNIST | 平均19.2ビットで圧縮(従来のVAEは37.3ビット) |
3. 複数のデータセットで最先端の結果を達成
VLAEが提案した効率的な情報圧縮と特徴抽出の考え方は、現在の深層学習や機械学習分野、とくに表現学習※4や生成モデルの研究に影響を与えています。現在新たな手法の登場により一部では置き換えられていますが、その基本原理は依然として分野の発展に寄与し続けています。
※1 データの生成と圧縮を同時に行う機械学習モデル
※2 過去の出力を入力として使用し、時系列データを生成するモデル
※3 データの1要素あたりに必要な平均ビット数。値が小さいほど効率的な圧縮や優れたモデル性能を示す
※4 データから有用な特徴を自動的に学習する機械学習の一分野
>この論文を読みたい方はこちらから
Kolmogorov Complexity and Algorithmic Randomness
この書籍は、情報科学の基礎理論を網羅的に解説した重要な参考書です。
アルゴリズム情報理論の基本概念から重要な研究成果までを体系的に説明しています。とくに、コルモゴロフ複雑性※1とアルゴリズム的ランダム性の理論に焦点を当てています。
これらの理論は、情報の本質的な性質を理解する上で重要な役割を果たしてきました。従来の情報理論では扱いきれなかった「ランダム性」や「複雑さ」を数学的に定義し、分析することを可能にしました。
この理論の応用分野です。
- データ解析におけるランダム性の評価
- 暗号学での乱数生成評価
- 機械学習やAIにおけるデータの複雑さの測定
※1 与えられたデータを記述するのに必要な最短のプログラムの長さ。データの複雑さを表す尺度
>この書籍を読みたい方はこちらから
Relational recurrent neural networks
この研究は、時系列データにおける関係性の推論能力を向上させることを目的としています。研究で登場するリレーショナルメモリーコア(RMC)※1は、メモリ間の相互作用を強化する新しいニューラルネットワークモジュールです。RMCを用いることで、RNNの情報処理能力が大幅に向上しました。
従来のRNNモデルは、長期的な情報の関係性を捉えることが難しく、複雑なタスクの処理に課題がありました。
RMCは、マルチヘッド・ドットプロダクト・アテンション※2を活用し、この問題に取り組みました。
RMCは以下のタスクで従来モデルを上回る性能を示しました。
| タスク | 結果 |
|---|---|
| 強化学習(Mini PacMan) | RMCは677ポイント獲得し、LSTMの550ポイントを上回る |
| 言語モデリング(WikiText-103) | RMCのテストパープレキシティ※3は31.6で、LSTMの34.3を改善 |
| 最も複雑な”Program”タスク | RMCは79.0%の正確性を達成し、LSTMの66.1%を上回る |
