share



【フロントランナーに聞く:04】「誰でも使える生成AIツール」は、なぜ簡単で精巧なのか。「AIマサルくん」の舞台裏を解説

SHIFT AI TIMES『AIラボへようこそ』では、各分野の最先端で活躍するキーパーソンのインタビューを通じて、AIを身近に感じてもらう記事を連載しています。2025年3月12日には、「AIマサルくん」をはじめとした生成AIアプリによって、地方自治体のDXを推進する元国会議員の村井宗明氏にインタビューしました。
参考記事:“企業のAI導入の請負人”が答える「なぜあなたの会社にはAIが根付かないのか?
本稿は、前編に続き、「誰でも使える生成AIツール」の裏側を解説しつつ、次世代の生成AIアプリである「AIエージェント」が切り開く未来も展望します。
目次
Transformerによる自然言語処理の革命
人間が話す言語を理解するAIに関する研究開発は、自然言語処理と呼ばれています。この分野について、村井氏は形態素解析からLLMに転回した、とインタビューで述べていました。この転回は、自然言語処理だけでなくAI研究の歴史において”革命”とも言える「Transformer」によって引き起こされました。以下では、Transformerの革新性について、自然言語処理の歴史を振り返りながら解説します。
ChatGPT登場以前の2010年代、AIが文章の意味を理解する技法として主流だったのが、形態素解析でした。この技法は、文章を名詞や動詞といった品詞に分解したうえで、構造にもとづいて文章の意味を分析する、というものです。

形態素解析には、文法的にあいまいな文章や、複雑な修飾関係がある文章の意味理解が苦手という欠点がありました。
2017年6月、Googleの研究チームは「必要なすべてはAttention」と題した論文を発表しました。この論文で論じられた技法「Transformer(トランスフォーマー)」こそ、今日の生成AI時代の礎となるものでした。形態素解析をはじめとする以前の技法が文章を品詞ごとに分解してそれぞれを処理するのに対して、Transformerは文章の重要な部分に注目して処理するアプローチを採用していました。このアプローチは、「Attention(注意)」と呼ばれます。
Transformerは、Attentionを採用することで、文法的にあいまいだったり修飾関係が複雑だったりしても、文章の意味を適切に理解できるようになりました。
Attentionの採用による恩恵は、文章理解能力の向上だけではありませんでした。重要な部分に注目するAttentionは以前の技法に比べて計算効率が向上したため、大量のデータを学習できるようになったのです。このようにして大規模化されるようになった自然言語処理AIが、LLM(Large Language Model:大規模言語モデル)です。
ChatGPTをはじめとする現在、主流の生成AIは、Transformerを活用したLLMに分類されます。ChatGPTが世界に与えた影響を考えると、AIの歴史は「Transformer以前」と「Transformer以後」で激変した、と言っても過言ではないでしょう。
LLMを縦横に駆使するアーキテクチャ
村井氏は自身が開発した生成AIアプリを「LLMを直列と並列に使うアプリ」と説明していました。以下では、架空の申請書生成AIアプリの仕組みを図解した画像(こうした画像は「アーキテクチャ図」と呼ばれる)を参照しながら、同氏の生成AIアプリ開発における設計思想とノウハウを解説します。
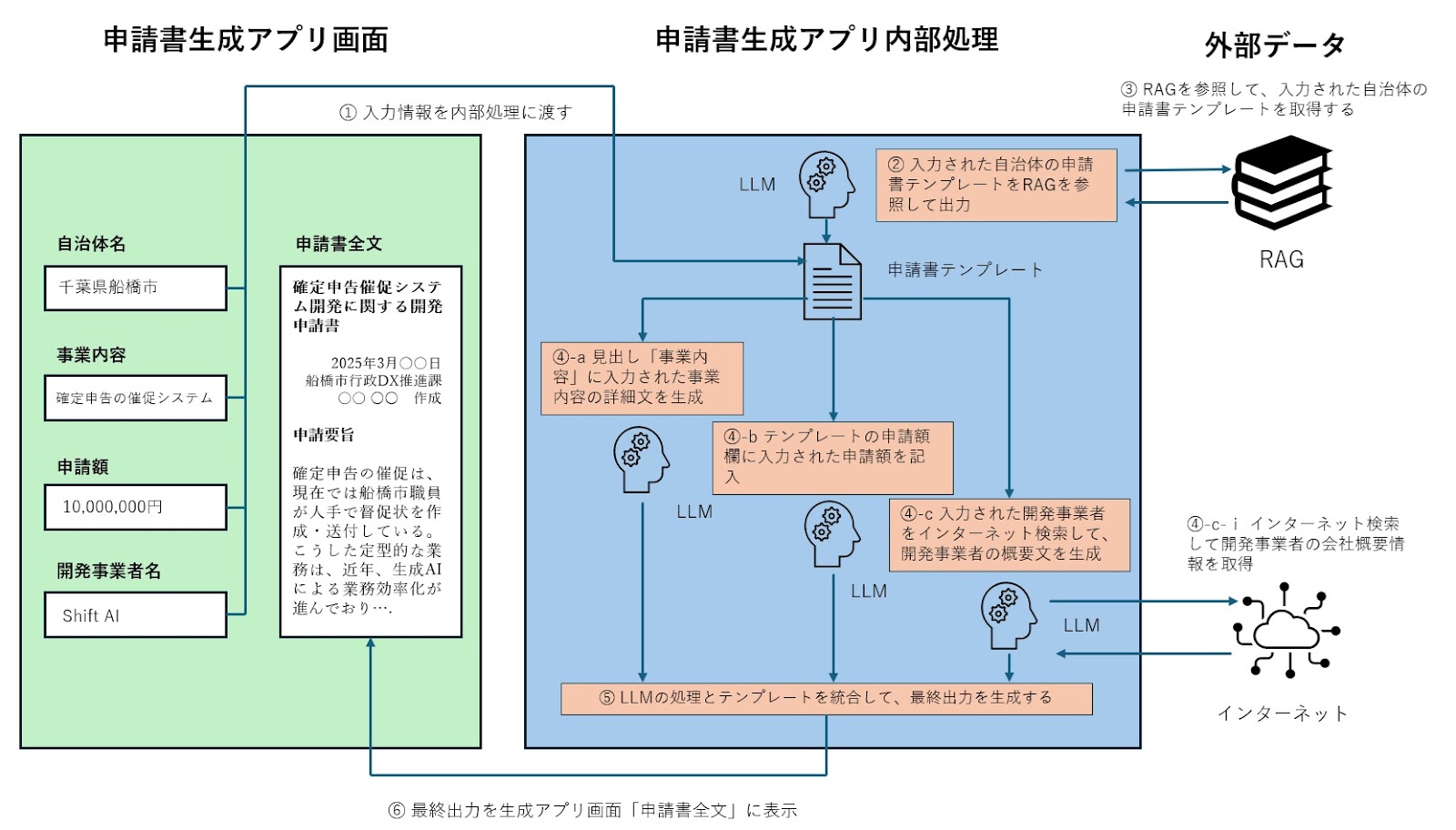
以上にアーキテクチャ図を示した申請書アプリでは、以下のような処理が順を追って実行されます。
- ユーザーがアプリ画面から入力された情報は、アプリの内部処理に渡される。
- LLMは、入力情報にもとづいて事前設定された「RAGを参照して申請書テンプレートを取得せよ」というプロンプトを実行する。
- 取得した申請書テンプレートに挿入する文章を生成するために、複数のLLMが事前設定されたプロンプトを実行する。(複数のLLMが同時に走ることから”並列”と言われる)
- 以上の処理で生成された文章を、申請書テンプレートに挿入して統合する。
- 生成文章を挿入した申請書をアプリ画面の「申請書全文」欄に表示する。
以上のような順次的処理が、「LLMの直列」処理に相当します。この処理は決められた順番で実行する必要があるので、「直列」と呼ばれるのです。しかしながら、直列的処理だけでは、処理に時間がかかってしまいます。複数のLLMを同時に実行できる処理がある場合には、LLMを並行して実行して処理時間を短縮します。
LLMがさまざまな内容の文章を生成できるのは、インターネットで公開されている大量の文章を学習しているからです。その一方で、企業が非公開としている文書は学習していません。実際の業務で参考にされるのは、こうしたLLMが学習していない文書です。こうした問題を解決するために考案された技法が、LLMが事前学習していない情報を参照するRAG(Retrieval-Augmented Generation:検索拡張生成)です。
村井氏によると、生成AIアプリ内で実行されるLLMは、実行するタスクに応じて使い分けられています。例えば、インターネット検索を活用して実行する場合は、ChatGPTよりもGoogleが開発したGeminiのほうがよい結果が得られます。また、処理時間を短縮したい場合は、ChatGPTのベースとなるLLMの一種であるGPT-4o miniの使用が推奨されます。