RMCは長期依存関係の捕捉に優れた可能性が示唆されましたが、現在は大規模言語モデルの台頭により、単独での使用は限定的です。ただし、RMCの基本概念の重要性は変わりません。
※1 メモリ間の相互作用を強化するためのニューラルネットワークモジュール
※2 複数の視点から情報を捉える注意機構
※3 言語モデルの性能を測る指標。低いほど予測精度が高い
>この論文を読みたい方はこちらから
GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
この論文で、Googleの研究チームは、単一のアクセラレータのメモリ制限を超える大規模モデルの学習手法を発表しました。GPipeは大規模ニューラルネットワークの効率的な学習を可能にする画期的なライブラリです。
深層学習モデルの大規模化は性能向上に有効ですが、メモリ制限により実現が困難でした。
GPipeは、パイプライン並列処理※1とマイクロバッチ分割※2を組み合わせることで、この問題を解決しました。
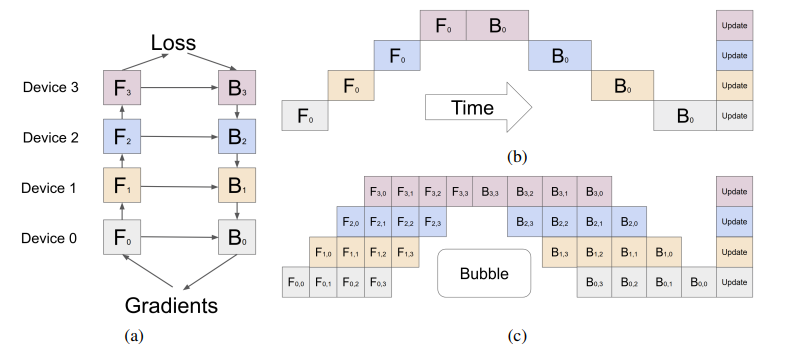
この画像は、GPipeの核心的な機能であるパイプライン並列処理とマイクロバッチ分割を視覚的に説明しています。
(a) モデルを複数のパーティションに分割し、それぞれを異なるアクセラレータに割り当てる様子
(b) 単純なモデル並列処理の非効率性
(c) GPipeによるパイプライン並列処理とマイクロバッチ分割の効率的な実行
主な成果は以下の通りです。
| タスク | 結果 |
|---|---|
| 画像分類タスク | 5.57億パラメータのAmoebaNetモデルで84.4%の精度を達成 |
| 機械翻訳タスク | 60億パラメータの多言語Transformerモデルで従来の2言語モデルを上回る性能を実現 |
GPipeの概念は後続の研究(PipeDream、WPipeなど)に影響を与え、大規模モデル学習の重要な基盤となっています。
※1 モデルを複数の部分に分割し、並列に処理する手法
※2 バッチを小さなサブバッチに分割し、順番に処理する手法
>この論文を読みたい方はこちらから
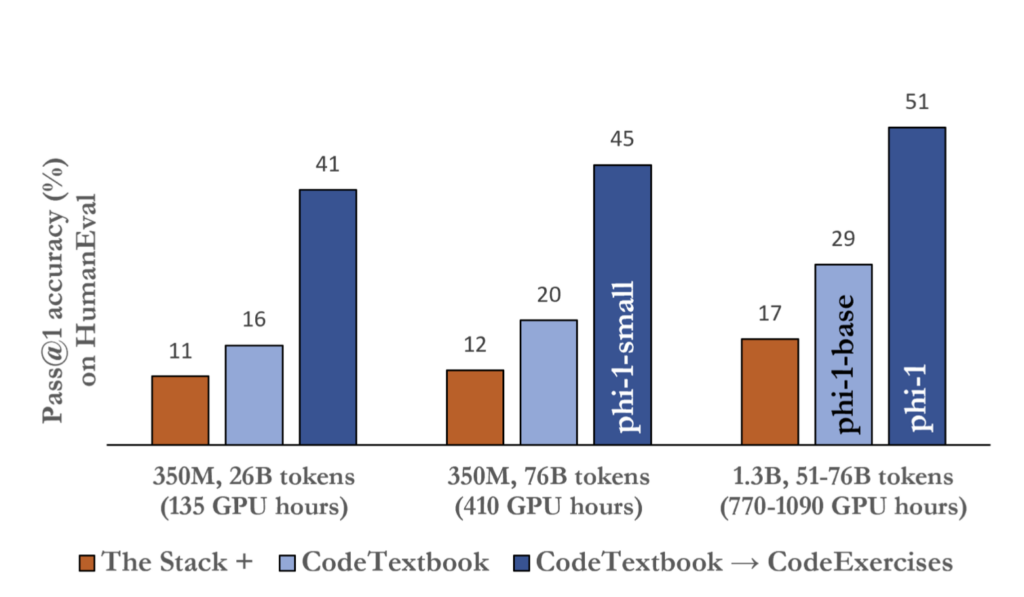
Scaling Laws for Neural Language Models
本研究は、さまざまなサイズのモデルを異なる量のデータで訓練し、性能を比較分析しています。言語モデルの性能は、モデルサイズ、データ量、計算量の適切な組み合わせで効率的に向上します。
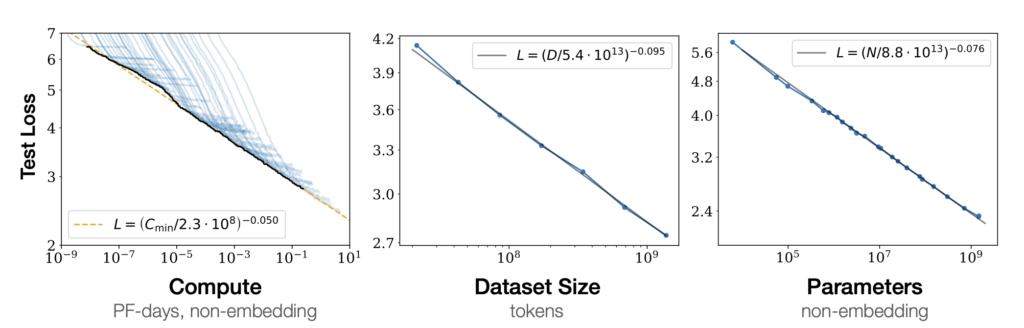
主な知見は以下の通りです。
- モデルサイズ、データ量、計算量が性能とべき乗則※1の関係にある
- 大規模モデルは少ないデータでも高性能を発揮(高いサンプル効率)
- モデルサイズを大きくすると、必要なデータ量はモデルサイズの0.74乗に比例して増加
- 性能はスケールに強く依存し、アーキテクチャの詳細への依存は少ない