以上のような村井氏が提唱する「直列-並列型LLMアプリ」アーキテクチャをベースにして、業務効率化したい業務に合わせてアプリ画面を設計して、遂行したい業務の実行をLLMの処理に置き換えれば、フォーム入力だけでさまざまな業務を遂行できるアプリが開発できるのです。
2030年には日本だけでも最大900万体のAIエージェントが働く未来
村井氏のインタビューでは、”次世代の生成AI”としてその動向が注目されているAIエージェントについても尋ねました。AIエージェントとは、SNSへの投稿やインターネットショッピングといったタスク(仕事)を実行する生成AIのことです。
AIエージェントは、その活用範囲の広さを鑑みれば、既存の生成AIを大きく凌駕する影響力と経済効果が期待できます。
AIエージェント開発競争は、2024年後半より始まっています。例えばGoogleは2024年12月、同社の最新生成AI「Gemini 2.0」を発表した際、AIエージェント開発としてARグラスへの実装を想定した「Project Astra」をはじめとする3つのプロジェクトに取り組んでいることを明らかにしました。同社の最大のライバルであるOpenAIは2025年1月23日、同社製AIエージェント「Operator」を発表し、このAIがオンラインショッピングする様子を収録した動画も公開しました。
野村総合研究所は2025年2月17日、今後のAIの普及についてまとめたレポートを発表しました。このレポートでは、AIエージェントの普及予測が論じられています。その予測によれば、5年後の2030年代には日本企業における生成AI普及率は50%を超え、生成AIアプリの主流はAIエージェントになっていると考えられます。
2030年には日本企業が340万社あると推計され、生成AIアプリ導入企業が1社当たり1~5体のAIエージェントを活用していると想定して、前述の普及率を合わせて計算すると、同年には常時200~900万体程度のAIエージェントが稼働していることになります。一般消費者向けのAIエージェントも加味すれば、日本中でおびただしい数のAIエージェントが稼働している時代が到来することでしょう。
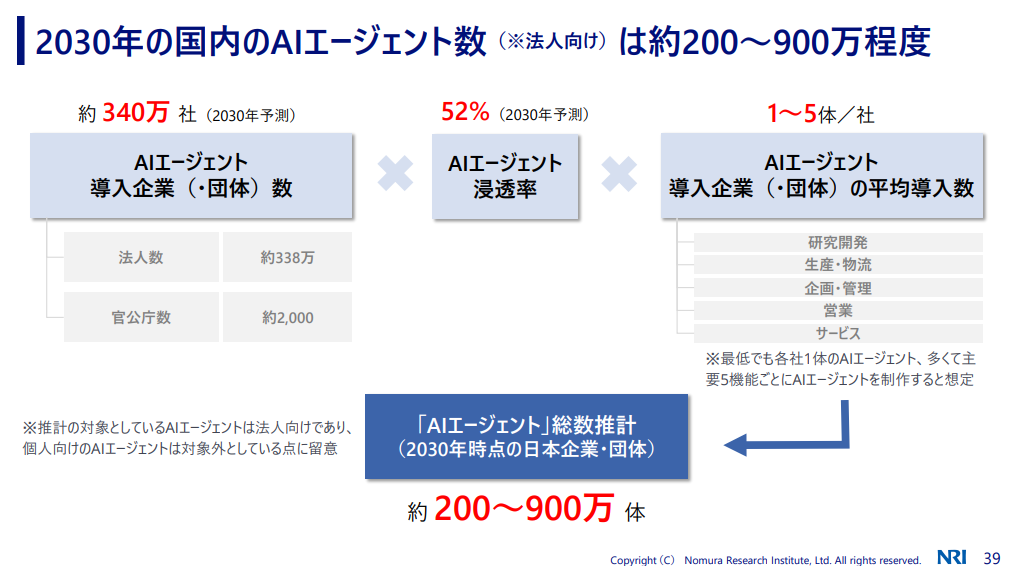
2030年における企業活用AIエージェント数の試算
(画像出典)https://www.nri.com/jp/knowledge/report/files/000042559.pdf
このようにAIエージェント時代の到来が予感されていますが、その普及において重要となるのは村井氏が提唱する「マジョリティ層が使いやすい」アプリの設計思想ではないでしょうか。簡単な指示だけで難しいタスクを実行するAIエージェントが開発されることで、多くの企業がそうしたアプリの実用性を認めて、導入を決断することでしょう。
(記事執筆:吉本幸記)