この研究は大規模言語モデル開発の指針となっています。最新の発見では、アーキテクチャの影響も重要であることや、特定のモデルサイズを超えると新しい能力が突然出現することが示されています。
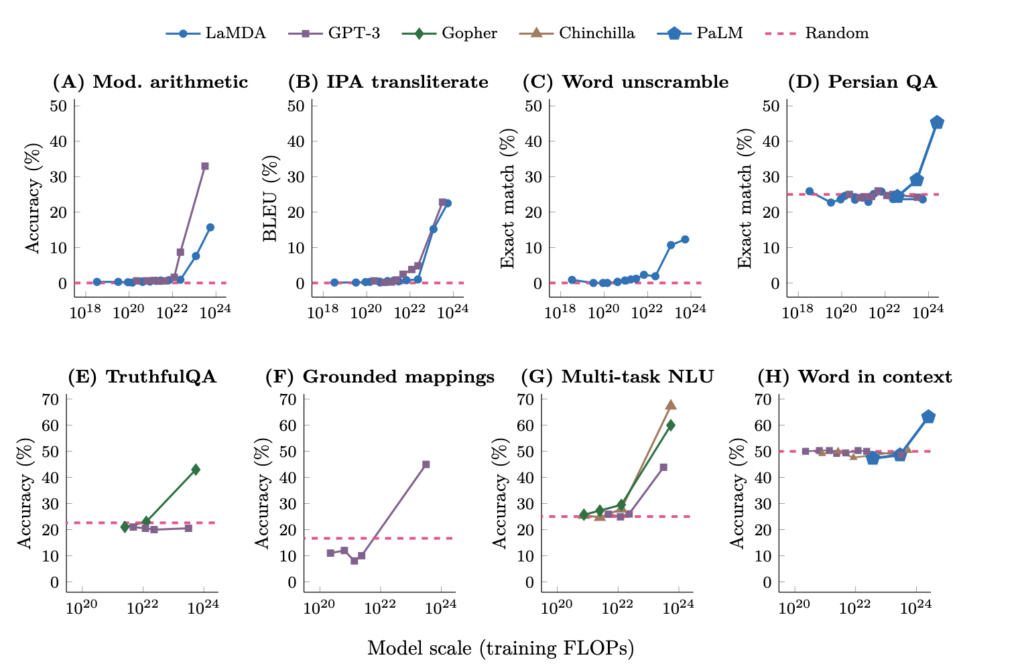
一方で、高品質な学習データを使用すれば、小規模モデルでも高性能が達成できることが分かってきました。
※1 ある量が別の量のべき乗に比例する関係(例:y = x^n)
>Scaling Laws for Neural Language Modelsを読みたい方はこちらから
The Annotated Transformer v.2022
「The Annotated Transformer」は「Transformer」を詳しく解説する教育資料です。
この資料は、2017年の論文「Attention is All You Need」で発表されたTransformerモデルを解説しています。従来の自然言語処理モデルの課題を解決したTransformerの構造と仕組みを、図や例を使って分かりやすく説明しています。

主な内容は以下の通りです。
- Transformerの各要素(エンコーダ、デコーダなど)の詳細な解説
- PyTorch※1を使った実装例
- AIモデルの訓練方法や性能向上のコツ
AI技術の理解と普及に大きく貢献した重要な資料といえるでしょう。
※1 機械学習のためのプログラミングツール
>この論文を読みたい方はこちらから
イリヤ・サツケバー氏の論文リストを読むメリット
イリヤ・サツケバー氏の論文リストを読むことで、以下の2つのメリットがあります。
- AI知識を効率よく習得できる
- AI進化の流れをつかんで先を読める
それぞれのメリットについて、詳しく解説します。
AI知識を効率よく習得できる
イリヤ・サツケバー氏が選んだ論文リストを読むことで、AIの知識を効率よく身につけることができます。
この論文リストには、AIの重要な進展が凝縮されているため、最新トレンドを押さえつつ、基礎から応用まで幅広く学習できるのが特徴です。
世界的に人気の高いオンライン講座「Deep Learning Specialization」では、これらの論文の多くが教材として活用されています。このコースは100万人以上が受講し、高評価です。
AI知識を身につけると仕事の幅が広がり、技術的な会話にも自信を持てるようになります。AIプロジェクトで活躍すれば評価が上がり、昇進のチャンスも増えるかもしれません。
今学ぶことで、将来の自分に大きな利益をもたらすことができるでしょう。
AI進化の流れをつかんで先を読める
AIの歴史的な進化を理解すると、将来のトレンドを予測し、ビジネス戦略に活かせます。AIの急速な進歩により、最新動向の把握が困難になっていますが、先見性を持つことで大きな優位性を得られます。
たとえば、OpenAIのGPTの進化に注目していたMicrosoftは、2019年に10億ドルを投資し、2020年にGPT-3の独占ライセンスを獲得しました。
これにより、Azure OpenAI Service上で、GPTシリーズをいち早く展開できました。その結果、2021年から2024年にかけて株価が約80%上昇し、2024年1月時点で時価総額が2.9兆ドルを超える成長を遂げたのです。
このような先見性は、中長期的な戦略立案や投資判断の質を向上させ、競争優位性の獲得につながります。AIトレンドを理解し、先を読む力を磨くことで、ビジネスチャンスを逃さず、企業価値を高められます。
論文の理解を深めるためのおすすめの教材・資格
今回解説した論文の理解を助けるためのおすすめ教材と資格を紹介します。
- 書籍
- オンライン学習プラットフォーム
- 資格
それぞれ詳しく解説します。
書籍
AIや機械学習に関する書籍には、今回紹介した専門用語や技術の解説がより詳しく書かれているため、理解を深めてくれるでしょう。
とくに以下の書籍は、AIと機械学習の理解を深めるのに役立ちます。
・「深層学習」(Ian Goodfellow, Yoshua Bengio, Aaron Courville著)

- 深層学習の理論と実践を包括的にカバー
- 初心者から上級者まで役立つ内容
・「強化学習」(森村哲郎著)

- 強化学習の理論的基礎を深く理解するのに適した良書
・「先読み!IT×ビジネス講座 ChatGPT 対話型AIが生み出す未来 」(古川渉一 , 酒井麻里子 著)

- ChatGPTの基本から活用法まで、対話形式で分かりやすく解説
- AI技術の専門家による解説で、ChatGPTの仕組みや可能性、ビジネス活用事例を短時間で理解できる
オンライン学習プラットフォーム
AIや機械学習を体系的に学ぶには、以下のプラットフォームが有効です。
| プラットフォーム | 説明 |
|---|---|
| Coursera | ・世界トップクラスの大学や企業が提供する多彩なコースを受講可能 ・スタンフォード大学のAndrew Ng教授によるAI・機械学習講座など、充実したラインナップ。 ご登録はこちらから |
| edX | ・MITやハーバード大学などの名門校が提供する高品質な講座を無料で受講可能 ・AIや機械学習に加え、経済学やファイナンスなどの応用分野も学べるのが魅力 ご登録はこちらから |
| Udacity | ・GoogleやAmazonなど100社以上のテクノロジー企業と提携し、実践的なスキルが身につく講座を提供 ・「Nanodegree」と呼ばれる修了証プログラムが特徴で、AIエンジニアなど特定の職種に特化したカリキュラムを受講可能 ご登録はこちらから |
ただし、注意点は以下のとおりです。
- これらのプラットフォームのコースは主に英語で提供されています。
- 日本語のコンテンツは限られています。
- コースの質にはばらつきがあるため、レビューを確認してから受講することをおすすめします。
AIや機械学習の知識を時間をかけて体系的に学びたい方は、オンライン学習プラットフォームの利用を検討してみてください。
資格
日本ディープラーニング協会(JDLA)やGUGA(一般社団法人生成AI活用普及協会)が提供する以下の資格試験が注目を集めています。
| 資格名 | 説明 |
|---|---|
| G検定 | ・ディープラーニングの基礎知識とビジネスでの活用方法を問う試験 ・AI時代の基礎的な知識を証明する資格として認知度が高まっている お申込みはこちら |
| E資格 | ・ディープラーニングの理論と実装能力を評価する技術的な試験 ・エンジニアのスキルアップや転職に有利 お申込みはこちら |
| Generative AI Test | ・生成AI技術に特化した比較的新しい試験 ・この分野の基礎知識と適切な活用能力を評価 お申込みはこちら |
| 生成AIパスポート | • 生成AIの基礎知識から実践的な活用方法まで、幅広く学べる初心者向けの試験 • 企業でのコンプライアンスや倫理的リスクなど、実務に即した内容を含む点が特徴 お申込みはこちら |
これらの資格は、AIへの理解を深め、キャリアアップの一助となります。
ただし、取得後も継続的な学習も重要です。AI分野は技術の進歩が速いため、最新の動向にも常に注目する必要があります。
最先端のAI研究を理解し、キャリアアップにつなげよう!
本記事では、イリヤ・サツケバー氏が厳選した論文リストを紹介し、各論文の概要を解説しました。これらの論文は、AIの基礎理論から応用まで幅広く扱っている優れた情報源です。
ResNetやTransformerなどの革新的なモデルは、学習の効率化や精度の向上を実現し、AIの発展に大きく寄与してきました。これらの論文を理解することで、最新のAI技術への洞察を深められます。
また、論文の理解を助けるための教材や資格もお勧めです。
- AI・機械学習のスキル向上に役立つリソース
- Courseraなどのオンライン学習プラットフォーム
- G検定・生成AIパスポートなどの専門資格
忙しい中でも時間を捻出し、着実にスキルアップを図ることが、これからのキャリア形成には欠かせません。
イリヤ氏の論文リストを道標に、AIの基礎から応用までを学び、自身のキャリアに活かしていきましょう。AI技術への理解を深めることで、新たな可能性が開けるはずです。
「質の高いプロンプトでAIの能力をもっと引き出したい」「プロンプトのコツを知りたい」という方に向けて、この記事では「【超時短】プロンプト150選」を用意しています。
この資料ではジャンル別に150個のプロンプトを紹介しています。また、プロンプトエンジニアリングのコツも紹介しており、実践的な資料が欲しい方にも適しています。
無料で受け取れますが、期間限定で予告なく配布を終了することがありますので、今のうちに受け取ってプロンプトをマスターしましょう!
30秒で簡単受取!
無料で今すぐもらう













30秒で簡単受取!
無料で今すぐもらう